







 本文围绕Java微服务展开,详细介绍了Eureka服务注册中心,包括单节点与集群配置、架构原理等;阐述了Ribbon负载均衡,涵盖多种策略及设置方法;还介绍了Consul服务注册中心和Feign声明式服务调用,包含其原理、入门案例、负载均衡、请求传参及性能优化等内容。
本文围绕Java微服务展开,详细介绍了Eureka服务注册中心,包括单节点与集群配置、架构原理等;阐述了Ribbon负载均衡,涵盖多种策略及设置方法;还介绍了Consul服务注册中心和Feign声明式服务调用,包含其原理、入门案例、负载均衡、请求传参及性能优化等内容。
1. Eureka服务注册中心
1.1 Eureka 入门案例 单节点配置

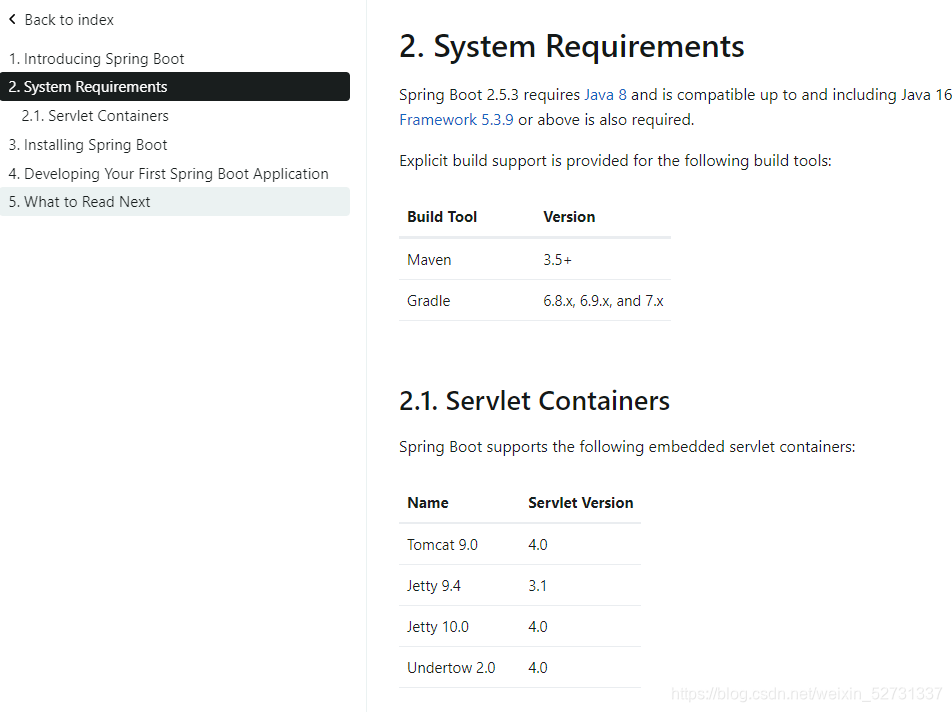
springcloud 版本 2020.0.3
需要springboot 版本 2.4.6 以上 2.5.3
springboot所需
maven 3.5 以上 3.6.1
java8 以上 java 8
Spring Framework 5.3.9
Tomcat 9.0
父依赖文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.hardy</groupId>
<artifactId>eureka-demo</artifactId>
<packaging>pom</packaging>
<version>1.0-SNAPSHOT</version>
<modules>
<module>eureka-server</module>
</modules>
<!--
继承spring-boot-starter-parent 依赖
使用继承的方式 实现复用 符合继承的都可以被使用
-->
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.5.3</version>
</parent>
<!--
集中定义依赖组件版本号,但不引入
在子工程中用到声明的依赖时,可以不加依赖的版本号
这样可以统一管理工程中用到的依赖版本
-->
<properties>
<!--spring cloud 2020.0.3 依赖 -->
<spring-cloud.version>2020.0.3</spring-cloud.version>
</properties>
<!--项目依赖管理 父项目只是声明依赖 子项目需要写明需要的依赖-->
<dependencyManagement>
<dependencies>
<!--springcloud依赖 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>${spring-cloud.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
</project>
eureka server 依赖文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.hardy</groupId>
<artifactId>eureka-server</artifactId>
<version>1.0-SNAPSHOT</version>
<!--继承父依赖 -->
<parent>
<groupId>com.hardy</groupId>
<artifactId>eureka-demo</artifactId>
<version>1.0-SNAPSHOT</version>
</parent>
<!-- 项目依赖 -->
