







一、相同点
HashMap 和 Hashtable 都实现了 Map<K,V>, Cloneable, Serializable 这三个接口
源码如下
public class Hashtable<K,V>
extends Dictionary<K,V>
implements Map<K,V>, Cloneable, java.io.Serializable {
... ...
}public class HashMap<K,V> extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable {
... ...
}二、不同点
1)Hashtable 的 key 和 value 键值对是不允许值为 null,而对于 HashMap,key 和 value 都是可以值为 null
Hashtable 源码如下
可以看到当 value 值为 null 时,会抛出空指针异常; 当 key 值为 null,也不可能有 hasCode( ),所以 key 和 value 在 Hashtable 中不允许为 null.
public synchronized V put(K key, V value) {
// Make sure the value is not null
if (value == null) {
throw new NullPointerException();
}
// Makes sure the key is not already in the hashtable.
Entry<?,?> tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
@SuppressWarnings("unchecked")
Entry<K,V> entry = (Entry<K,V>)tab[index];
for(; entry != null ; entry = entry.next) {
if ((entry.hash == hash) && entry.key.equals(key)) {
V old = entry.value;
entry.value = value;
return old;
}
}
addEntry(hash, key, value, index);
return null;
}HashMap 源码如下
可以看到当 key 的值为 null 时,会转为 0,value 值可以直接为 null.
对于 (h = key.hashCode()) ^ (h >>> 16) 的目的是减少哈希冲突。
什么是哈希冲突?哈希冲突就是在建立哈希表时,两个关键字 key1 和 key2,key1 != key2,但是可能会出现 key1 的哈希值与 key2 相等的情况,这种现象我们称为哈希冲突。
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}2)实现方式不同,Hashtable 继承的是抽象类 Dictionary<K,V>,而 HashMap 继承的是抽类 AbstractMap<K,V>
源码如下
public class Hashtable<K,V>
extends Dictionary<K,V>
implements Map<K,V>, Cloneable, java.io.Serializable {
... ...
}public class HashMap<K,V> extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable {
... ...
}3)Hashtable 支持 Iterator 和 Enumeration 两种遍历方式,而 HashMap 只支持 Iterator 这一种遍历方式
Hashtable 源码如下
private class Enumerator<T> implements Enumeration<T>, Iterator<T> {
... ...
public boolean hasMoreElements() {
Entry<?,?> e = entry;
int i = index;
Entry<?,?>[] t = table;
/* Use locals for faster loop iteration */
while (e == null && i > 0) {
e = t[--i];
}
entry = e;
index = i;
return e != null;
}
@SuppressWarnings("unchecked")
public T nextElement() {
Entry<?,?> et = entry;
int i = index;
Entry<?,?>[] t = table;
/* Use locals for faster loop iteration */
while (et == null && i > 0) {
et = t[--i];
}
entry = et;
index = i;
if (et != null) {
Entry<?,?> e = lastReturned = entry;
entry = e.next;
return type == KEYS ? (T)e.key : (type == VALUES ? (T)e.value : (T)e);
}
throw new NoSuchElementException("Hashtable Enumerator");
}
// Iterator methods
public boolean hasNext() {
return hasMoreElements();
}
public T next() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
return nextElement();
}
... ...
}HashMap 源码如下
abstract class HashIterator {
... ...
public final boolean hasNext() {
return next != null;
}
... ...
}
final class KeyIterator extends HashIterator
implements Iterator<K> {
public final K next() { return nextNode().key; }
}
final class ValueIterator extends HashIterator
implements Iterator<V> {
public final V next() { return nextNode().value; }
}
final class EntryIterator extends HashIterator
implements Iterator<Map.Entry<K,V>> {
public final Map.Entry<K,V> next() { return nextNode(); }
}
4)初始容量不同,Hashtable 的初始容量为 11,而 HashMap 的初始容量为 16,但是两者的负载因子默认的都是 0.75
Hashtable 源码如下
public Hashtable(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal Load: "+loadFactor);
if (initialCapacity==0)
initialCapacity = 1;
this.loadFactor = loadFactor;
table = new Entry<?,?>[initialCapacity];
threshold = (int)Math.min(initialCapacity * loadFactor, MAX_ARRAY_SIZE + 1);
}
public Hashtable(int initialCapacity) {
this(initialCapacity, 0.75f);
}
public Hashtable() {
this(11, 0.75f);
}
public Hashtable(Map<? extends K, ? extends V> t) {
this(Math.max(2*t.size(), 11), 0.75f);
putAll(t);
}HashMap 源码如下
... ...
