






数据结构
JDK1.8 之前 HashMap 底层是 数组和链表 结合在一起使用也就是 链表散列。HashMap 通过 key 的 hashcode 经过hash方法处理过后得到 hash 值,然后通过 (n - 1) & hash 判断当前元素存放的位置(这里的 n 指的是数组的长度),如果当前位置存在元素的话,就判断该元素与要存入的元素的 hash 值以及 key 是否相同,如果相同的话,直接覆盖,不相同就通过拉链法解决冲突。
hash+数组的所组成的结构叫做散列表。
在最好的情况下我们可以直接O(1)的时间复杂度就能直接查出来,虽然说一个好的hash算法能够平均分布从而减少冲突的概率,但是冲突始终是无法避免的。
在Java中int类型是4个字节,也就是32个二进制位组成,那它们发生冲突的概率是4,294,967,296分之一。对于这一点我们不用太过于担心,但是实际情况是我们结构中是一个数组,但是我们生成的int值它的取值范围则是-2^31 ~ 2^31-1 ,而我们计算机的内容空间是一个有限的,不可能分配这么大一块连续的内存空间,像HashMap默认容量也就16个,那就极有可能会发生hash冲突了。
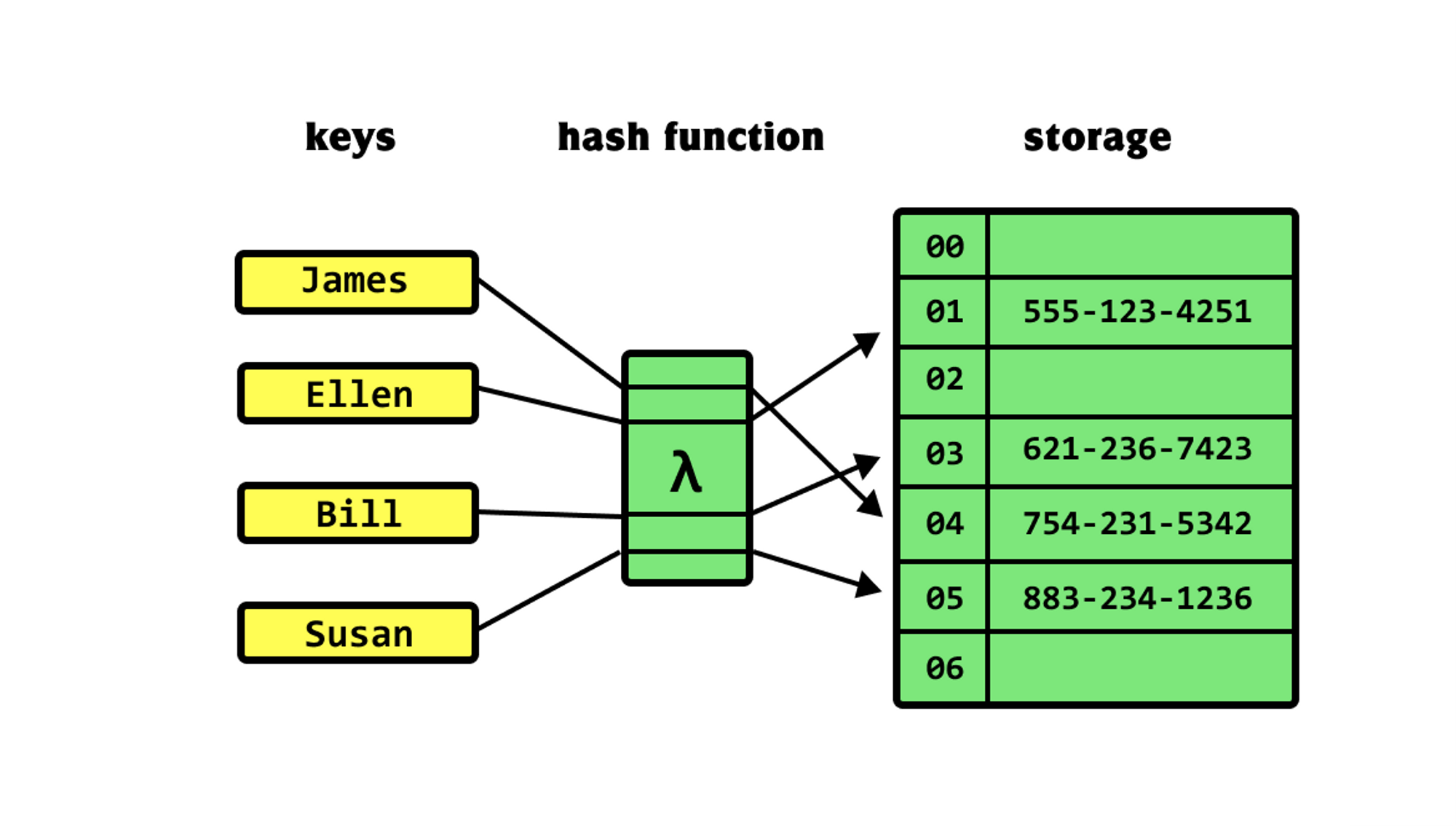
如何解决散列冲突问题呢?
