






深度学习框架: TensorFlow Pytorch
transforms是Pytorch中的一个“工具箱” tensorboard:可视化工具 卷积操作:矩阵的乘法
forward:前向传播函数 (N,H,W,C):(批次大小,高,宽,通道数) 一个通道对应一个矩阵,RGB图形就是三个通道组成的
一.归一化(Normalization)
归一化(Normalization)是数据预处理中的一种重要技术,主要用于调整数据的范围或分布,使其更适合用于机器学习或深度学习模型的训练。归一化可以提高模型的收敛速度和性能,减少训练过程中的不稳定性。
归一化目的
1.提高训练效率:将输入特征缩放到相似的范围,可以加速梯度下降的收敛。
2.提高模型性能:防止某些特征主导损失函数,减少模型对特定特征的偏向。
3.增强数值稳定性:降低输入数据的方差,使模型在训练时更稳定
最小-最大归一化(Min-Max Normalization),将数据缩放到指定范围(通常是 [0, 1])
标准化(Z-score Normalization)
单位向量归一化(Unit Vector Normalization)
在深度学习中,归一化通常在以下情况下使用:
输入特征归一化:在将数据输入模型之前进行归一化,确保所有特征在相似的范围内。
批量归一化(Batch Normalization):在神经网络的各层之间进行归一化,减少内部协变量偏移(Internal Covariate Shift)。
二.卷积操作(Convolution)
在卷积操作中,有几个重要的参数会影响卷积层的行为和输出:
- 卷积核(Filter / Kernel)
定义:卷积核是一个小的权重矩阵,用于在输入图像上滑动并执行卷积操作。卷积核的大小通常表示为 (C_out, C_in, H_k, W_k),其中 C_out 是输出通道数,C_in 是输入通道数,H_k 和 W_k 是卷积核的高度和宽度。 - 步幅(Stride)
定义:步幅是卷积核在输入图像上滑动的步长。步幅越大,输出特征图的尺寸越小。默认步幅为 1。
影响:较大的步幅会导致更小的输出特征图,可能会丢失一些细节。 - 填充(Padding)
定义:填充是在输入图像的边缘添加额外的像素(通常是 0),以控制输出特征图的尺寸。常见的填充方式有:
Valid Padding:不添加填充,可能会导致输出尺寸小于输入尺寸。
Same Padding:添加填充以确保输出尺寸与输入尺寸相同(在步幅为 1 的情况下)。 - 输出通道数(Output Channels)
定义:输出通道数决定了卷积层生成的特征图的数量。每个输出通道对应一个卷积核。
影响:更多的输出通道通常意味着能够捕获更复杂的特征,但也会增加计算开销和参数数量。 - 输入通道数(Input Channels)
定义:输入通道数是指输入图像的通道数。例如,RGB 图像有 3 个通道,灰度图像只有 1 个通道。
影响:卷积操作需要输入通道数与卷积核的输入通道数相匹配。 - 激活函数(Activation Function)
定义:在卷积操作之后,通常会应用一个激活函数(例如 ReLU),以引入非线性,使网络能够学习更复杂的特征。
影响:激活函数会影响输出特征图的非线性特性。 - 反向传播(Backpropagation)
在训练过程中,卷积层的参数(卷积核的权重)会通过反向传播算法进行更新,以最小化损失函数。 - 参数数量(Number of Parameters)
定义:卷积层中的可学习参数数量计算公式为:
参数数量=(输入通道数×卷积核高度×卷积核宽度+1)×输出通道数
影响:参数数量的多少直接影响模型的复杂度和训练时间。
# conv2d(二维卷积层)使用
# 准备数据集
dataset = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset, batch_size=64) # batch_size 批次大小
# 搭建神经网络
class MyModule(nn.Module):
def __init__(self):
super(MyModule, self).__init__()
# 定义卷积层
self.conv1 = Conv2d(3, 6, 3, stride=1, padding=0)
def forward(self, x):
x = self.conv1(x)
return x
module = MyModule()
writer = SummaryWriter("./nn_logs")