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
static final float DEFAULT_LOAD_FACTOR = 0.75f;
... ...
public HashMap(int initialCapacity, float loadFactor) {
... ...
this.loadFactor = loadFactor;
... ...
}
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
public HashMap(Map<? extends K, ? extends V> m) {
this.loadFactor = DEFAULT_LOAD_FACTOR;
... ...
}5)当达到临界值时,扩容机制不同,假设两者的当前容量都为 n,那么扩容后,Hashtable 扩容为 2n + 1,而 HashMap 扩容为 2n
临界值(threshold) = 容量(capacity) * 负载因子(loadFactor)
这里我们简单介绍一下什么是负载因子?
当我们不断向 HashMap 或者 Hashtable 中 put 元素时,可能会产生大量的哈希冲突,所以需要自动扩容。
以下是 Hashtable 的扩容源码。同样,当我们利用 HashMap 进行 put 元素到临界值时,HashMap 同样也会扩容。不论是在 Hashtable 还是在 HashMap,当对其进行扩容后,都必须将原先的元素分配到新的地方存储。那么在什么时候扩容就成为了一个问题?
private void addEntry(int hash, K key, V value, int index) {
modCount++;
Entry<?,?> tab[] = table;
if (count >= threshold) {
// Rehash the table if the threshold is exceeded
rehash();
tab = table;
hash = key.hashCode();
index = (hash & 0x7FFFFFFF) % tab.length;
}
// Creates the new entry.
@SuppressWarnings("unchecked")
