摘要生成于 C知道 ,由 DeepSeek-R1 满血版支持, 前往体验 >
需求: 爬取三国演义小说所有的章节标题和章节内容
1.导入模块
2.确定目标URL
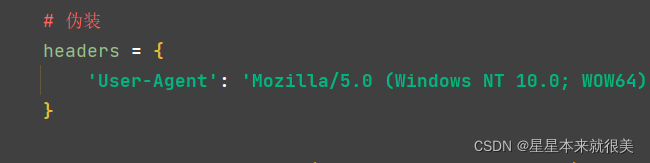
3.伪装
4.发送请求,响应数据
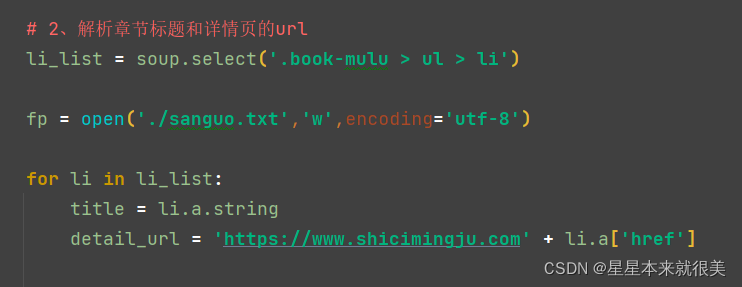
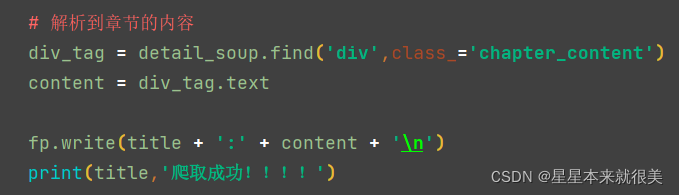
5.解析数据
立减 ¥
请填写红包祝福语或标题
红包个数最小为10个
红包金额最低5元
抵扣说明:
1.余额是钱包充值的虚拟货币,按照1:1的比例进行支付金额的抵扣。 2.余额无法直接购买下载,可以购买VIP、付费专栏及课程。







 本文档详细介绍了如何使用Python进行网络爬虫操作,目标是获取三国演义的所有章节标题和内容。步骤包括导入相关库、设定目标URL、设置请求头、发送HTTP请求并获取响应,最后解析HTML提取所需数据。通过这个教程,读者可以掌握基本的网页抓取技能。
本文档详细介绍了如何使用Python进行网络爬虫操作,目标是获取三国演义的所有章节标题和内容。步骤包括导入相关库、设定目标URL、设置请求头、发送HTTP请求并获取响应,最后解析HTML提取所需数据。通过这个教程,读者可以掌握基本的网页抓取技能。






 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