step = 0
for data in dataloader:
imgs, target = data
output = module(imgs)
# 输入大小[64,3,32,32]
writer.add_images("input", imgs, step)
# 输出大小[64,6,30,30],32-3(kernel_size)+1 = 30
# 六通道无法显示,变成三通道
output = torch.reshape(output, (-1, 3, 30, 30))
writer.add_images("output", output, step)
step += 1
三.池化操作(Pooling)
池化操作(Pooling)是卷积神经网络(CNN)中的一种常用技术,主要用于减少特征图的空间尺寸(宽度和高度),从而降低计算复杂度和参数数量,同时提取重要特征。
1.池化目的
降维:通过减少特征图的尺寸,降低计算量和内存使用。
特征提取:保留最重要的特征,减少不必要的信息,增强模型的泛化能力。
不变性:通过池化操作提高模型对输入数据的小幅变化(如位置变化、缩放等)的不敏感性。
2.常见类型
最大池化(Max Pooling):
平均池化(Average Pooling):
全局平均池化(Global Average Pooling):
对整个特征图计算平均值,通常用于分类任务的最后一层。
3.参数
池化窗口大小(kernel_size):控制每次池化操作覆盖的区域大小。
步幅(Stride):窗口每次滑动的步长,控制池化操作的输出尺寸。
当执行池化操作时,特征图的尺寸并不总是整除池化核的大小。如果最后一个池化窗口不足以完全覆盖整个输入,那么可以选择两种不同的策略:
ceil_mode=False(默认):舍去不完整的池化窗口,使用向下取整 (floor) 来计算输出特征图的大小。
ceil_mode=True:保留不完整的池化窗口,使用向上取整 (ceil) 来计算输出特征图的大小。
import torch
import torchvision.datasets
from torch import nn
from torch.nn import MaxPool2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
class Mynn(nn.Module):
def __init__(self):
super().__init__()
# 定义池化层
self.maxpol1 = MaxPool2d(kernel_size=3, ceil_mode=False)
def forward(self, input):
output = self.maxpol1(input)
return output
dataset = torchvision.datasets.CIFAR10("dataset",train=False,download=True,
transform=torchvision.transforms.ToTensor())
dataloader = DataLoader(dataset,batch_size=64)
# input = torch.tensor([[1, 2, 0, 3, 1],
# [0, 1, 2, 3, 1],
# [1, 2, 1, 0, 0],
# [5, 2, 3, 1, 1],
# [2, 1, 0, 1, 1]])
# input = torch.reshape(input, (-1, 1, 5, 5))
mynn = Mynn()
writer = SummaryWriter("pool_logs")
step =0
for data in dataloader:
imgs,targets = data
writer.add_images("input",imgs,step)
output = mynn(imgs)
writer.add_images("pooled",output,step)
step += 1
四.非线性激活(Non-linear Activations)
非线性激活函数是神经网络中用于引入非线性变换的关键组件。其目的是将线性模型(例如卷积或全连接层的输出)转换为非线性输出,从而使神经网络能够处理复杂的非线性问题,如图像识别、自然语言处理等。
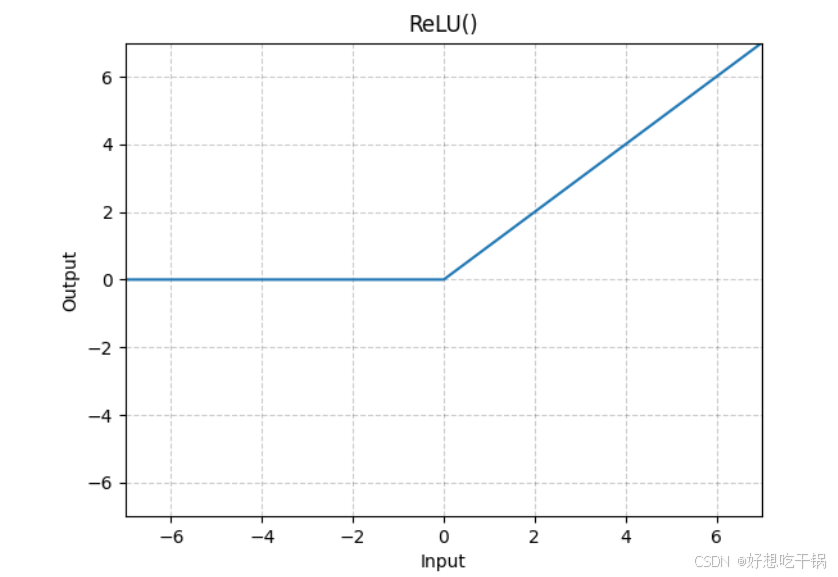
1.ReLU
