








🐇明明跟你说过:个人主页
🏅个人专栏:《深度探秘:AI界的007》 🏅
🔖行路有良友,便是天堂🔖
目录
4、API 层(API & Integration Layer)
一、引言
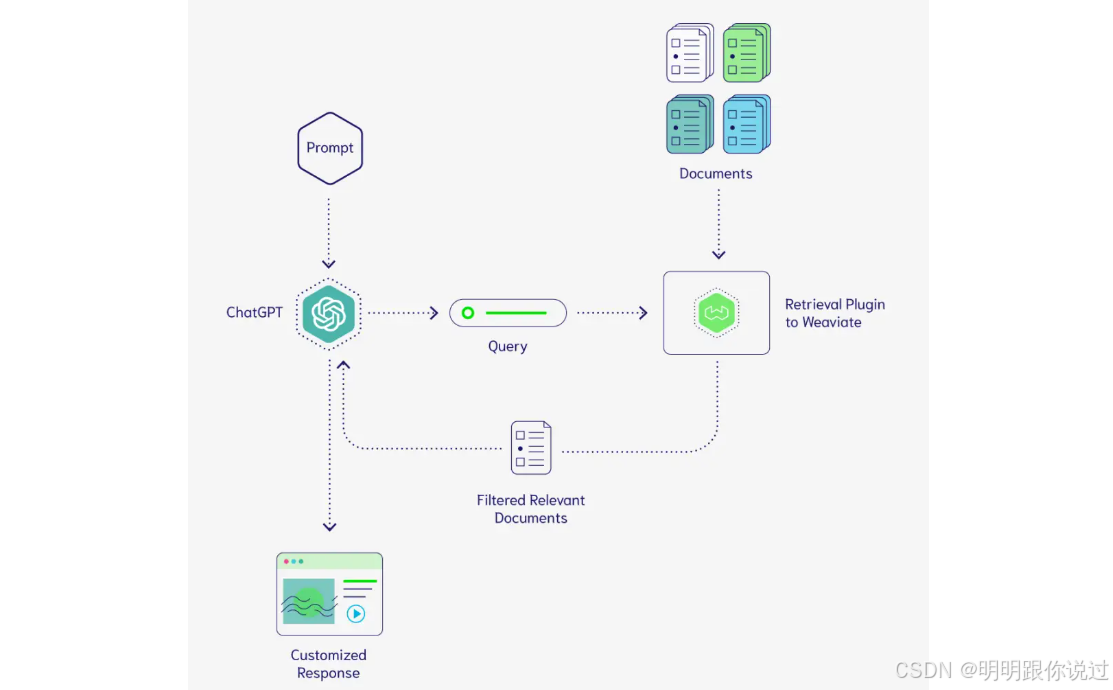
1、什么是Weaviate
Weaviate 是一个向量数据库,它的主要作用是存储和搜索文本、图片、音频等数据的向量表示。
想象你有一个大图书馆📚,但里面的书没有分类、没有索引,想找某一本书只能一本一本翻,效率非常低。Weaviate 就像一个超级智能图书管理员,它会把每本书的内容转换成数字(向量),然后存起来,想要搜索时,输入一句话,它就能迅速找到最相似的内容!💡

2、Weaviate 能做什么?