Entry<K,V> e = (Entry<K,V>) tab[index];
tab[index] = new Entry<>(hash, key, value, e);
count++;
}loadFactor 负载因子,表示 Hashtable 或者 HashMap 容量的饱满程度,默认的负载因子是 0.75,也就是说在 Hashtable 或者 HashMap 中元素容量到达 3/4 的时候开始扩容。
这里我们就会有疑惑,底层的数据结构不是 数组 + 链表 吗,根据 hash 算法可以一直链下去,也就是所谓的拉链法,那为什么还需要扩容呢?
这里就跟我们上面所说到的 哈希冲突 有关~
底层的数据结构 数组 + 链表 可以很好的化解一些哈希冲突问题,但是如果我们不进行扩容,我们 put 的元素越来越多,那么发生哈希冲突的概率就会越来越大,会从一开始的数组链表最后退化为链表,这时就导致查询速度降低。
一开始,元素不多的情况下,如图所示
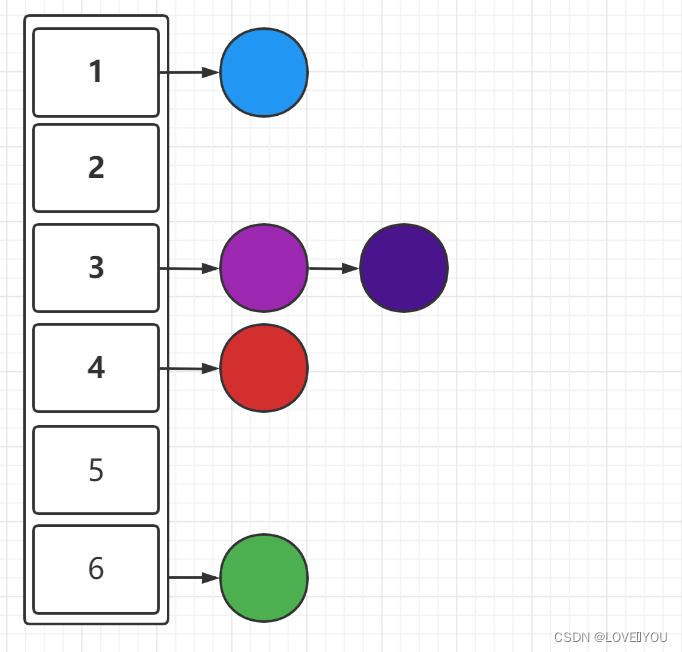
后来,元素慢慢增多,但是不进行扩容,如图所示
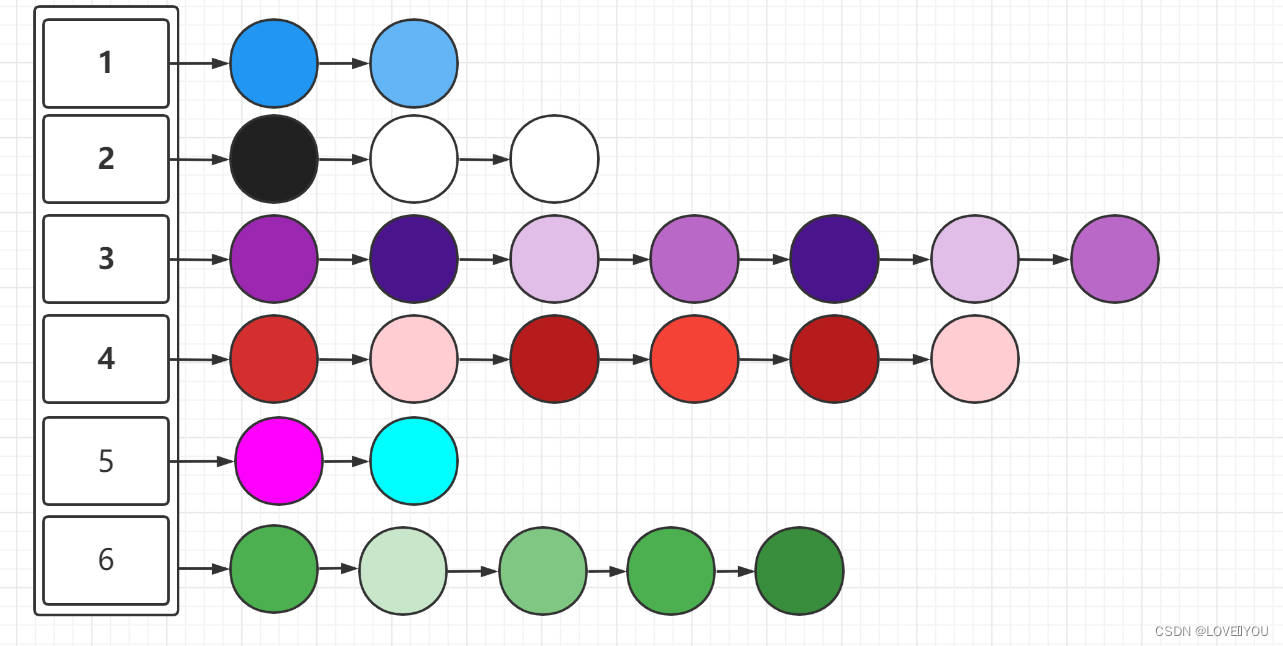
那么,我们应该如何改变这种情况呢?
① 优化 hash 算法(已优化) ② 扩大容量,降低碰撞概率
所以我们需要扩大容量,并在一个特定的临界值下。这样 loadFactor 负载因子就产生了~
那么负载因子的初始值为什么不是其他数值,而是 0.75 呢?
我们可以想到,负载因子不能太大,也不能太小。如果太大,会增加哈希冲突,如果太小,会浪费内存空间,所以经过官方的数学计算和统计,得到了一个在空间和成本上都比较权衡的数据,也就是 0.75,一般情况下,我们不建议去修改这个负载因子的默认值~
Hashtable 源码如下
protected void rehash() {
... ...
Entry<?,?>[] newMap = new Entry<?,?>[newCapacity];
... ...
threshold = (int)Math.min(newCapacity * loadFactor, MAX_ARRAY_SIZE + 1);
... ...
}HashMap 源码如下
static final int MAXIMUM_CAPACITY = 1 << 30;
final Node<K,V>[] resize() {
... ...
