






环境准备:环境差不多就行
python 3.8 opencv-python os numpy PIL
1、人脸数据集创建
import cv2
import os
cam = cv2.VideoCapture(0)
cam.set(3, 640)
cam.set(4, 480)
face_detector = cv2.CascadeClassifier('haarcascade_frontalface_default.xml')
face_id = input('\n enter user id end press <return> ==> ')
if not os.path.exists('dataset'):
os.makedirs('dataset')
print("\n [INFO] Initializing face capture. Look at the camera and wait ...")
count = 0
while True:
ret, img = cam.read()
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
faces = face_detector.detectMultiScale(gray, 1.3, 5)
for (x, y, w, h) in faces:
cv2.rectangle(img, (x, y), (x + w, y + h), (255, 0, 0), 2)
count += 1
cv2.imwrite("dataset/User." + str(face_id) + '.' + str(count) + ".jpg", gray[y:y + h, x:x + w])
cv2.imshow('image', img)
k = cv2.waitKey(100) & 0xff # Press 'ESC' for exiting video
if k == 27:
break
elif count >= 100: # Take 30 face sample and stop video
break
print("\n [INFO] Exiting Program and cleanup stuff")
cam.release()
cv2.destroyAllWindows()
默认的摄像头地址是0,如果是开发板的usb摄像头可以通过 ls /dev/video* 进行查询设置成对应的号就可以,我默认采100张人脸照片,存到dataset文件夹,如果没有这个文件夹的话,代码会帮你创建无需担心。ID号可以从1开始自加,或者自己定义一个都可以。
2、人脸数据集训练
import cv2
import numpy as np
from PIL import Image
import os
if not os.path.exists('trainer'):
os.makedirs('trainer')
path = 'dataset'
recognizer = cv2.face.LBPHFaceRecognizer_create()
detector = cv2.CascadeClassifier("haarcascade_frontalface_default.xml");
def getImagesAndLabels(path):
imagePaths = [os.path.join(path,f) for f in os.listdir(path)]
faceSamples=[]
ids = []
for imagePath in imagePaths:
PIL_img = Image.open(imagePath).convert('L') # Convert it to grayscale
img_numpy = np.array(PIL_img, 'uint8')
id = int(os.path.split(imagePath)[-1].split(".")[1])
faces = detector.detectMultiScale(img_numpy)
for (x,y,w,h) in faces:
faceSamples.append(img_numpy[y:y+h, x:x+w])
ids.append(id)
return faceSamples, ids
print("\n [INFO] Training faces. It will take a few seconds. Wait ...")
faces, ids = getImagesAndLabels(path)
recognizer.train(faces, np.array(ids))
recognizer.write('trainer/trainer.yml')
print("\n [INFO] {0} faces trained. Exiting Program".format(len(np.unique(ids))))
这个代码就是按照你刚才设置的ID号和你的100张人脸图像进行训练,直接执行就可以,训练好之后在 trainer文件夹下会有trainer.yml文件,这就是你刚才的权重文件。
3、人脸识别
接下来按照刚才训练的权重文件进行识别,默认情况下在界面上会显示当前帧率,ID号对应的名字和置 信度,默认情况下,界面上面显示的数值越大,模型对当前人脸识别的可信度越高。
import cv2
recognizer = cv2.face.LBPHFaceRecognizer_create()#使用局部二值模式直方图(LBPH)方法初始化人脸识别器。
recognizer.read('trainer/trainer.yml')#加载事先训练的模型文件 trainer.yml,包含不同人脸的特征数据。
cascadePath = "haarcascade_frontalface_default.xml"# OpenCV 提供的 Haar特征级联分类器 检测人脸。
faceCascade = cv2.CascadeClassifier(cascadePath)#加载 haarcascade_frontalface_default.xml 人脸检测模型
font = cv2.FONT_HERSHEY_SIMPLEX#定义文本字体,用于在图像上显示识别结果
id = 0#当前识别的人脸ID。
names = ['None', 'tsy', 'gy', 'Ilza', 'lyw', 'W']#names: 人脸ID和名称的对应列表,例如 id=1 对应 tsy,id=2 对应 ywl。
cam = cv2.VideoCapture(0)#打开摄像头(0表示默认摄像头)
cam.set(3, 640) # 设置摄像头捕捉视频的宽度和高度。
cam.set(4, 480)
minW = 0.1 * cam.get(3)#定义检测人脸的最小宽高(原始图像的10%),过滤掉过小的人脸。
minH = 0.1 * cam.get(4)
prev_time = 0## 初始化帧率计算时间戳
while True:
ret, img = cam.read()#ret: 捕获成功则为True img: 当前视频帧的图像数据
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)#将图像转换为灰度(灰度图适合于Haar级联检测和LBPH识别)
#人脸检测
faces = faceCascade.detectMultiScale(
gray,
scaleFactor=1.2,#图像缩放因子,越大越快但可能漏检
minNeighbors=5,#每个候选矩形需检测到至少5次才被认为是人脸。