1️⃣ 智能搜索:
- 🔍 你输入 "一部关于人工智能的科幻电影",它能立刻找到《黑客帝国》《她》等类似的电影。
- 📨 你输入 "中奖"、"免费" 之类的词,它能检索到相关的垃圾短信。
2️⃣ 语义匹配:
- Weaviate 不仅能匹配完全一样的文本,还能理解意思相近的内容。
- 比如,你搜索 "如何提高编程能力",它能找到 "提升代码技能的 10 个方法" 之类的文章。
3️⃣ 多模态数据(不仅限于文本):
- 图片:你上传一张猫的照片,它能找到数据库里所有相似的猫照片。
- 音频:你放一段音乐,它能找到类似风格的歌曲。
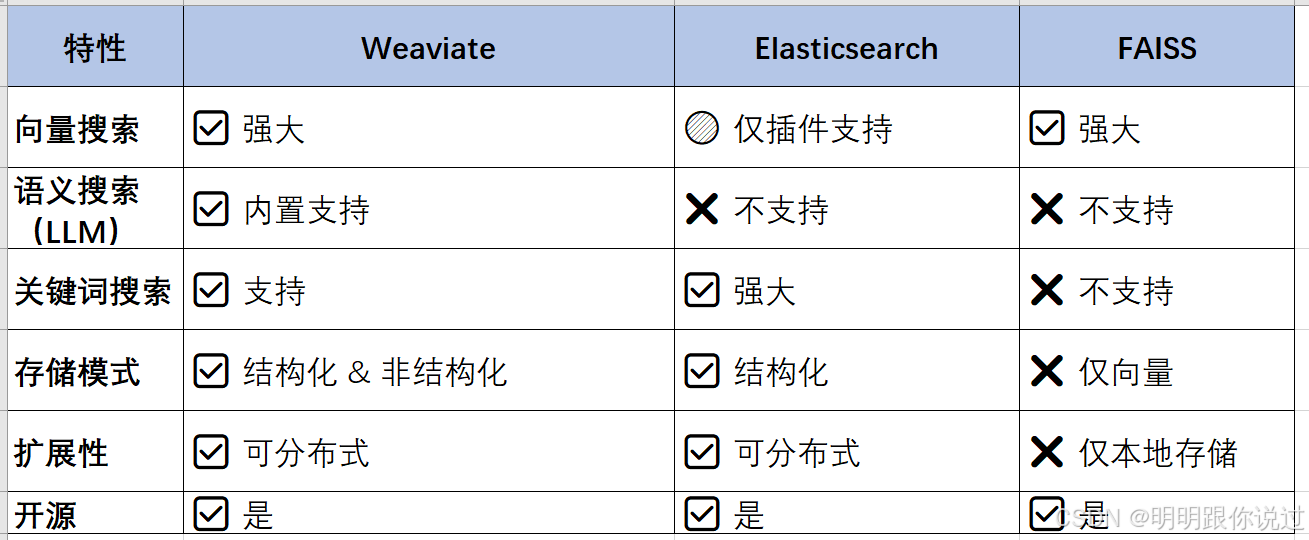
3、Weaviate 和传统数据库的区别
二、Weaviate数据库概述
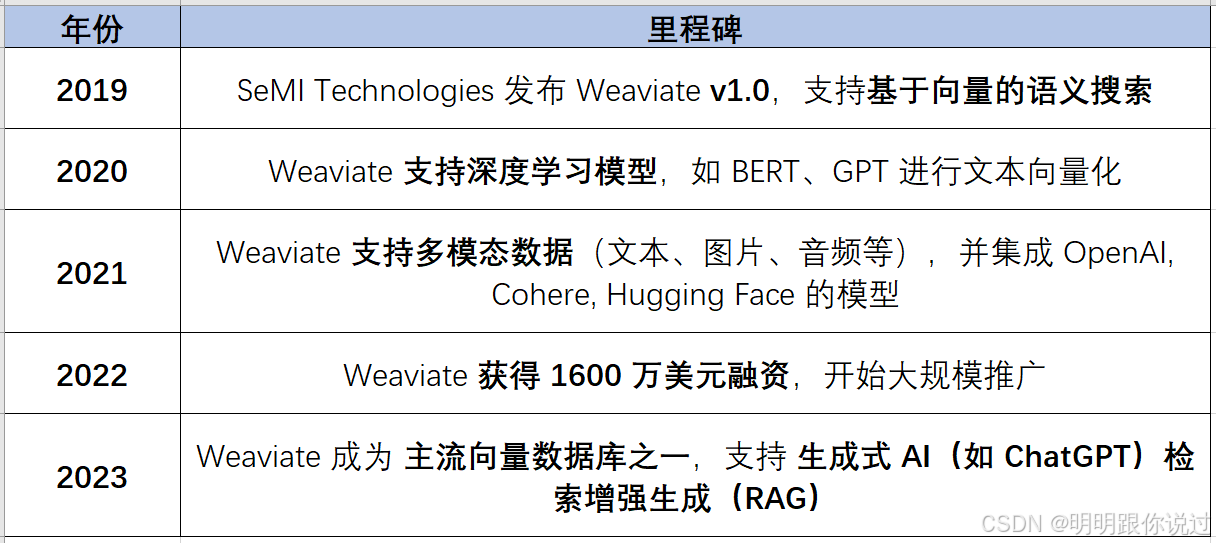
1、Weaviate的起源
Weaviate 是由荷兰公司 SeMI Technologies 开发的一个开源向量数据库,最早发布于 2019 年。它的诞生源于一个核心问题:如何让 AI 更高效地存储和搜索大规模的非结构化数据(文本、图片、音频等)?