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-server</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
<exclusions>
<exclusion>
<groupId>org.junit.vintage</groupId>
<artifactId>junit-vintage-engine</artifactId>
</exclusion>
</exclusions>
</dependency>
</dependencies>
</project>
配置文件
server:
port: 8761 #端口
spring:
application:
name: eureka-server #应用名称
#配置 eureka server注册中心
eureka:
instance:
hostname: localhost #主机名,不配置的时候就根据操作系统的主机名来获取
client:
#单节点 就不用自己给自己注册 集群环境下 注册中心相互注册
register-with-eureka: false #是否将自己注册到注册中心,默认为true
#拉取信息
fetch-registry: false #是否从注册中心获取服务注册信息 默认为true
service-url: #注册中心对外暴露的注册地址
defaultZone: http://${eureka.instance.hostname}:${server.port}/eureka/
1.2 Eureka集群配置
server:
port: 8761 #端口
spring:
application:
name: eureka-server #应用名称
#配置 eureka server注册中心
eureka:
instance:
hostname: eureka01 #主机名,不配置的时候就根据操作系统的主机名来获取
prefer-ip-address: true #是否使用ip地址注册
instance-id: ${spring.cloud.client.ip-address}:${server.port}
client:
#设置服务注册中心的地址,指向另一个注册中心
service-url: #注册中心对外暴露的注册地址
defaultZone: http://localhost:8762/eureka/
server:
port: 8762 #端口
spring:
application:
name: eureka-server #应用名称
#配置 eureka server注册中心
eureka:
instance:
hostname: eureka02 #主机名,不配置的时候就根据操作系统的主机名来获取
prefer-ip-address: true #是否使用ip地址注册
instance-id: ${spring.cloud.client.ip-address}:${server.port}
client:
#设置服务注册中心的地址,指向另一个注册中心
service-url: #注册中心对外暴露的注册地址
defaultZone: http://localhost:8761/eureka/
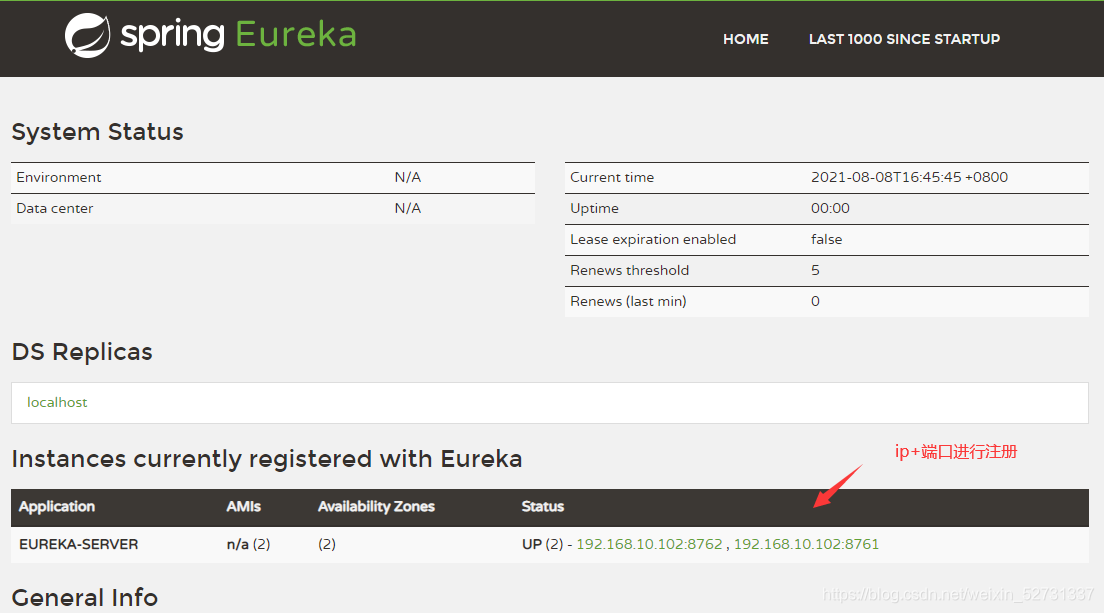
1.2.1 集群下 Provider 配置
项目依赖在之前的基础上,添加client 和 lombok
<!-- netflix-eureka-client 依赖 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
1.2.2 集群下 Consumer 配置
server:
port: 9090 #端口
spring:
application:
name: service-consumer #应用名称