ReLU(Rectified Linear Unit):f(x)=max(0,x)
优点:计算简单,解决了梯度消失问题,在深层网络中表现良好。
缺点:当输入小于 0 时,输出为 0,可能导致“神经元死亡”问题(部分神经元永远不更新)
import torch
from torch import nn
from torch.nn import ReLU
input = torch.tensor([[1,-0.5],
[-1,3]])
torch.reshape(input,(-1,1,2,2))
class Mynn(nn.Module):
def __init__(self):
super().__init__()
self.relu1 = ReLU(inplace=False) # inplace 非线性变换后是否替换原数据
def forward(self,input):
output = self.relu1(input)
return output
mynn = Mynn()
output = mynn(input)
print(output)
print(input)
效果图:
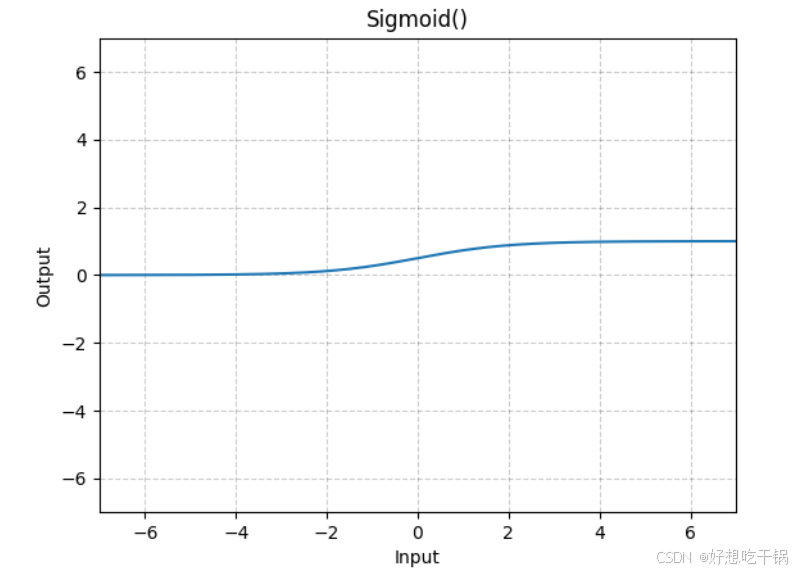
2.Sigmoid
Sigmoid:Sigmoid(x)=σ(x)=1 / (exp(−x)+1)
优点:将输出范围限制在 0 到 1,可以解释为概率。
缺点:在正负极限处梯度非常小,容易导致梯度消失问题。
import torch
import torchvision.datasets
from torch import nn
from torch.nn import ReLU, Sigmoid
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
input = torch.tensor([[1, -0.5],
[-1, 3]])
torch.reshape(input, (-1, 1, 2, 2))
class Mynn(nn.Module):
def __init__(self):
super().__init__()
self.sigmoid1 = Sigmoid()
def forward(self, input):
output = self.sigmoid1(input)
return output
dataset = torchvision.datasets.CIFAR10("dataset", train=False, download=True,
transform=torchvision.transforms.ToTensor())
dataloader = DataLoader(dataset,batch_size=64)
writer = SummaryWriter("action_logs")
step = 0
mynn = Mynn()
for data in dataloader:
imgs,targets = data
writer.add_images("input",imgs,step)
output = mynn(imgs)
writer.add_images("Sigmoided",output,step)
step += 1
效果图:
3.Softmax
Softmax 常用于分类任务的输出层,输出是多个类别的概率分布。公式为: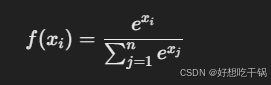
优点:将向量转换为概率分布,总和为 1。
常用于:多分类问题的输出层。
五.正则化(Regularization)
正则化(Regularization) 是一种防止机器学习模型在训练过程中过拟合(overfitting)的技术。过拟合是指模型在训练数据上表现良好,但在新数据上表现不佳,因为它“记住”了训练数据的细节和噪声,而不是学会了数据的通用特征。lambda
六.线性层(全连接层)
线性层(全连接层,Fully Connected Layer,FC Layer)是神经网络中的一种基础层,用于将输入与输出进行线性变换。
它的数学形式是一个线性方程,表示为:
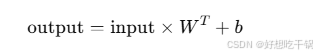
其中:
input:输入数据,通常是一个一维向量或者展平后的多维数据(例如图像数据展平成一维向量)。
W:权重矩阵,是线性层的参数,控制输入如何映射到输出。
b:偏置项(bias),也是线性层的参数,作用是调整输出,增加网络的拟合能力。
