






Win11使用docker compose 部署spark和mysql,进行 Spark SQL 读写数据库操作
1、修改docker-compose.yml
version: '2'
services:
spark-notebook:
image: jupyter/pyspark-notebook
hostname: spark
volumes:
- D:/Docker/sparkMK:/home/jovyan/work
ports:
- '8888:8888'
mysql:
image: mysql:8.0.12
hostname: mysql
restart: always
command: --default-authentication-plugin=mysql_native_password
expose:
- "3306" #for service mysql-proxy
ports:
- "3307:3306" #for external connection
volumes:
- D:/Docker/sparkMK/mysql/mysql_data:/var/lib/mysql #mysql-data
environment:
TZ: Asia/Shanghai
MYSQL_ROOT_PASSWORD: root
MYSQL_DATABASE: database
MYSQL_USER: root
MYSQL_PASSWORD: root
zookeeper:
image: 'bitnami/zookeeper:latest'
kafka:
image: 'bitnami/kafka:latest'
networks:
default:
external:
name: hadoop
2、再打开一个PowerShell,切换目录
PS C:\Windows\system32> cd D:\Docker\sparkMK\mysql
PS D:\Docker\sparkMK\mysql>
2、启动容器
docker-compose up -d
3、进入mysql
PS D:\Docker\sparkMK\mysql> docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
0d0f2468b1d6 mysql:8.0.12 "docker-entrypoint.s…" 25 seconds ago Up 11 seconds 33060/tcp, 0.0.0.0:3307->3306/tcp mysql-mysql-1
d37a29e2e8df jupyter/pyspark-notebook "tini -g -- start-no…" 25 seconds ago Up 22 seconds (healthy) 4040/tcp, 0.0.0.0:8888->8888/tcp mysql-spark-notebook-1
PS D:\Docker\sparkMK\mysql> docker exec -it 0d0f2468b1d6 /bin/bash
4、启动mysql数据库
mysql -u root -p
密码:root
5、输入如下sql语句,完成数据库和表的创建
mysql> create database spark;
Query OK, 1 row affected (0.10 sec)
mysql> use spark;
Database changed