#配置 消费端 仅仅作为一个消费者
eureka:
client:
register-with-eureka: false # 是否将自己注册到注册中心 false
registry-fetch-interval-seconds: 10 #表示eureka client 间隔多久去服务器拉取注册信息 默认为30S
service-url: #设置服务注册中心地址
defaultZone: http//localhost:8761/eureka/,http://localhost:8762/eureka/
1.2.1关于消费服务 三种实现方式
- 通过元数据获取服务信息
- Ribbon 的负载均衡器 loadBalanceClient
- 通过注解开启 Ribbon 的负载均衡器 @loadBalanceClient
通过元数据 DiscoveryClient
OrderServiceImpl
@Service
/**
* 订单服务
*/
public class OrderServiceImpl implements OrderService{
@Autowired //模板对象
private RestTemplate restTemplate;
@Autowired //元数据对象 springframework 下的
private DiscoveryClient discoveryClient;
@Override
public Order selectOrderById(Integer id) {
return new Order(id,"order-001","中国",31990D,selectProductListByDiscoveryClient());
}
private List<Product> selectProductListByDiscoveryClient(){
StringBuffer sb = null; //线程安全的字符串拼接处理的对象
//获取服务列表
List<String> services = discoveryClient.getServices();
if(CollectionUtils.isEmpty(services))
return null;
//根据服务名称获取服务
List<ServiceInstance> instances = discoveryClient.getInstances("service-provider");
if(CollectionUtils.isEmpty(instances))
return null;
ServiceInstance si = instances.get(0);
sb = new StringBuffer();
sb.append("http://"+si.getHost()+":"+si.getPort()+"/product/list");
//ResponseEntity :封装了 返回的数据 Entity:实体
ResponseEntity<List<Product>> response = restTemplate.exchange(
sb.toString(),
HttpMethod.GET,
null,
new ParameterizedTypeReference<List<Product>>() {}
);
return response.getBody();
}
}
通过Ribbon 的负载均衡器 loadBalanceClient 实现
@Service
/**
* 订单服务
*/
public class OrderServiceImpl implements OrderService{
@Autowired //模板对象