minSize=(int(minW), int(minH)),#最小人脸尺寸,过滤过小区域
)
for (x, y, w, h) in faces:
#rectangle: 参数 (x, y) 是左上角坐标,(x+w, y+h) 是右下角坐标。
cv2.rectangle(img, (x, y), (x + w, y + h), (0, 255, 0), 2)
id, confidence = recognizer.predict(gray[y:y + h, x:x + w])
if confidence < 100:
id = names[id]
confidence = " {0}%".format(round(100 - confidence))
else:
id = "unknown"
confidence = " {0}%".format(round(100 - confidence))
cv2.putText(img, str(id), (x + 5, y - 5), font, 1, (255, 255, 255), 2)
cv2.putText(img, str(confidence), (x + 5, y + h - 5), font, 1, (255, 255, 0), 1)
# 计算当前帧率(FPS)
curr_time = cv2.getTickCount()
fps = cv2.getTickFrequency() / (curr_time - prev_time)
prev_time = curr_time
# 在视频中显示当前FPS
cv2.putText(img, f"FPS: {fps:.2f}", (10, 30), font, 1, (0, 0, 255), 2)
cv2.imshow('camera', img)
k = cv2.waitKey(10) & 0xFF # Press 'ESC' for exiting video
if k == 27:
break
# Do a bit of cleanup
print("\n [INFO] Exiting Program and cleanup stuff")
cam.release()
cv2.destroyAllWindows()
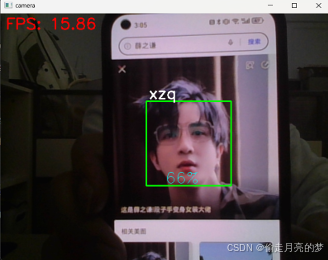
到此人脸识别的任务基本已经完成了。
但是现在有一个人脸识别的项目需要人脸识别加人脸认证,需要server端和client端,我又写了两个代 码,基本完成此要求,后续还需要在开发,并且有socket的工作,为毕业设计增加了变种,话不多说, 我把这两个代码放上了,需要自取。
sever
import socket
import cv2
import pickle
import struct
import threading # 用于多线程处理
recognizer = cv2.face.LBPHFaceRecognizer_create()
recognizer.read('trainer/trainer.yml')
HOST = '0.0.0.0' # 监听所有可用的 IP
PORT = 12345 # 服务端端口
server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
server_socket.bind((HOST, PORT))
server_socket.listen(5)
print("[INFO] 服务端已启动,等待客户端连接...")
def handle_client(conn, addr):
print(f"[INFO] 收到客户端连接:{addr}")
try:
data_length = conn.recv(4)
if len(data_length) < 4:
return
length = struct.unpack("!I", data_length)[0]
data = b""
while len(data) < length:
packet = conn.recv(4096)
if not packet:
break
data += packet
face_data = pickle.loads(data)
# 使用模型进行预测
id, confidence = recognizer.predict(face_data)
# 根据 confidence 判断识别结果
if confidence < 75: # 设置一个阈值,根据实际情况调整
# 识别成功,返回对应的 id
response = {'id': str(id), 'confidence': str(confidence)}
else:
# 如果 confidence 大于阈值,则认为未能识别成功
response = {'id': "None", 'confidence': "未知"}
print(f"[INFO] 识别结果: ID={response['id']}, Confidence={response['confidence']}")
# 返回识别结果给客户端
conn.send(pickle.dumps(response))
except Exception as e:
print(f"[ERROR] 处理客户端 {addr} 时发生错误: {e}")
finally:
conn.close() # 关闭连接
while True:
conn, addr = server_socket.accept()
# 为每个客户端连接启动一个新线程
client_thread = threading.Thread(target=handle_client, args=(conn, addr))
client_thread.start()
client
import socket
import cv2
import pickle
import struct # 用于打包和解包数据长度
# 服务端 IP 和端口
SERVER_IP = 'xxx.xxx.x.xxx' # 换成自己的ip地址
SERVER_PORT = 12345 # 服务端端口
# 加载人脸检测模型
cascadePath = "haarcascade_frontalface_default.xml"
faceCascade = cv2.CascadeClassifier(cascadePath)
cam = cv2.VideoCapture(0)
cam.set(3, 640)
cam.set(4, 480)
font = cv2.FONT_HERSHEY_SIMPLEX
names = ['None', 'tsy', 'gy', 'shy', 'Z', 'W'] # 这个是根据服务端的id和名字做的匹配
print("[INFO] 客户端已启动,按 ESC 键退出")
while True:
ret, img = cam.read()
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
faces = faceCascade.detectMultiScale(gray, scaleFactor=1.2, minNeighbors=5, minSize=(30, 30))
for (x, y, w, h) in faces:
face_data = gray[y:y + h, x:x + w] # 截取人脸区域
cv2.rectangle(img, (x, y), (x + w, y + h), (0, 255, 0), 2)
# 将人脸数据发送到服务端
client_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