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
// 这里将新的容量扩大为原来的两倍 newCap = oldCap << 1
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
// 新的临界值是原先临界值的两倍
newThr = oldThr << 1;
}
else if (oldThr > 0)
newCap = oldThr;
else {
newCap = DEFAULT_INITIAL_CAPACITY;
// 新的临界值计算
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
... ...
return newTab;
}6)Hashtable 线程安全,HashMap 线程不安全
Hashtable 源码如下
我们可以看到 Hashtable 源码中,很多就被 synchronized(同步的) 修饰符修饰,所以可以在多线程环境中安全运行。
public synchronized boolean contains(Object value) { ... }
public synchronized boolean containsKey(Object key) { ... }
public synchronized V get(Object key) { ... }
public synchronized V put(K key, V value) { ... }
public synchronized V remove(Object key) { ... }
... ...HashMap 源码如下
我们可以看到,在 HashMap 中,没有 synchronized 修饰,所以在多线程的情况下可能会产生问题,不建议在多线程使用。如果我们不需要同步且只是在单线程的情况下,那么 HashMap 的性能是要比 Hashtable 的性能要好的。从源码中我们可以看出,HashMap 大量使用的是位运算,而不是简单的乘除。
public boolean containsKey(Object key) { ... }
public V put(K key, V value) { ... }
public V get(Object key) { ... }
public void putAll(Map<? extends K, ? extends V> m) { ... }
public V remove(Object key) { ... }
... ... 7)API存在不同,Hashtable 重写了 toString( ) 方法,并且支持 contains( Object value ),HashMap 没有重写 toString( ) 方法,同时也不支持 contains( Object value )
Hashtable 源码如下
public synchronized String toString() {
int max = size() - 1;
if (max == -1)
return "{}";
StringBuilder sb = new StringBuilder();
Iterator<Map.Entry<K,V>> it = entrySet().iterator();
sb.append('{');
for (int i = 0; ; i++) {
Map.Entry<K,V> e = it.next();
K key = e.getKey();
V value = e.getValue();
sb.append(key == this ? "(this Map)" : key.toString());
sb.append('=');
sb.append(value == this ? "(this Map)" : value.toString());
if (i == max)
return sb.append('}').toString();
sb.append(", ");
}
}
public synchronized boolean contains(Object value) {
if (value == null) {
throw new NullPointerException();
}
Entry<?,?> tab[] = table;
for (int i = tab.length ; i-- > 0 ;) {
for (Entry<?,?> e = tab[i] ; e != null ; e = e.next) {
if (e.value.equals(value)) {
return true;
}
}
}
return false;
}8)在计算 key 的 hash 值时,Hashtable 直接使用的是 hascode( ),HashMap 使用的是自定义的 hash( ) 算法
Hashtable 源码如下
public synchronized V put(K key, V value) {
... ...
int hash = key.hashCode();
... ...
}HashMap 源码如下
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}总结 Hashtable 和 HashMap 的区别
相同点:
HashMap 和 Hashtable 都实现了 Map<K,V>, Cloneable, Serializable 这三个接口
不同点:
1)Hashtable 的 key 和 value 键值对是不允许值为 null,而对于 HashMap,key 和 value 都是可以值为 null
2)实现方式不同,Hashtable 继承的是抽象类 Dictionary<K,V>,而 HashMap 继承的是抽类 AbstractMap<K,V>
3)Hashtable 支持 Iterator 和 Enumeration 两种遍历方式,而 HashMap 只支持 Iterator 这一种遍历方式
4)初始容量不同,Hashtable 的初始容量为 11,而 HashMap 的初始容量为 16,但是两者的负载因子默认的都是 0.75
5)当达到临界值时,扩容机制不同,假设两者的当前容量都为 n,那么扩容后,Hashtable 扩容为 2n + 1,而 HashMap 扩容为 2n
临界值(threshold) = 容量(capacity) * 负载因子(loadFactor)
6)Hashtable 线程安全,HashMap 线程不安全
7)API存在不同,Hashtable 重写了 toString( ) 方法,并且支持 contains( Object value ),HashMap 没有重写 toString( ) 方法,同时也不支持 contains( Object value )
8)在计算 key 的 hash 值时,Hashtable 直接使用的是 hascode( ),HashMap 使用的是自定义的 hash( ) 算法


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