2、Weaviate 诞生的背景
在 2010 年代,机器学习和自然语言处理(NLP) 迅速发展,特别是BERT、GPT 等大规模预训练模型的出现,让 AI 在语义理解方面更强大。但问题是:
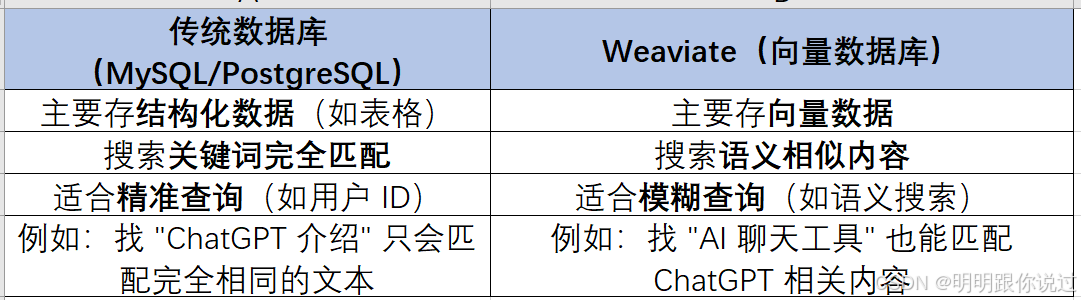
- 传统数据库(如 MySQL、PostgreSQL)只能存结构化数据,对 AI 处理的文本、图片等非结构化数据支持很差。
- 关键词搜索(如 Elasticsearch)无法理解语义,比如:
- 我们搜索 "AI 机器人",但数据库里只有 "人工智能助手",普通搜索引擎不会认为它们是一样的。
- 向量化搜索(基于神经网络的语义搜索)能解决这个问题,但当时没有高效、易用的向量数据库。
为了解决这个问题,SeMI Technologies 在 2019 年发布了 Weaviate,它是一种专门为 AI 设计的数据库,可以存储、索引和搜索向量化数据。
3、为什么叫 "Weaviate"?