链地址法不论是在我们HashMap还是Redis中都是通过这种方案来解决Hash冲突的。在散列表中,每个“桶”或者“槽”会对应一条链表,所有散列值相同的元素我们都放到相同槽位对应的链表中。
看下图:
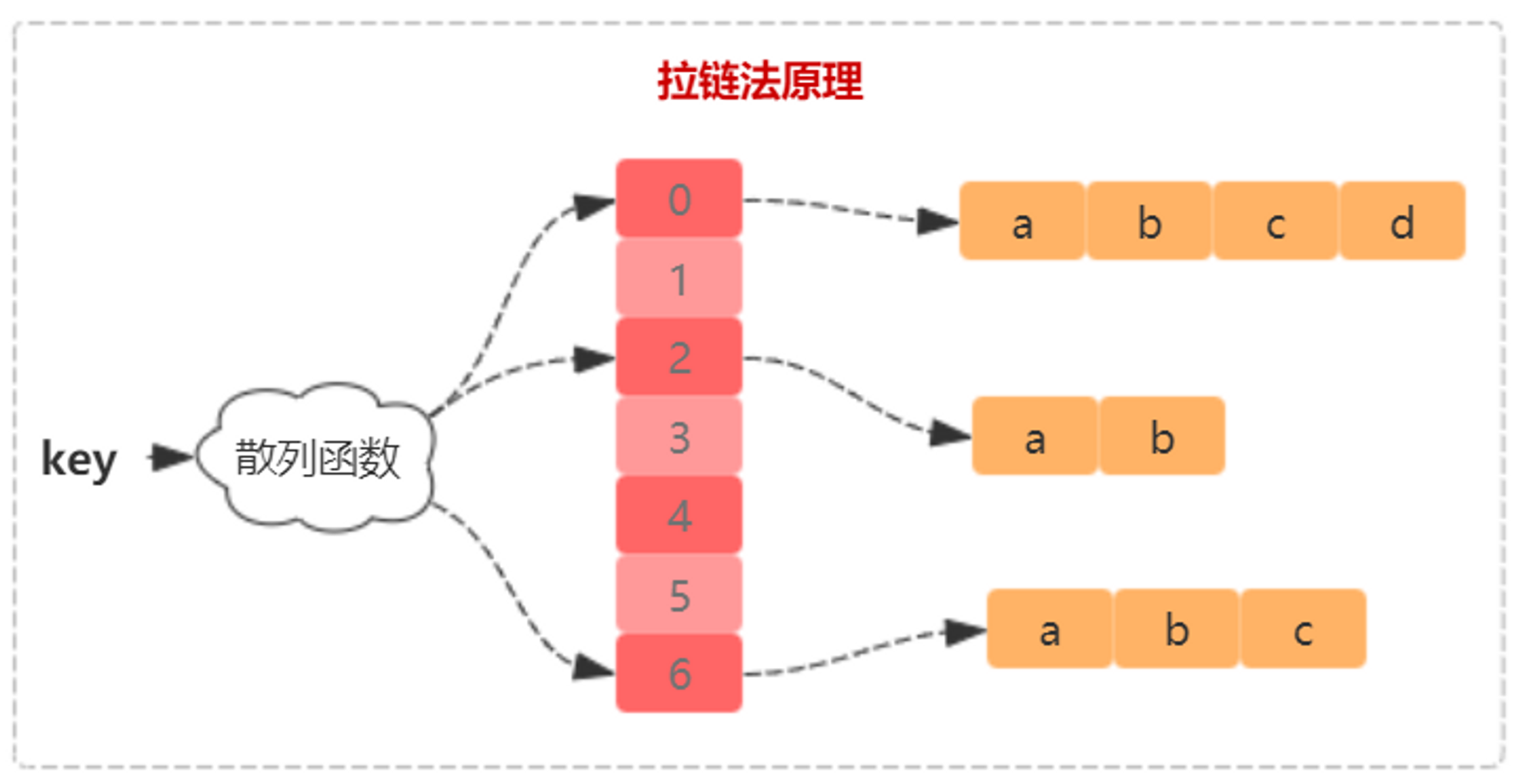
当插入的时候,我们只要通过散列函数计算出对应的散列槽位,将其插入到对应链表中即可,所以插入的时间复杂度是O(1)。当查找、删除一个元素时,我们同样通过散列函数计算出对应的槽,然后遍历链表查找或者删除。那查找或删除操作的时间复杂度是多少呢?
实际上,这两个操作的时间复杂度跟链表的长度 k 成正比,也就是 O(k)。对于散列比较均匀的散列函数来说,理论上讲,k=n/m,其中 n 表示散列中数据的个数,m 表示散列表中“槽”的个数。
这个是一般状态下的链地址法,而在JDK7中HashMap就是这么实现的,但是到了JDK8就发生了一些改变,我们先来说说为什么要改?
第一印象肯定是对比两者的时间复杂度,链表最差是O(N)而红黑树是稳定的O(log(N)) ,能得出来的结论大部分场景下红黑树的查询效率比链表高和更加稳定。但是树形结构的增删改成本会更高一点,涉及到了树的不断左旋右旋。红黑树之后说。
将高十六位无符号右移之后与低十六位做异或运算使得高十六位的特征与低十六位的特征进行了混合得到的新的数值中就高位与低位的信息都被保留了 ,而在这里采用异或运算而不采用& ,| 运算的原因是 异或运算能更好的保留各部分的特征,如果采用&运算计算出来的值会向1靠拢,采用|运算计算出来的值会向0靠拢,通过这种方式我们可以进一步提升hashcode的离散性,使得结果分布更加均匀,也能减少hash碰撞。
事实上除了右移和异或之外hashmap获取下标前还有一步操作。它就是按位与&,那按位与是做什么用的呢?我们来看下面一段代码:
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
...
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
...重点看这段:[i = (n - 1) & hash]这段代码是摘自HashMap的put方法,也就是通过hash获取下标为的这段代码。这段代码的意思就是通过按位与代替取模运算,按位与操作的运算效率比取模运算会快很多,位运算可以直接对内存数据进行操作,不需要进行进制转换,取模转换是10进制数据取模,而位运算直接是2进制操作,按照测试的效率大概是快了接近30倍。
[i = (n - 1) & hash] = [i = hash % (n - 1)]但是按位与会有一个前提就是N必须是2的N次方,为什么按位与可以代替取模运算呢?