特点:
全连接:每个输入节点都与输出节点中的每一个节点相连接,所有连接都有各自的权重。
线性变换:该层实现的是一个线性变换,输入与输出之间的关系由权重矩阵 W 和偏置项 b 进行线性映射
线性层广泛应用于:
分类任务的最后一层:用于将特征映射到最终的分类标签数目。
特征变换:在多层神经网络中,线性层用于将输入特征映射到不同维度,以提取和表示不同层次的特征。
七.损失函数(LossFunction)
损失函数(Loss Function)是深度学习中的核心概念,它用于度量模型的预测结果与真实值之间的差异。模型的优化过程就是通过不断地最小化损失函数来调整模型的参数,使得模型的预测结果更加接近真实值。
1.损失函数的作用
1.度量误差:损失函数提供了一种方法来度量模型输出与目标值之间的误差。
2.优化目标:模型训练的目标是通过优化算法(如梯度下降)来最小化损失函数,从而提高模型的精度。
3.引导模型学习:损失函数的值大小直接影响模型权重的更新方式,它指引模型在训练时该往哪个方向优化。
2.损失函数使用
简单来说,在神经网络的训练过程中,不可避免地会出现差错,比如预测物品错误等等。在正向传播的预测值和真实值存在差异时,这种差异称为损失,通常由损失函数来计算。这个差异又作为反向传播的输入,来不断调整神经网络的准确度。
正向传播:
输入数据通过神经网络的各层,生成输出(预测值)。
通过损失函数,计算出预测值和真实值之间的误差(损失值)。
反向传播:
通过计算损失值对每个神经元的权重和偏置的导数,来衡量这些参数对误差的影响。这一过程称为计算梯度。
然后使用梯度下降等优化算法,通过这些梯度来调整神经网络的参数,使模型在下一次预测中表现得更好。
参数更新:
使用优化器(如 SGD 或 Adam)对模型的参数进行更新,调整神经网络权重,减少预测误差。
随着每次迭代(训练的每一轮),神经网络的预测误差逐步减小,准确度提高。
这个循环反复进行,直到模型的预测能力达到一个理想的水平。因此,损失是正向传播计算出来的,而梯度是反向传播时计算的,用于优化神经网络的参数。通过这种方式,网络不断自我调整,提升准确率。
3.常见损失函数

八.优化器(Optimizer)
优化器(Optimizer)是深度学习中的一种算法,用于调整神经网络的参数(如权重和偏置),以最小化损失函数并提高模型的性能。在反向传播中,损失函数的梯度被计算出来,优化器根据这些梯度来更新模型的参数,使模型逐步收敛到最优状态。
1.常见的优化器
1.随机梯度下降(SGD,Stochastic Gradient Descent)
原理:每次使用一小部分样本(小批量)计算损失并更新参数,逐渐逼近最优值。
优点:实现简单,计算速度快。
缺点:收敛速度慢,容易陷入局部最小值。
2.动量法(Momentum)
原理:在 SGD 基础上加上了动量(Momentum)的概念,使参数的更新不仅依赖当前的梯度,还参考了前几次的更新方向,帮助加速收敛。
优点:可以避免陷入局部最小值,加快收敛。
3.自适应学习率优化器(AdaGrad)
原理:根据每个参数的历史梯度大小来动态调整学习率,学习率会随着训练过程逐渐变小。
优点:适合稀疏数据或需要大范围调整学习率的场景。
缺点:学习率可能变得太小,导致训练停止。
2.优化器的核心参数
1.学习率(lr, Learning Rate):决定了每次更新参数的步长。学习率过高会导致模型无法收敛,过低则会导致训练速度过慢。
2.动量(momentum):在动量法中使用,帮助加快收敛速度。
3.优化器的使用
优化器通常结合反向传播,通过以下几个步骤:
1.初始化优化器:传入模型参数和学习率。
2.梯度清零:在每次反向传播前,将梯度清零,避免梯度累加。
3.反向传播:计算梯度。
4.更新参数:使用优化器根据梯度更新模型参数。
for data in dataloader:
inputs, labels = data
outputs = model(inputs)
loss = loss_function(outputs, labels)
optimizer.zero_grad() # 梯度清零
loss.backward() # 反向传播,计算梯度
optimizer.step() # 更新模型参数
八.模型训练实例
数据集:CIFAR 10 ,训练分类模型
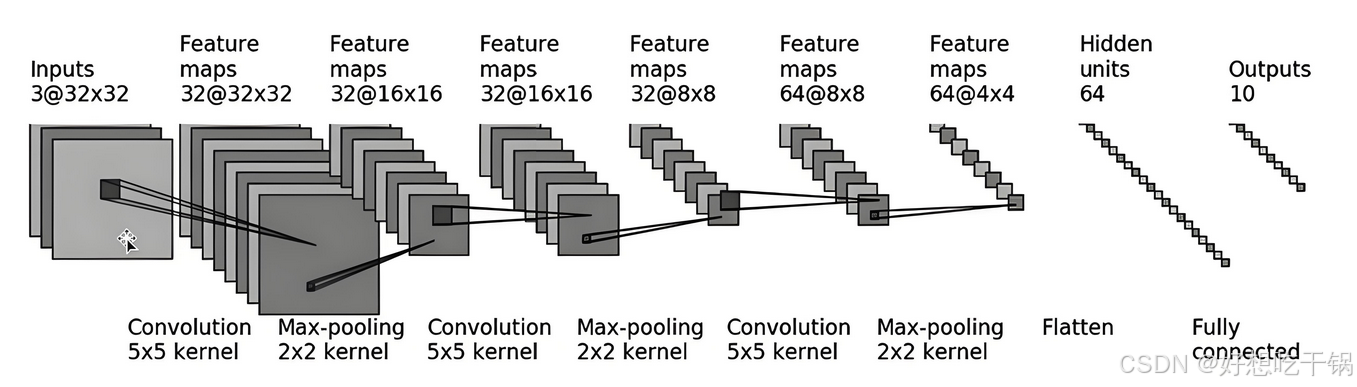 inputs 三通道(RGB)@32X32大小 (C,H,W)
inputs 三通道(RGB)@32X32大小 (C,H,W)