Weaviate 这个名字来源于 “Weave(编织)+ Vi(可视化)+ Ate(智能)” 的组合,寓意:
- Weave(编织):像一张智能网络一样,把数据和 AI 连接起来。
- Vi(可视化):它不仅能存储数据,还能支持数据可视化、语义搜索等功能。
- Ate(智能):Weaviate 结合 AI 和机器学习,帮助用户更智能地搜索和管理数据。
4、Weaviate核心功能
✅ 1. 向量存储(Vector Storage)
- Weaviate 支持存储文本、图片、音频、视频等数据的向量化表示。
- 可以使用预训练模型(如 OpenAI, Hugging Face, Cohere, SBERT)自动向量化数据,也支持自定义向量。
- 适用于语义搜索、推荐系统、异常检测等 AI 应用。
✅ 2. 语义搜索(Semantic Search)
- 基于向量相似性(最近邻搜索, ANN),比传统数据库的关键词搜索更智能。
- 查询方式:
- 语义搜索("找到与这个文本最相似的内容")
- Hybrid Search(结合传统关键词 + 向量搜索)
- 跨模态搜索(同时支持文本、图片等)
- 适用于智能问答、客户支持、知识管理等场景。
✅ 3. 可扩展的存储与检索
- Weaviate 支持亿级数据存储,并且可以分布式部署,适用于大规模 AI 应用。
- HNSW(Hierarchical Navigable Small World)索引算法,提供高效的向量检索,比 brute-force 计算快很多。
- GraphQL & REST API 查询,简单易用。
✅ 4. 自动模式(Schema-Free 或 Schema-Based)
- Schema-Free:可以直接存储 JSON 数据,无需预定义模式,适合灵活的 AI 数据存储。
- Schema-Based:支持定义数据结构,适用于严格的企业级应用。
✅ 5. 多模态数据支持
- Weaviate 不仅能存文本,还能存储和搜索图片、音频、视频的向量化表示。
- 适用于跨模态搜索(Multimodal Search),比如:
- 上传一张图片,搜索相似的文本描述。
- 用语音输入查询,找到相关的文档或图片。
5、主要特性
🔹 1. 轻量级 & 易部署
- 单机部署(Docker / Kubernetes)💻
- 云端版本(Weaviate Cloud) ☁️
- 可扩展集群(分布式架构) 🏗️
🔹 2. 开源 & 高性能
- 完全开源(Apache 2.0 许可证),无需付费
- 使用 HNSW(Hierarchical Navigable Small World) 提供超快的向量检索(适用于海量数据)
🔹 3. 多种 API 兼容
- RESTful API
- GraphQL
- Python & Go SDK