一个数对 2^N取模相当于一个数和 (2^n - 1) 做按位与运算 。假设N为3,则 2^3 = 8,表示成2进制就是1000。2^3-1=7 ,即 0111。此时X & (2^3 - 1)就相当于取 X 的 2 进制的最后三位数。
从2进制角度来看,X / 8 相当于 X >> 3,即把 X 右移3位,此时得到了X / 8的商,而被移掉的部分(后三位),则是X % 8,也就是余数。
举个例子:
// 比如hashmap的初始长度值是16,那么(length - 1)就是15
// 假设hashcode的值为8,那么转换成2进制就是 1000
i = 8 %(16 - 1)
i = 8
// 我们再用按位与计算一次,按位与操作,结果为1匀为1否则为0, 是不是结果都是一样的
i = 15 & 8
15 = 1111
8 = 1000
i = 1000 = 8接下来我们尝试多保留几位,并推导出公式
| 保留位数 | 取余操作公式 | 与操作公式 |
| 1 | A % 2 | A & 1 |
| 2 | A % 4 | A & 3 |
| 3 | A % 8 | A & 7 |
| 4 | A % 16 | A & 15 |
| ~~~ | ~~~ | ~~~ |
| n | A % 2^n | A & (2^n - 1) |
这种方法仅在对一个的数做取余操作时才可用。而我们hashmap的扩容始终都是2的N次方,那也就完全支持使用位运算。至此,我们hash获取下标的问题就解决了。
所谓的hash 方法,就是使用hashCode()方法。
JDK 1.8 HashMap 的 hash 方法源码:
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
/**
* hashCode()比较的是哈希码,哈希码是由特定的哈希算法的出
* 通过某一种算法得到的,hashcode就是在hash表中有对应的位置
* ^:按位异或 两个值不同即为1否则为0
* >>>:无符号右移,忽略符号位,空位都以0补齐
* int占8个字节 即32位
* 解释 h >>> 16 无符号右移16位
* 比如说 h =978456 补齐32位
* h的二进制为 0000 0000 0000 1110 1110 1110 0001 1000
* h >>> 16 后为 0000 0000 0000 0000 0000 0000 0000 1110
* 这两个值进行 ^: 0000 0000 0000 1110 1110 1110 0001 0110
