







一、HDFS-核心参数
1.1NameNode内存生产配置
1)NameNode内存计算
每个文件块大概占用150byte,一台服务器128G内存为例,能存多少文件快?
128*1024*1024*1024、150byte≈9.1亿
G kb mb byte
2)Hadoop2.x系列配置NameNode
namenode内存默认2000m,如果服务器内存4G,namenode内存可以配置3G 在hadoop.env.sh中配置
HADOOP_NAMENODE_OPTS=-Xmx3072m
3)Hadoop3.x 配置Namenode
①hadoop-env.sh中描述Hadoop的内存是动态分配的
②查看NameNode占用内存 jmap -heap 7140
③查看DataNode占用内存jmap -heap 7259
NameNode:namenode最小值1G,每增加1000000个block,增加1G内存
DataNode:datanode最小值4G block数或者副本数升高,都应该调大datanode的值
一个datanode上的副本总数低于4000000调为4G 超过4000000每增加1000000 增加1G
具体修改hadoop-env.sh
export HDFS_NAMENODE_OPTS="-Dhadoop.security.logger=INFO,RFAS -Xmx1024m"
export HDFS_DATANODE_OPTS="-Dhadoop.security.logger=INFO,RFAS -Xmx1024m"
1.2NameNode心跳并发配置
1)hdfs-site.xml
<property>
<name>dfs.namenode.handler.count</name>
<value>21</value>
</property>
1.3开启回收站配置
1)回收站工作机制
检查回收站的间隔时间: fs.trash.checkpoint.interval=10
设置文件存货时间:fs.trash.interval=60
2)开启回收站功能参数说明
①默认值fs.trash.interval=0,0表示禁用回收站:其他值表示设置文件的存活时间
②默认值fs.trash.checkpoint.interval=0,检查回收站的间隔时间。如果该值为0,则该值设置和fs.trash.interval的参数值相等
③要求fs.trash.checkpoint.interval<=fs.trash.interval
3)启用回收站
修改core-site.xml 配置垃圾回收时间为1分钟
<property>
<name>fs.trash.interval</name>
<value>1</value>
</property>
4)查看回收站
回收站目录在HDFS集群中的路径:/usr/cyf/.Trash/...
5)通过网页上直接删除的文件不会进入回收站
6)通过程序删除的文件不会经过回收站,需调用moveToTrash()才进入回收站
Trash trash = New Trash(conf)
trash.moveToTrash(path)
7)只有在命令行利用hadoop fs -rm 命令删除的文件才会走回收站
hadoop fs -rm -r /

二、HDFS-集群压测
HDFS的读写性能主要受网络和磁盘影响比较大,为了方便测试,将hadoop102、hadoop103、hadoop104虚拟机网络设置为100mpbs=12M/s
2.1测试HDFS写性能
0)写测试底层原理
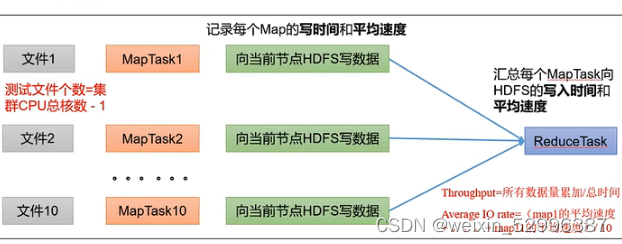
1)测试内容:向HDFS集群写10个128M的文件
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.1.1-tests.jar TestDFSIO -write -nrFiles 10 -fileSize 128MB

3)测试结果分析
(1)由于副本1就在本地 所以该副本不参与测试
一共参与测试的文件: 10个文件*2个副本=20个
压测后的速度: 3.53
实测速度:3.53m/s * 20个文件≈71.6m/s
三台服务器的带宽:12.5+12.5+12.5≈30m/s
所有网络资源都已经用满
如果实测速度远远小于网络,并且实测速度不能满足工作需求,可以考虑采用固态硬盘或者增加磁盘个数
(2)如果客户端不在集群节点,那么三个副本都将参与计算
2.2测试HDFS读性能
1)测试内容:读取HDFS集群10个128m的文件

2)删除测试生成数据

3)测试结果分析:为什么读取文件速度大于网络带宽?
由于目前只有三台服务器,且有三个副本,数据读取就近原则,相当于都是读取的本地磁盘数据,没有网络影响
三、HDFS多目录
3.1NameNode多目录配置
1)NameNode的本地目录可以配置成多个,且每个目录存放内容相同,增加了可靠性
2)具体配置
(1)在hdfs-site.xml文件中添加如下内容
<property>
<name>dfs.namenode.name.dir</name>
<value>file://${hadoop.tmp.dir}/dfs/name1,file://${hadoop.tmp.dir}/dfs/name2</value>
</property>
3.2DataNode多目录配置
1)DataNode可以配置成多个目录,每个目录存储的数据不一样(数据不是副本)
2)具体配置如下:
在hdfs-site.xml文件
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1592
1592

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