private RestTemplate restTemplate;
@Autowired //元数据对象 springframework 下的
private DiscoveryClient discoveryClient;
@Autowired
private LoadBalancerClient loadBalancerClient;
@Override
public Order selectOrderById(Integer id) {
return new Order(id,"order-001","中国",31990D,selectProductListByLoadBalancerClient());
}
private List<Product> selectProductListByLoadBalancerClient(){
StringBuffer sb = null; //线程安全的字符串拼接处理的对象
//用来拼接出服务地址
//根据服务名称获取服务
ServiceInstance si = loadBalancerClient.choose("service-provider");
if(null == si)
return null;
sb = new StringBuffer();
sb.append("http://"+si.getHost()+":"+si.getPort()+"/product/list");
//ResponseEntity :封装了 返回的数据 Entity:实体
ResponseEntity<List<Product>> response = restTemplate.exchange(
sb.toString(),
HttpMethod.GET,
null,
new ParameterizedTypeReference<List<Product>>() {}
);
return response.getBody();
}
}
- 基于注解实现:
- 在启动类@LoadBalanced
@SpringBootApplication
public class ServiceConsumerApplication {
@Bean
@LoadBalanced //负载均衡注解
public RestTemplate restTemplate(){
return new RestTemplate();
}
public static void main(String[] args) {
SpringApplication.run(ServiceConsumerApplication.class,args);
}
}
- 注解版:OrderServiceImpl
@Service
public class OrderServiceImpl implements OrderService{
@Autowired //模板对象
private RestTemplate restTemplate;
@Override
public Order selectOrderById(Integer id) {
return new Order(id,"order-001","中国",31990D,selectProductListByLoadBalancerAnnotation());
}
private List<Product> selectProductListByLoadBalancerAnnotation(){
//ResponseEntity :封装了 返回的数据 Entity:实体
ResponseEntity<List<Product>> response = restTemplate.exchange(
"http://service-provider/product/list",