第一层:输入32x32,输出32x32,kernel_size = 5,因此需要填充2:32+4-5+1=32,计算公式如下:,其余类似

在其余参数默认情况下,Hout = Hin + 2*Padding - kernel_size +1,即若输出大小不变的情况下,padding = (kernel_size-1)/2
Flatten 函数的作用是将输入的多维张量(tensor)“展平”为一个一维的向量,方便后续的线性层或全连接层进行处理。特别是在卷积神经网络(CNN)中,卷积层和池化层通常会生成三维(或更高维)的特征图,而线性层通常只能接受一维向量作为输入。因此,在从卷积层到线性层过渡时,需要通过 Flatten 将高维特征图展平。
1.神经网络定义
class Mynn(nn.Module):
def __init__(self):
super().__init__()
# self.conv1 = Conv2d(3, 32, 5, padding=2) # 32+4-5+1 = 32
# self.maxpool1 = MaxPool2d(2) # 经过2x2池化后变成16x16
# self.conv2 = Conv2d(32, 32, 5, padding=2) # 16+4-5+1=16
# self.maxpool2 = MaxPool2d(2) # 再经过2x2池化后变成8x8
# self.conv3 = Conv2d(32, 64, 5, padding=2)
# self.maxpool3 = MaxPool2d(2) # 再经过2x2池化后变成4x4
# self.faltten = Flatten() # 展平64x4x4 = 1024
# self.linear1 = Linear(1024, 64)
# self.linear2 = Linear(64, 10)
# 等价
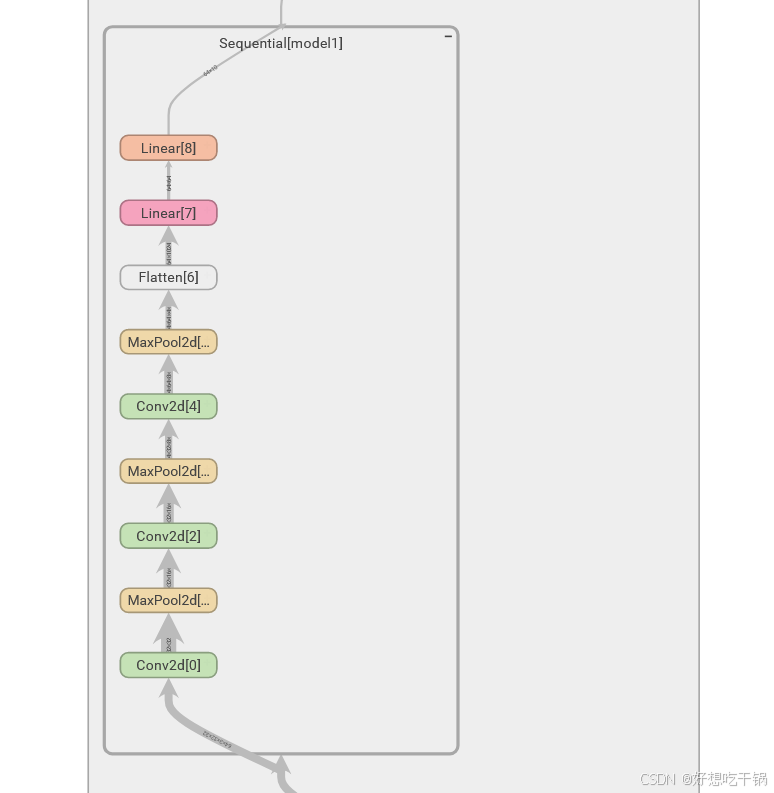
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, x):
# x = self.conv1(x)
# x = self.maxpool1(x)
# x = self.conv2(x)
# x = self.maxpool2(x)
# x = self.conv3(x)
# x = self.maxpool3(x)
# x = self.faltten(x)
# x = self.linear1(x)
# x = self.linear2(x)
x = self.model1(x)
return x
2.训练和测试
import torch.optim
import torchvision
from torch import nn
from torch.nn import Sequential, Conv2d, MaxPool2d, Flatten, Linear
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from Mymodule import * # 把自己定义的神经网络引用过来
# 定义设备:如果有 GPU 则使用 GPU,否则使用 CPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 准备数据集
train_data = torchvision.datasets.CIFAR10("./dataset", train=True, transform=torchvision.transforms.ToTensor()
, download=True)
test_data = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor()
, download=True)
print("训练集的长度:{}".format(len(train_data)))
print("测试集长度:{}".format(len(test_data)))
# 加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
# 创建网络模型
my_nn = Mynn()
my_nn = my_nn.to(device) # 利用GPU进行训练
# 损失函数
loss_func = nn.CrossEntropyLoss()