client_socket.connect((SERVER_IP, SERVER_PORT))
# 序列化人脸数据
serialized_data = pickle.dumps(face_data)
# 发送数据的长度(4个字节),然后是序列化的人脸数据
data_length = struct.pack("!I", len(serialized_data)) # 打包数据长度(大端字节序)
client_socket.sendall(data_length + serialized_data)
# 接收服务端返回的结果
response = b""
while True:
packet = client_socket.recv(4096)
response += packet
if len(packet) < 4096:
break
try:
result = pickle.loads(response)
except EOFError:
print("[ERROR] 未能接收到完整的响应数据")
continue # 如果接收失败,跳过当前循环,重新接收数据
client_socket.close()
# 解析服务端返回的识别结果
id = result['id']
confidence = result['confidence']
# 尝试将confidence转换为float,如果无法转换,则设置为unknown
try:
confidence = float(confidence)
if confidence < 100:
# 如果 id 不是整数,设置为 "unknown"
try:
id = int(id) # 尝试将 id 转换为整数
id = names[id] # 将ID转换为对应的名称
except ValueError:
id = "unknown" # 如果 id 无法转换为整数,设置为 "unknown"
confidence = f"{int(confidence)}%" # 显示置信度
else:
id = "unknown"
confidence = "100%" # 设置默认最大置信度百分比
except ValueError:
# 如果无法转换为float,则认为是未知的
id = "unknown"
confidence = "未知" # 或者设置为 "unknown" 或其他标识
# 显示识别结果
label = f"{id} {confidence}"
cv2.putText(img, label, (x, y - 10), font, 0.75, (255, 255, 255), 2)
# 显示结果图像
cv2.imshow('Client', img)
# 按 ESC 键退出
k = cv2.waitKey(10) & 0xFF
if k == 27: # 按 ESC 键退出
break
# 清理资源
cam.release()
cv2.destroyAllWindows()
美中不足是没有QT界面,要是有需要我在把他补上,对于这个socket,需要将第1、2、4段代码放在服 务器端执行,第3、5段代码放在客户端执行,对服务器进行人脸采集和人脸编码,流程图大致如下
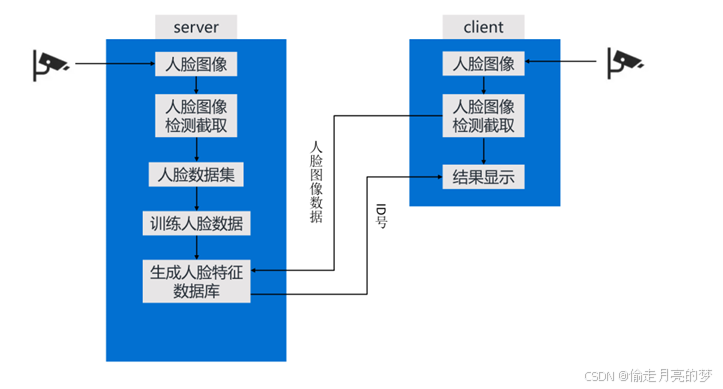
大致就是这样的,有问题请联系我。
补充
QT
import sys
import subprocess
import cv2
import os
from PyQt5.QtWidgets import QApplication, QMainWindow, QPushButton, QVBoxLayout, QLabel, QWidget
from PyQt5.QtCore import QTimer
from PyQt5.QtGui import QImage, QPixmap
class MainWindow(QMainWindow):
def __init__(self):
super().__init__()
self.setWindowTitle("Qt 显示摄像头画面")
self.resize(800, 600)
layout = QVBoxLayout()
self.video_label = QLabel("摄像头画面")
self.video_label.setFixedSize(640, 480)
layout.addWidget(self.video_label)
self.button1 = QPushButton("运行脚本1")
self.button2 = QPushButton("运行脚本2")
self.button3 = QPushButton("运行脚本3")
layout.addWidget(self.button1)
layout.addWidget(self.button2)
layout.addWidget(self.button3)
self.button1.clicked.connect(lambda: self.run_script("01_face_dataset.py"))
self.button2.clicked.connect(lambda: self.run_script("02_face_training.py"))
self.button3.clicked.connect(lambda: self.run_script("03_face_recognition.py"))
self.timer = QTimer(self)
self.timer.timeout.connect(self.update_frame)
self.timer.start(100) # 每 100ms 检查一次图像
container = QWidget()
container.setLayout(layout)
self.setCentralWidget(container)
def run_script(self, script_name):
try:
subprocess.Popen(["python", script_name])
except Exception as e:
print(f"运行脚本 {script_name} 失败: {e}")
def update_frame(self):
# 读取最新的摄像头图像并显示
image_path = "latest_frame.jpg"
if os.path.exists(image_path):
frame = cv2.imread(image_path)
if frame is not None:
# 转换为 RGB 格式
rgb_frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
h, w, ch = rgb_frame.shape
# 转为 QImage
qimg = QImage(rgb_frame.data, w, h, ch * w, QImage.Format_RGB888)
self.video_label.setPixmap(QPixmap.fromImage(qimg))
def closeEvent(self, event):
event.accept()
if __name__ == "__main__":
app = QApplication(sys.argv)
window = MainWindow()
window.show()
sys.exit(app.exec_())

















 8766
8766

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