HttpMethod.GET,
null,
new ParameterizedTypeReference<List<Product>>() {}
);
return response.getBody();
}
}
1.3 Eureka 架构原理
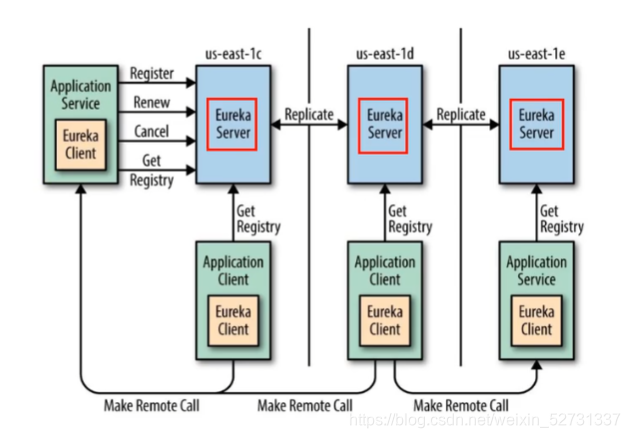
application service 相当于 provider
application client 相当于 consumer
| Register(服务注册) | 把自己的ip和端口注册给 Eureka |
|---|---|
| Renew(服务续约) | 发送心跳包,每30S发送一次,告诉Eureka自己还活着,如果90S还没有发送心跳,宕机 |
| Get Register(获取服务注册列表) | 获取其他服务列表 |
| Replicate(集群中数据同步) | Eureka集群中的数据复制与同步 |
| Make Remote call(远程调用) | 完成服务的远程调用 |
| Cancel | 撤销 ,主动下线 不会触发保护模式 |
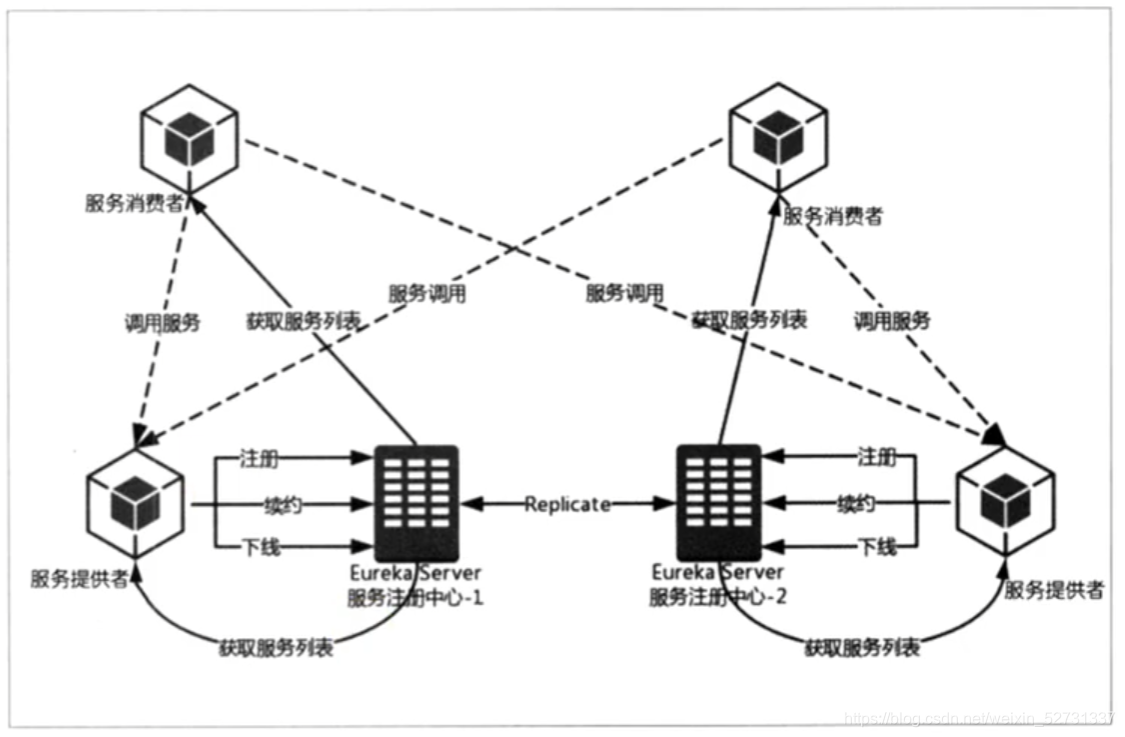
1.4 CAP原则
CAP猜想 : 我们构建应用的时候只能尽量满足两个,不可能三者同时兼得 两年论证证明是正确的
C:一致性 consistency
A:可用性 applicability
P:分区容错 Partition-Tolerance
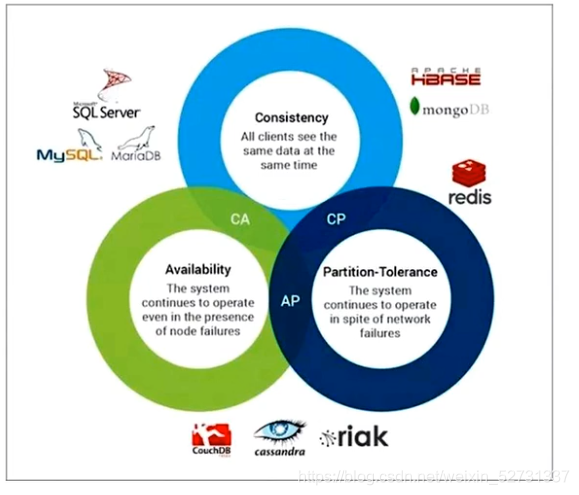
| CA | 假设应用做到了数据一致性(必定更耗时),和服务并且能及时的相应,也做到了高可用 ----> 一定是单节点居多 没有办法分区扩展 |
| CP | 假设应用保证了 数据的一致性,又做了分区容错 ,在进行数据一致处理的时候,分区之间内部通信必定需要消耗时间,那必然响应的比较慢,也就牺牲了用户体验度 |
| AP | 假设服务高度可用又分区容错,走任一节点,拿到数据就立即返回,那一致性也就必然的差了 比如秒杀,抢消费券 下单或支付的时候再处理 订单失效。。。 |
| 金融 | 小型的CA 大型的CP |
| 互联网 | AP 保证用户的体验度 后台稍作处理 |
常见的注册中心
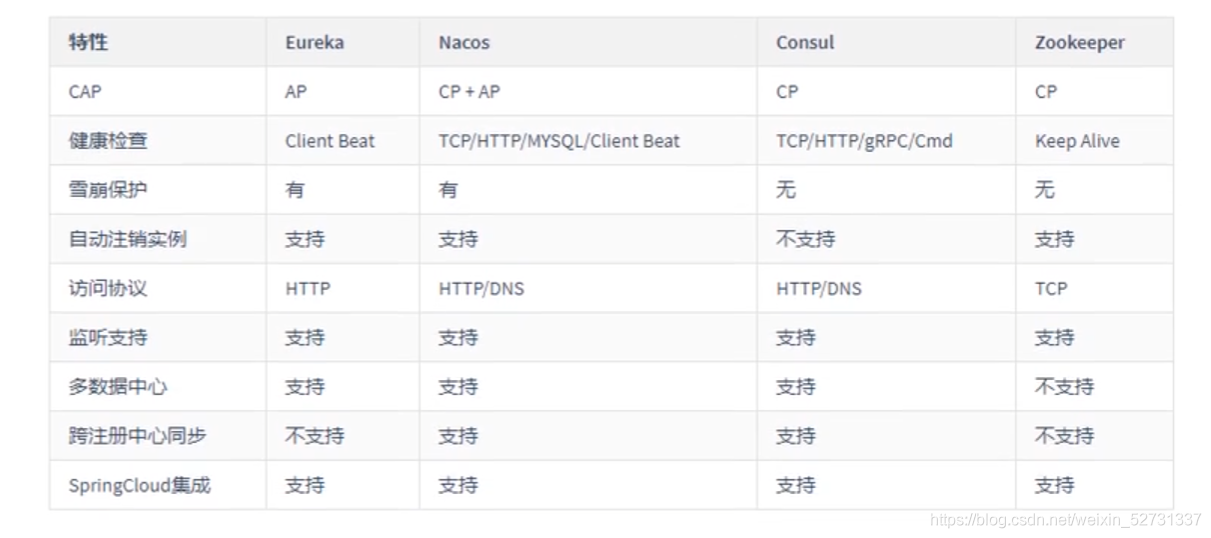
| 特性 | Eureka | Nacos | Consul | zookeeper |
|---|---|---|---|---|
| CAP | AP | CP+AP | CP | CP |
总结:没有最好的策略,只有最合适的策略
CA 一般是关系型数据库
CP/AP 一般是非关系型数据库
1.5 Eureka 自我保护
一般情况下,服务在Eureka上注册后,通过renew发送心跳 判断服务是否可用,每30秒发送心跳包,Eureka通过心跳判断服务是否健康,同时会定期删除90秒没有心跳的服务。
1.5.1 自我保护模式
Eureka Server 在运行期间会统计每15分钟之内的心跳,判断单次失败比例是否低于85%。如果低于85%,Eureka Server会将服务保护起来,让这些实例不过期,同时发送一个警告。这种算法叫做Eureka Server的自我保护模式。
1.5.2 如何关闭自我保护
eureka:
server:
enable-self-preservation: false #
eviction-interval-timer-in-ms: 60000 #清理间隔(毫秒)1分钟
1.6 Eureka 优雅停服
配置了优雅停服之后,将不需要Eureka Server中配置关闭自我保护。本文使用actuator实现