# 优化器
learning_rate = 0.01
optimizer = torch.optim.SGD(my_nn.parameters(), lr=learning_rate)
# 设置训练网络的参数
# 记录训练次数
total_train_step = 0
# 记录测试次数
total_test_step = 0
# 训练轮数
epoch = 10
# 添加可视化tensorboard
writer = SummaryWriter("./train_logs")
for i in range(epoch):
print("---第{}轮训练开始---".format(i + 1))
# 训练步骤开始
my_nn.train()
for data in train_dataloader:
imgs, targets = data
imgs = imgs.to(device)
targets = targets.to(device)
outputs = my_nn(imgs) # 输入神经网络
loss = loss_func(outputs, targets) # 获取损失
# 优化器优化模型
optimizer.zero_grad() # 梯度清零
loss.backward() # 反向传播
optimizer.step() # 优化
total_train_step += 1
if total_train_step % 100 == 0:
print("训练次数:{},Loss:{}".format(total_train_step, loss.item()))
writer.add_scalar("train_loss", loss.item(), total_train_step)
# 测试步骤开始
my_nn.eval()
total_test_loss = 0
total_accuracy = 0 # 正确率
with torch.no_grad(): # 禁用了梯度计算,在测试过程中不需要计算梯度,不需要进行反向传播和权重更新
for data in test_dataloader:
imgs, targets = data
imgs = imgs.to(device)
targets = targets.to(device)
outputs = my_nn(imgs) # 输入神经网络
loss = loss_func(outputs, targets) # 获取损失
total_test_loss += loss.item()
accuracy = (outputs.argmax(1) == targets).sum() # 预测正确的数量
total_accuracy += accuracy
print("整体测试集上的Loss:{}".format(total_test_loss))
print("整体测试集上的正确率:{}".format(total_accuracy / len(test_data)))
writer.add_scalar("test_loss", total_test_loss, total_test_step)
writer.add_scalar("test_accuracy", total_accuracy, total_test_step)
total_test_step += 1
# 保存模型
#torch.save(my_nn, "mynn.pth")
torch.save(my_nn.state_dict(),"mynn.pth")
print("模型已保存 ")
writer.close()
3.模型的加载和保存
# 模型的保存与加载
vgg16 = torchvision.models.vgg16(pretrained=False)
# 保存方式 1,模型结构+模型参数
torch.save(vgg16,"vgg16_method1.pth")
# 保存方式 2,模型参数(官方推荐)使用时需要有神经网络定义
torch.save(vgg16.state_dict(),"vgg16_method2.pth")
# 加载方式
model1 = torch.load("vgg16_method1.pth")
4.利用GPU进行训练
- 检查是否有GPU
import torch
# 检查是否有可用的 GPU
if torch.cuda.is_available():
print("CUDA is available! You can use GPU.")