mysql> create table student (id int(4), name char(20), gender char(4), age int(4));
Query OK, 0 rows affected (0.04 sec)
mysql> insert into student values(1, 'Xueqian', 'F', 23);
Query OK, 1 row affected (0.11 sec)
mysql> insert into student values(2, 'Weiliang', 'M', 24);
Query OK, 1 row affected (0.11 sec)
mysql> select * from student;
+------+----------+--------+------+
| id | name | gender | age |
+------+----------+--------+------+
| 1 | Xueqian | F | 23 |
| 2 | Weiliang | M | 24 |
+------+----------+--------+------+
2 rows in set (0.00 sec)
6、读取 MySQL数据库中的数据
(1)将驱动放在/usr/local/spark/jars下
PS D:\Docker\sparkMK\mysql>docker cp mysql-connector-java-8.0.29.jar mysql-spark-notebook-1:/usr/local/spark/jars
docker cp windows文件路劲 容器名字:容器路径
容器名称可用docker ps 查一下
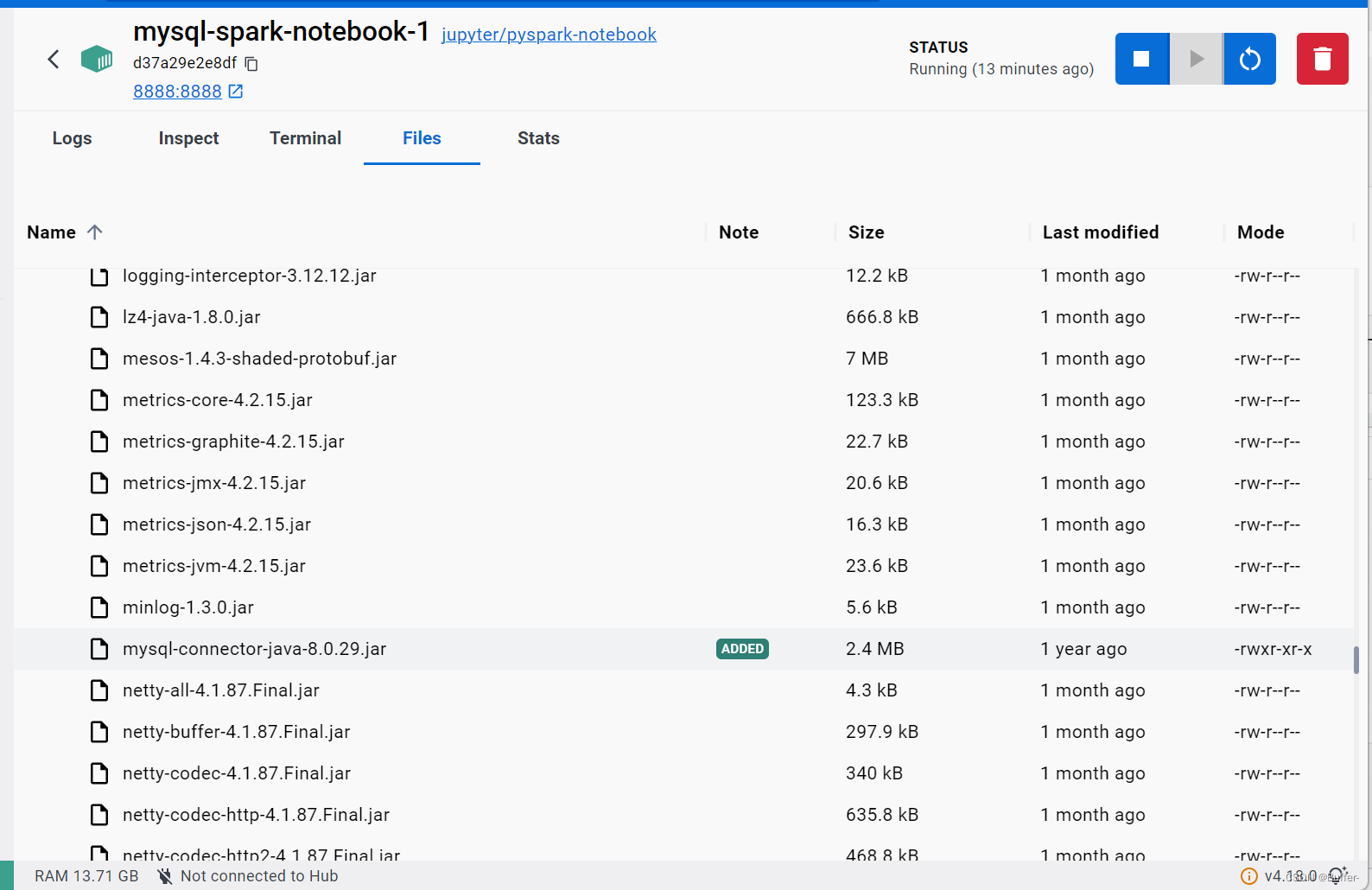
在docker desktop中可看到添加成功
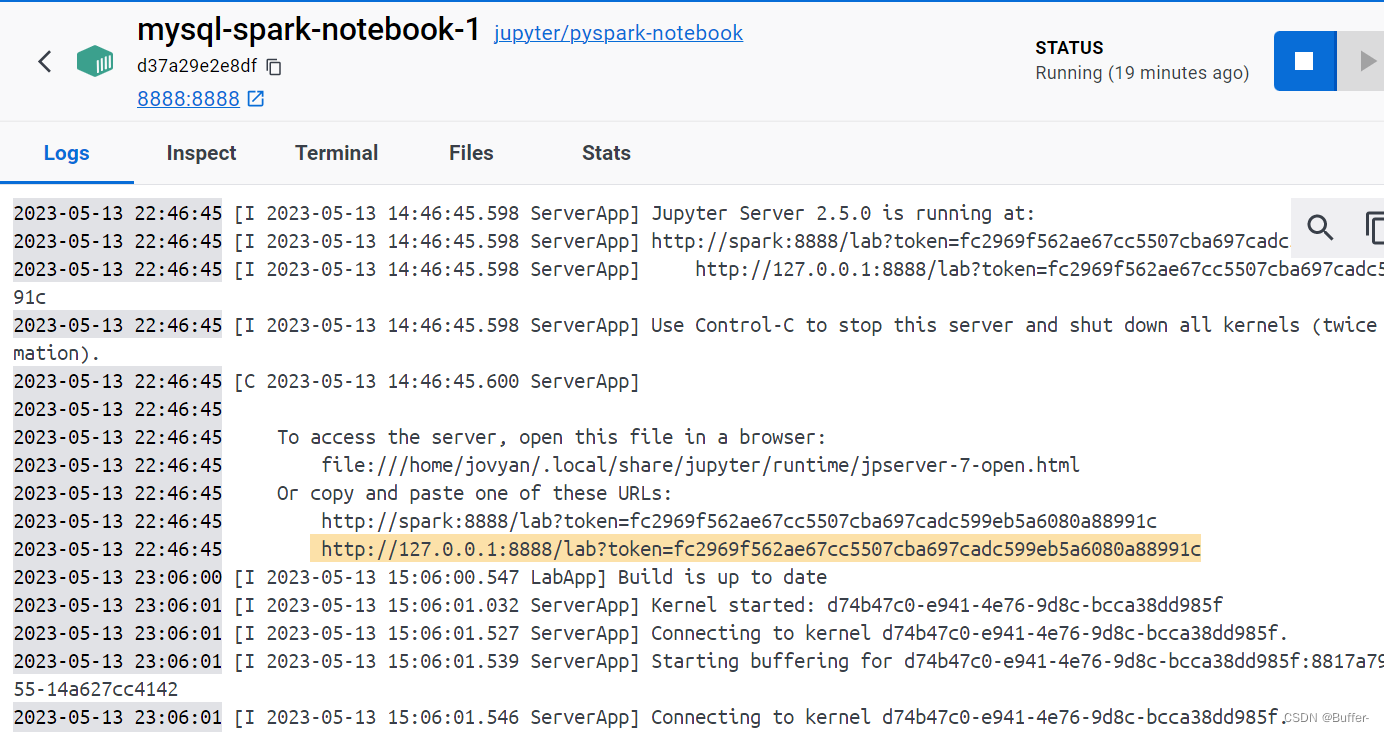
(2)进入Jupyter Notbook
http://127.0.0.1:8888/lab(这个直接在log里点链接就行)
在work目录下新建一个.ipynb文件,执行下面代码:
from pyspark import SparkContext, SparkConf
from pyspark.sql import SparkSession
spark=SparkSession.builder.config(conf=SparkConf()).getOrCreate()
jdbcDF = spark.read \
.format("jdbc") \
.option("driver","com.mysql.jdbc.Driver") \
.option("url", "jdbc:mysql://mysql-mysql-1:3306/spark") \
.option("dbtable", "student") \
.option("user", "root") \
.option("password", "root") \
.load()
内容要与yml文件里的内容保持一致
jdbcDF.show()
返回的结果:
+---+--------+------+---+
| id| name|gender|age|
+---+--------+------+---+
| 1| Xueqian| F| 23|
| 2|Weiliang| M| 24|