- 在provider的pom中导入依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
- 配置文件
#度量指标监控与健康检查
management:
endpoints:
web:
exposure:
include: shutdown #开启 shutdown 端点访问
endpoint:
shutdown:
enabled: true #开启shutdown 实现优雅停服
- 优雅停服
使用post请求访问:http://localhost:7070/actuator/shutdown
provider 马上就会被停掉
1.7 Eureka 安全认证
注册中心pom中添加依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-security</artifactId>
</dependency>
- 配置文件
spring:
#安全认证
security:
user:
name: root
password: 123456
登录页面也需要改动 采用账号密码+@的方式
注册中心
服务提供者
服务消费者 都需要改动
例如:
defaultZone: http://root:123456@localhost:8762/eureka/
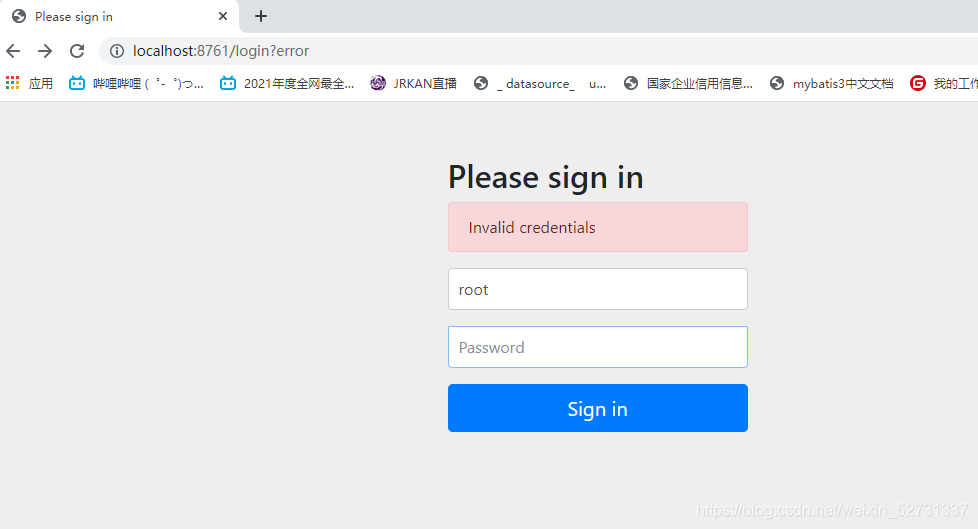
登录成功后,即使启动所有服务,但依然没有注册中心和服务注册,他们相互之间还没有建立连接,需要过滤SCRF
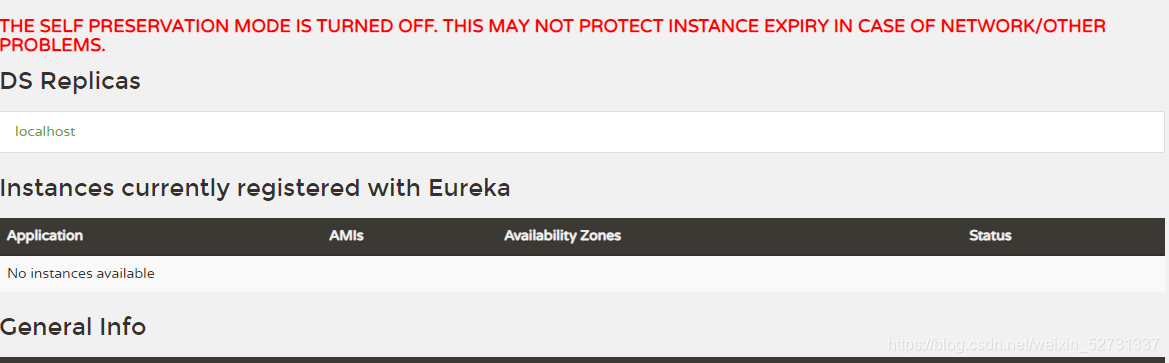
1.7.2 过滤SCRF
Eureka会自动配置CSRF防御机制,Spring Security 认为post、put,andDELETE http methods 都是有风险的。
如果这些method发送过程中没有带上CSRF token 的话,会直接被拦截并返回403 forbidden

- 方案一 安全系数较高
使CSRF忽略/eureka/** 的所有请求
package com.hardy.config;
import org.springframework.security.config.annotation.web.builders.HttpSecurity;
import org.springframework.security.config.annotation.web.configuration.EnableWebSecurity;
import org.springframework.security.config.annotation.web.configuration.WebSecurityConfigurerAdapter;
@EnableWebSecurity
public class WebSecurityConfig extends WebSecurityConfigurerAdapter {
@Override
protected void configure(HttpSecurity http) throws Exception {
super.configure(http);//加这句是为了访问 eureka 控制台 和 /actuator时能做安全控制
http.csrf().ignoringAntMatchers("/eureka/**");
}
}
- 方案二 安全系数较低
保持密码验证的同时,禁用CSRF防御机制
package com.hardy.config;
import org.springframework.security.config.annotation.web.builders.HttpSecurity;