- 支持 LangChain / LlamaIndex
🔹 4. 与 LLM(大语言模型)无缝集成
- 支持 OpenAI, Hugging Face, Cohere 的模型,自动向量化数据
- 适用于RAG(检索增强生成),让 ChatGPT 能查询自己的知识库
三、架构解析
1、存储层(Storage Layer)
🔹 作用:负责存储原始数据(文档、文本、图片、元数据等)和向量数据。
🔹 组件:
- 对象存储(Object Storage):
- Weaviate 可以存储 JSON 格式的对象,支持结构化和非结构化数据。
- 数据存储方式类似 NoSQL,每个对象可带有元数据字段。
- 向量存储(Vector Storage):
- Weaviate 默认使用 SQLite / LMDB 进行数据持久化。
- 也支持连接 外部对象存储(S3、MinIO)。
- 多模态支持(Multimodal Storage):
- 存储文本、图片、音频、视频等数据,并支持向量化。
✅ 特点:
- 支持结构化和非结构化数据
- 可持久化存储到磁盘
- 支持外部对象存储(S3/MinIO)
- 可搭配 MySQL / PostgreSQL 进行扩展

2、索引层(Indexing Layer)
🔹 作用:负责高效索引管理,加速向量搜索。
🔹 核心技术:
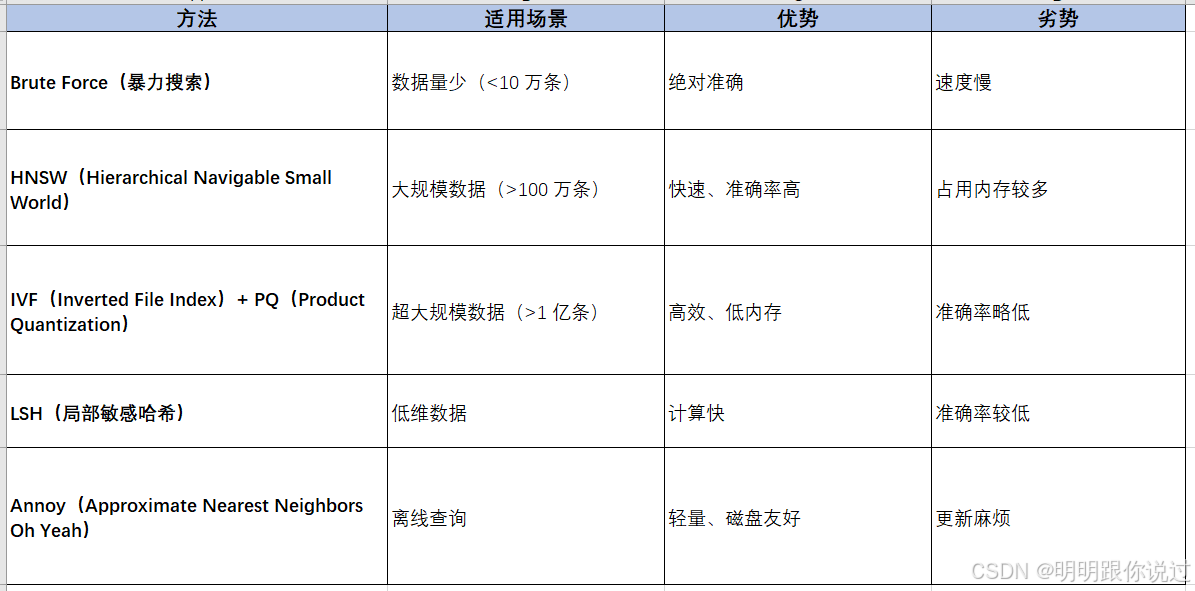
✅ 1. HNSW(Hierarchical Navigable Small World)索引
- HNSW 是 Weaviate 默认的向量索引,提供近似最近邻搜索(ANN)。
- 比传统 brute-force(暴力搜索)快 10~100 倍。
- 适用于大规模数据集(可扩展至亿级数据)。
✅ 2. 关键词索引(Lexical Indexing)
- Weaviate 结合了传统倒排索引(类似 Elasticsearch)和向量索引。
- 支持 Hybrid Search(关键词 + 向量搜索结合)。
✅ 3. 多模态索引
- 可以索引文本、图片、音频、视频的向量,适用于跨模态检索。
✅ 特点:
- HNSW 提供高效向量检索
- 支持 Hybrid Search(关键词 + 向量检索)
- 支持跨模态索引
- 支持自定义索引字段
3、查询层(Query Layer)
🔹 作用:负责接收查询请求、执行检索、返回匹配结果。
🔹 主要查询方式:
✅ 1. 语义搜索(Semantic Search)
- 基于向量相似度,支持 最近邻搜索(k-NN / ANN)。
- 适用于AI 问答、智能推荐、语义搜索等场景。
✅ 2. Hybrid Search(混合搜索)
- 结合 关键词搜索(Lexical Search)+ 向量搜索(Vector Search)。