+---+--------+------+---+
from pyspark.sql import Row
from pyspark.sql.types import *
#下面设置模式信息
schema = StructType([StructField("id", IntegerType(), True), \
StructField("name", StringType(), True), \
StructField("gender", StringType(), True), \
StructField("age", IntegerType(), True)])
#下面设置两条数据,表示两个学生的信息
studentRDD = spark \
.sparkContext \
.parallelize(["3 Rongcheng M 26","4 Guanhua M 27"]) \
.map(lambda x:x.split(" "))
#下面创建Row对象,每个Row对象都是rowRDD中的一行
rowRDD = studentRDD.map(lambda p:Row(int(p[0].strip()), p[1].strip(), p[2].strip(), int(p[3].strip())))
#建立起Row对象和模式之间的对应关系,也就是把数据和模式对应起来
studentDF = spark.createDataFrame(rowRDD, schema)
studentDF.show()
返回的结果:
+---+---------+------+---+
| id| name|gender|age|
+---+---------+------+---+
| 3|Rongcheng| M| 26|
| 4| Guanhua| M| 27|
+---+---------+------+---+
#写入数据库
prop = {}
prop['user'] = 'root'
prop['password'] = 'root'
prop['driver'] = "com.mysql.jdbc.Driver"
studentDF.write.jdbc("jdbc:mysql://mysql:3306/spark",'student','append', prop)
7、在mysql中查询结果
在powershell中进入mysql
docker exec -it 0d0f2468b1d6 /bin/bash
mysql -u root -p
mysql> use spark;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> select * from student;
+------+-----------+--------+------+
| id | name | gender | age |
+------+-----------+--------+------+
| 1 | Xueqian | F | 23 |
| 2 | Weiliang | M | 24 |
| 3 | Rongcheng | M | 26 |
| 4 | Guanhua | M | 27 |
+------+-----------+--------+------+
4 rows in set (0.00 sec)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