import org.springframework.security.config.annotation.web.configuration.EnableWebSecurity;
import org.springframework.security.config.annotation.web.configuration.WebSecurityConfigurerAdapter;
@EnableWebSecurity
public class WebSecurityConfig extends WebSecurityConfigurerAdapter {
@Override
protected void configure(HttpSecurity http) throws Exception {
//注意 如果直接disable的话 会把安全验证也禁用掉 没有安全登录页了
http.csrf().disable().authorizeRequests()
.anyRequest()
.authenticated()
.and()
.httpBasic();
}
}
2. Ribbon 负载均衡
2.1 学习目标
2.2 什么是Ribbon
Ribbon是一个基于HTTP和TCP的客户端 负载均衡工具,它是基于 Netflix Ribbon实现的
它不像 Spring Cloud 服务注册中心、配置中心、API网关那样独立部署,但是它几乎存在于每个Spring Cloud 微服务中,包括Feign 提供的声明式服务调用也是基于Ribbon实现的。
Ribbon 默认提供多种负载均衡算法,如:轮询,随机等等。甚至包括自定义的负载均衡算法。
2.3 Ribbon解决了什么问题
Ribbon提供了一套微服务的负载均衡解决方案
2.4 负载均衡不同方案的区别
目前。业界主流的负载均衡方案可分为两类:
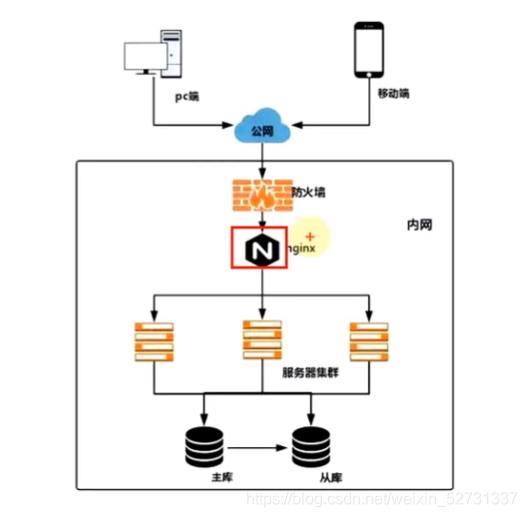
- 集中式负载均衡(服务器级别的负载均衡):即在consumer和provider之间使用独立的负载均衡设施(可以是硬件 如F5,也可以是软件 如Nginx),由该设施负责把访问的请求通过某种策略转发至provider。服务器级别的负载均衡。
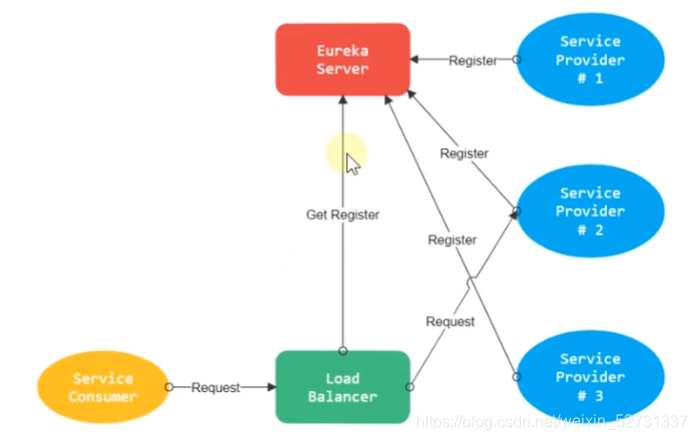
- 进程内负载均衡(客户端负载均衡):将负载均衡逻辑集成到consumer,consumer从服务注册中心拉取可用地址,选择一个合适的provider。Ribbon就是这种,它只是一个类库,集成于consumer进程,consumer通过它来获取provider的地址。业务当中不同服务之间的调用
2.4.1 集中式负载均衡(服务器级别的负载均衡)
2.4.2 进程内负载均衡(业务级别的负载均衡)
2.5 Ribbon负载均衡策略
2.5.1 轮询策略(默认)
- 策略对应类名 : RoundRobbinRule
- 实现原理:轮询策略表示每次都顺序取下一个provider,比如一共有5个provider,第1次取第1个,第2次取第2个,第3次取第3个,以此类推。
2.5.2 权重轮询策略
- 策略对应类名 : WeightedResponseTimeRule
- 根据每个provider的响应时间分配一个权重,响应时间越长,权重越小,被选中的可能性就越低
- 原理:一开始为轮询策略,并开启一个计时器,每30秒收集一次每个provider的平均响应时间,当信息量足够时,给每个provider附上一个权重,并按权重随机选择provider,权重高的provider选中的概率也就越高。
2.5.3 随机策略
- 策略对应类名 : RandomRule
- 实现原理:从provider列表中随机选择一个
2.5.4 最少并发数策略