- 适用于需要匹配关键词 & 语义的查询(例如企业搜索)。
✅ 3. 过滤搜索(Filter & Faceted Search)
- Weaviate 支持按属性筛选数据(类似 SQL 的
WHERE条件)。 - 可以在向量搜索的基础上再筛选(Metadata Filtering)。
✅ 特点:
- 支持 GraphQL 查询
- 支持 REST API 查询
- 支持向量搜索、关键词搜索、混合搜索
- 支持按属性筛选(Filter)
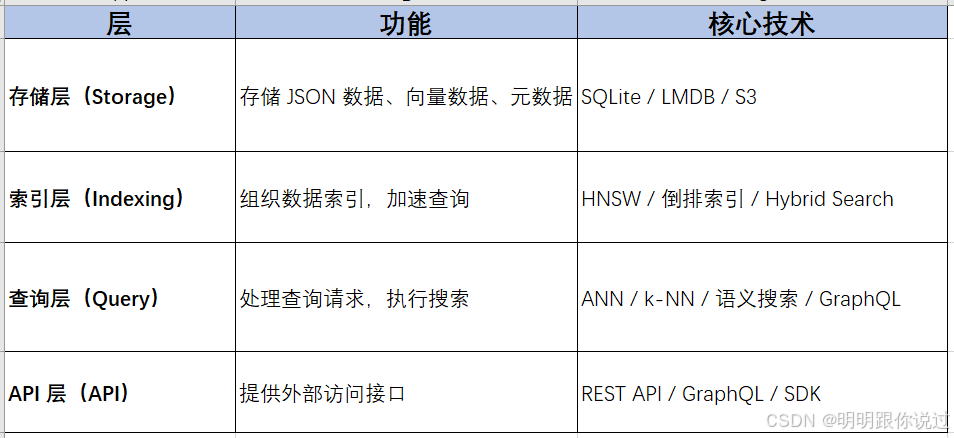
4、API 层(API & Integration Layer)
🔹 作用:提供REST API / GraphQL API 供外部应用访问。
🔹 主要 API:
✅ 1. REST API
- 适用于标准 HTTP 请求。
- 允许存储、查询、删除数据。
✅ 2. GraphQL API
- Weaviate 原生支持 GraphQL,可用于复杂查询。
- 适用于AI 搜索、知识库管理等应用。
✅ 3. SDK & 生态集成
- 官方 SDK:
- Python
- Go
- JavaScript
- LLM & AI 框架集成:
- LangChain(RAG 应用)
- LlamaIndex(索引管理)
- Hugging Face / OpenAI API(自动向量化)
- Stable Diffusion / CLIP(多模态搜索)
四、工作原理
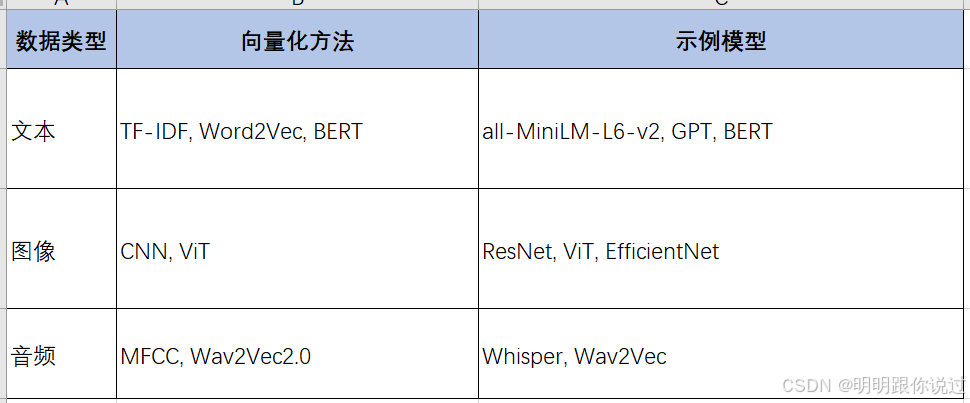
1、数据向量化过程
数据向量化就是把文本、图片、音频等信息转换成计算机可以理解的“数字表示”,也就是 “向量”(一个包含一串数字的列表)。这些向量可以用来计算相似性、分类、搜索等操作。
1.1、文本向量化
👉 为什么要向量化?
计算机不能直接理解“你好”或“hello”,但可以理解 数字,所以我们要把文字转换成向量。
👉 向量化的方式
- 词袋模型(Bag of Words, BoW):统计每个单词出现的次数,但不考虑语序。例如:
- "猫 喜欢 鱼" →
[1, 1, 1, 0, 0] - "狗 不 喜欢 鱼" →
[0, 1, 1, 1, 1]
- "猫 喜欢 鱼" →
- TF-IDF(词频-逆文档频率):不仅统计词频,还考虑词的重要性。
- Word2Vec / FastText / GloVe:把每个单词变成一个固定长度的向量,比如
你好 → [0.2, 0.5, -0.1, ...]。 - Transformer 模型(BERT、GPT、Sentence-BERT):对整句话进行编码,得到一个上下文相关的向量,比如
这是一条短信 → [0.3, -0.2, 0.8, ...]。
1.2、图像向量化
👉 为什么要向量化?