else:
print("CUDA is not available. You will use CPU.")
- 移动数据到GPU(使用to(device))

Google Colab免费GPU使用
# 定义设备:如果有 GPU 则使用 GPU,否则使用 CPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
my_nn = my_nn.to(device) # 模型移动到 GPU
# 损失函数
#loss_func = nn.CrossEntropyLoss().to(device)
# 数据移动到 GPU
imgs, targets = data
imgs = imgs.to(device)
targets = targets.to(device)
在 PyTorch 中,损失函数和优化器本身不需要显式地移动到 GPU,因为它们主要是基于模型参数和输入数据进行操作的。如果模型参数和数据都在 GPU 上,损失函数和优化器会自动与这些参数和数据在同一设备上工作。因此,只需要确保模型和数据在 GPU 上即可,损失函数和优化器不需要显式地调用 .to(device)。
5.总结
- 数据准备
数据集加载:
使用 torchvision.datasets.CIFAR10 加载 CIFAR-10 数据集,这个数据集包含 60000 张 32x32 像素的彩色图片,分为 10 类。
训练集和测试集分别通过 train=True 和 train=False 参数进行加载,transform=torchvision.transforms.ToTensor() 用于将图片转换为 Tensor 格式。
数据通过 DataLoader 进行批次加载,batch_size=64 表示每次处理 64 张图片。 - 设备配置
设备选择:
通过 torch.device(“cuda” if torch.cuda.is_available() else “cpu”),代码自动检测是否有 GPU,如果有则使用 GPU 进行训练,否则使用 CPU。 - 神经网络模型
模型定义:
Mynn 是自定义的神经网络模型,通过 my_nn = my_nn.to(device) 将模型加载到设备上进行训练。
模型中的层次结构通过引用 Mymodule 模块实现,适用于处理 CIFAR-10 图片。 - 损失函数和优化器
损失函数:
使用 CrossEntropyLoss() 作为损失函数,这是分类任务中常用的损失函数,适合多类分类任务。
优化器:
使用 SGD(随机梯度下降)优化器,学习率为 0.01,优化模型参数。 - 训练过程
训练步骤:
通过 for epoch in range(epoch) 循环进行 10 轮训练。
my_nn.train() 设置为训练模式,表示模型处于训练状态,会启用 Batch Normalization 和 Dropout 等操作。
训练中,模型将输入图片(imgs)经过神经网络,输出预测值(outputs),并与真实标签(targets)计算损失值(loss)。
每次反向传播前,使用 optimizer.zero_grad() 清除之前的梯度,以防止梯度累加。然后,loss.backward() 执行反向传播,计算梯度,最后使用 optimizer.step() 更新模型参数。 - 测试过程
测试步骤:
每轮训练结束后,模型会进入测试模式(my_nn.eval()),在测试模式下不会更新模型参数。
使用 torch.no_grad() 禁用梯度计算,以提高测试效率,减少内存消耗。
测试数据经过模型,计算测试集上的损失值(total_test_loss),并通过 outputs.argmax(1) 获取模型的预测结果,计算模型的准确率(total_accuracy)。 - TensorBoard 可视化
TensorBoard 日志记录:
使用 SummaryWriter 将训练过程中的损失值(train_loss)和测试集上的损失值(test_loss)、准确率(test_accuracy)写入 TensorBoard 进行可视化。
在训练和测试中,通过 writer.add_scalar() 方法记录相应的数值,便于在 TensorBoard 中查看训练过程。 - 模型保存
模型保存:
使用torch.save(my_nn.state_dict(),“mynn.pth”)保存模型参数,以便于以后使用或进行进一步的推理。


















 7万+
7万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