*/JDK1.7
static int hash(int h) {
// This function ensures that hashCodes that differ only by
// constant multiples at each bit position have a bounded
// number of collisions (approximately 8 at default load factor).
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
JDK1.8 之后
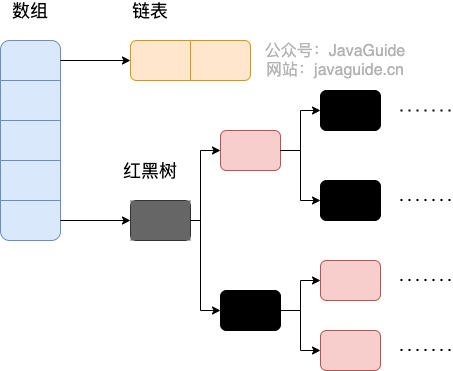
相比于之前的版本, JDK1.8 之后在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为 8)(将链表转换成红黑树前会判断,如果当前数组的长度小于 64,那么会选择先进行数组扩容,而不是转换为红黑树)时,将链表转化为红黑树,以减少搜索时间。
著作权归Guide所有 原文链接:https://javaguide.cn/java/collection/java-collection-questions-02.html#hashmap-%E7%9A%84%E5%BA%95%E5%B1%82%E5%AE%9E%E7%8E%B0
源码解析
核心常量
// 默认容量
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
// 最大容量
static final int MAXIMUM_CAPACITY = 1 << 30;
// 负数因子 即容量被使用了75%就扩容
static final float DEFAULT_LOAD_FACTOR = 0.75f;
//链表转红黑树的阈值 当链表长度大于8的时候会使用红黑树(这个是其中一个条件)
static final int TREEIFY_THRESHOLD = 8;
//转化红黑树最小容量
static final int MIN_TREEIFY_CAPACITY = 64;
// 红黑树退化链表阈值
static final int UNTREEIFY_THRESHOLD = 6;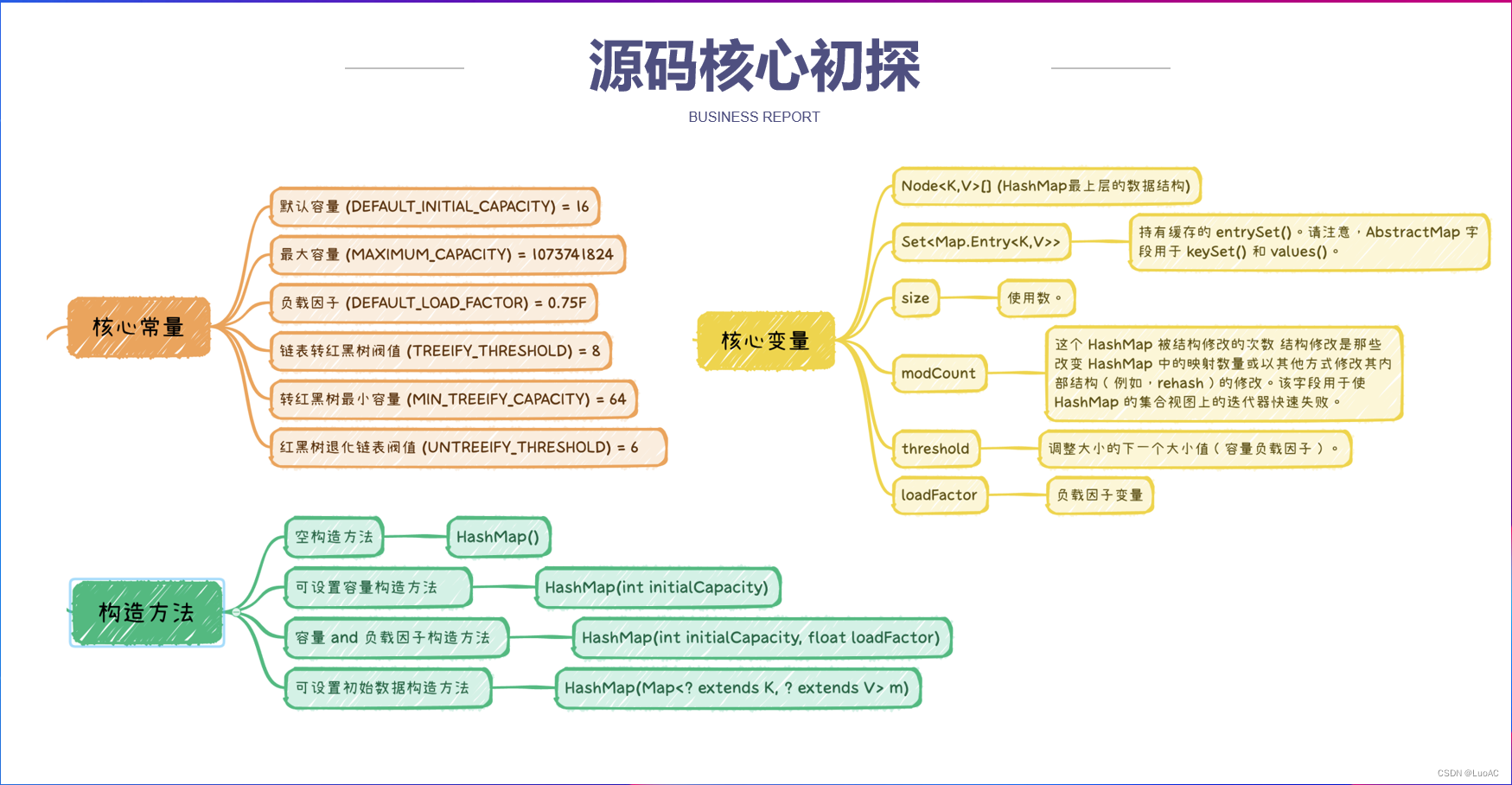


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