计算机不能直接理解“猫”或“狗”的图片,它只能看到像素值(RGB 颜色值),所以要把图片转换成固定大小的向量,方便分类和搜索。
👉 向量化的方式
- 传统方法(SIFT、HOG、SURF):手工提取特征,如边缘、形状等。
- 深度学习(CNN:卷积神经网络):使用 ResNet、EfficientNet、ViT 等模型,把整个图片编码成一个高维向量。
1.3、音频向量化
👉 为什么要向量化?
计算机只能处理数字信号,所以要把音频转换成数字向量,方便进行语音识别、音频分类等任务。
👉 向量化的方式
- MFCC(梅尔频率倒谱系数):提取音频的频谱特征,常用于语音识别。
- VGGish / Wav2Vec2.0 / Whisper:使用深度学习模型,将音频转换成向量。
2、向量索引与搜索机制
2.1、什么是向量索引?
想象你有 100 万条短信或图片的向量,每个向量有 768 维(比如 BERT 生成的文本向量)。如果想找到 与某条新短信最相似的短信,直接遍历 100 万条数据进行计算会 非常慢。
💡 向量索引的作用:
- 把所有向量 组织成一种高效的数据结构,加快搜索速度。
- 让查找相似向量的过程 尽量少计算,提高查询效率。
向量索引就像 高速公路的收费站,帮你快速找到正确的路,而不是盲目遍历所有可能的路径。
2.2、向量搜索的核心步骤
1️⃣ 数据向量化 📌
- 文本 → 用 BERT、Word2Vec 把文本转成 768 维向量。
- 图片 → 用 ResNet/Vision Transformer 把图片转成 2048 维向量。
- 音频 → 用 Wav2Vec2.0 把语音转成 512 维向量。
2️⃣ 建立索引 🏗️
- 选择合适的索引算法,比如 HNSW 或 IVF-PQ。
- 把向量存入索引结构,组织成 高效的查找方式。
3️⃣ 执行搜索 🔍
- 计算 新向量 和 索引中的向量 的相似度(比如余弦相似度、欧几里得距离)。
- 返回 最相似的K个向量(KNN 搜索)。
4️⃣ 排序与筛选 🎯
- 可以结合元数据(比如消息时间、类别等)进一步筛选搜索结果。
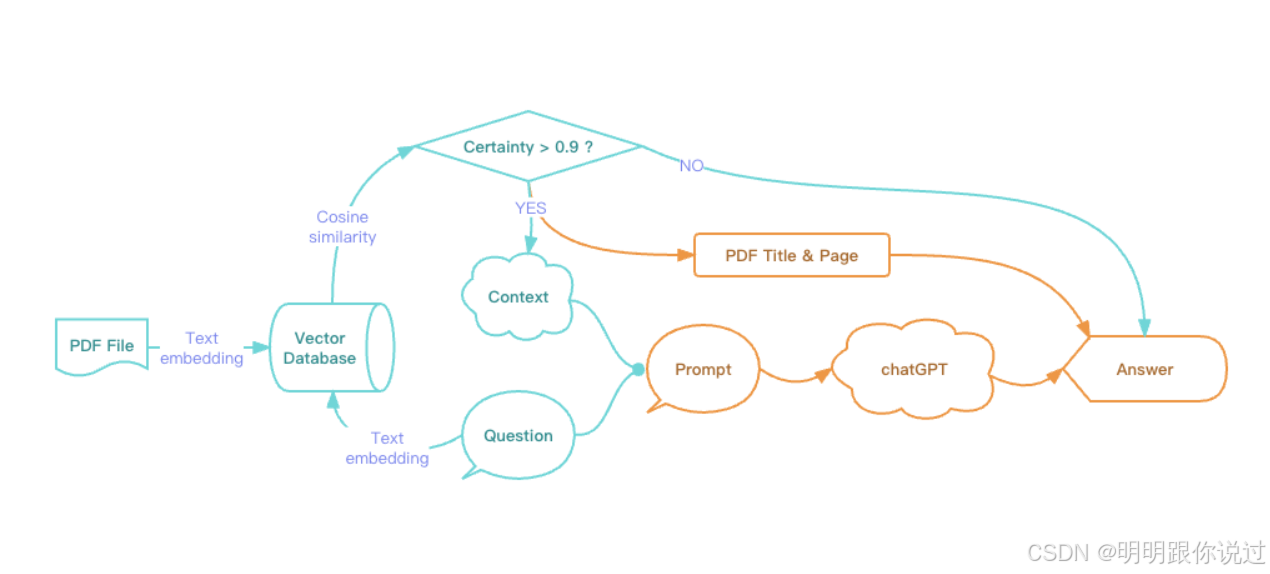
3、查询处理与结果返回流程
在 Weaviate 或任何向量数据库中,查询处理和结果返回的流程 主要包含 4 大阶段:
- 接收查询请求(API 层)
- 向量搜索(索引层)
- 数据匹配与筛选(存储层)
- 返回结果(查询层 & API 层)
3.1、接收查询请求(API 层)
- 用户通过 REST API 或 GraphQL 查询 Weaviate,发送查询请求。
- 查询的类型可以是:
- 相似性搜索(Nearest Neighbor Search, NNS)
- 带过滤条件的查询(Metadata Filtering)
- 全文搜索(Lexical Search)

3.2、向量搜索(索引层)
📌 核心目标:从百万级数据中 高效查找最相似的向量!
关键步骤:
- 文本向量化:
- Weaviate 内置 text2vec-transformers 模块,先将输入的文本转换为 向量(比如 768 维 BERT 向量)。
- 索引搜索(HNSW):
- 在 HNSW(Hierarchical Navigable Small World)索引 中快速定位 最接近的 K 个向量(Top-K 查询)。
- 相似度计算:
- 计算查询向量与索引向量的 余弦相似度(Cosine Similarity) 或 欧几里得距离(L2)。
- 初步筛选结果:
- 选出相似度 最高的 K 条短信,进入下一步数据匹配。
3.3、数据匹配与筛选(存储层)
🔹 从匹配的向量中,提取完整的数据(如原始文本、标签等)
- 查询的结果是最相似的向量 ID,但 Weaviate 还需要返回对应的原始数据。
- Weaviate 存储层 负责 检索元数据,如短信内容、是否垃圾短信(Spam / Ham)。
- 可能会应用 额外的过滤条件(例如,只获取 2024 年后的短信)。
3.4、返回结果(查询层 & API 层)
🔹 最终 Weaviate 返回 JSON 结果,供前端或 AI 模型使用
完整的查询流程
1️⃣ 用户发送查询 → 通过 REST API 或 GraphQL 提交查询请求(nearText、where 过滤等)。
2️⃣ Weaviate 解析查询 → 调用 text2vec-transformers 模块,把查询转成 向量表示。
3️⃣ 执行索引搜索 → HNSW 向量索引 进行 最近邻搜索(KNN),找到相似的向量。
4️⃣ 数据匹配 & 过滤 → 查询存储层,获取完整的短信内容和元数据。
5️⃣ 返回查询结果 → 结果通过 JSON 格式 返回给用户或前端应用。
💡 这个过程适用于 Weaviate,也适用于 FAISS、Milvus、Pinecone 等向量数据库的查询逻辑! 🚀
💕💕💕每一次的分享都是一次成长的旅程,感谢您的陪伴和关注。希望这些文章能陪伴您走过技术的一段旅程,共同见证成长和进步!😺😺😺
🧨🧨🧨让我们一起在技术的海洋中探索前行,共同书写美好的未来!!!


















 415
415

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