- 策略对应类名 : BestAvailableRule
- 实现原理:选择正在请求中国的并发数最小的provider,除非这个provider在熔断中
2.5.5 重试策略
- 策略对应类名 : RetryRule
- 实现原理:其实就是轮询策略的增强版,轮询策略服务不可用时不作处理,重试策略服务不可用时会重新尝试集群中的其他节点
2.5.6 可用性敏感策略
- 策略对应类名 : AvailabilityFilteringRule
- 实现原理:过滤性能差的provider
- 第一种:过滤掉在Eureka 中处于一直连接失败的 provider
- 第二种:过滤掉高并发(繁忙)的provider
2.5.7 区域敏感性策略
- 策略对应类名 : ZoneAvoidanceRule
- 实现原理:
- 以一个区域为单位考查可用性,对于不可用的区域整个丢弃,从剩下区域中选可用的provider
- 如果这个IP区域内有一个或者多个实例不可达或者响应变慢,都会降低该IP区域内其他IP被选中的权重。
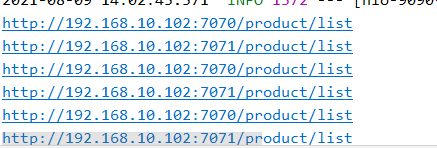
2.6 Ribbon 入门案例
Ribbon 中对于集群的服务采用的负载均衡策略默认是轮询
- 创建service-provider02 依赖不变
- 在服务消费者consumer中业务采用loadBalancerClient
- 这个在中间会拼接出地址
sb.append("http://"+si.getHost()+":"+si.getPort()+"/product/list");
多次访问http://localhost:9090/order/1 可以看到默认策略是轮询
2.7 Ribbon 负载均衡策略设置
2.7.1 全局
在启动类或配置类中注入负载均衡策略对象。所有服务请求均使用该策略
@Bean
public RandomRule randomRule(){
return new RandomRule();
}
多次访问http://localhost:9090/order/1
2.7.2 局部
修改配置文件指定服务的负载均衡策略。
#负载均衡策略
#service-provider 为调用服务的名称
service-provider:
ribbon:
NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RandomRule
多次访问http://localhost:9090/order/1
2.8 Ribbon 点对点直连
点对点直连是指绕过注册中心,直接连接服务提供者获取服务,一般在测试阶段使用比较多。
注掉eureka 依赖

注掉eureka 配置

##负载均衡策略
#service-provider 为调用服务的名称
service-provider:
ribbon:
NFLoadBalancerRuleClassName: com.netflix.loadbalance.RandomRule
#指定具体的provider 服务
listOfServers: http://localhost:7070,http://localhost:7071
#关闭 Eureka 实现点对点直连
ribbon:
eureka:
enabled: false;
3. Consul服务注册中心
3.1 学习目标
3.2 常见的注册中心

3.3 Consul介绍

3.4 Consul特性

3.5 Consul角色
- dev : 开发模式
- client:客户端,无状态,将 HTTP和 DNS接口请求转发始局域网内的服务端集群。
- server:服务端,保存配置信息,高可用集群,每个数据中心的server数量推荐为3个或者5个。
3.6 Consul工作原理
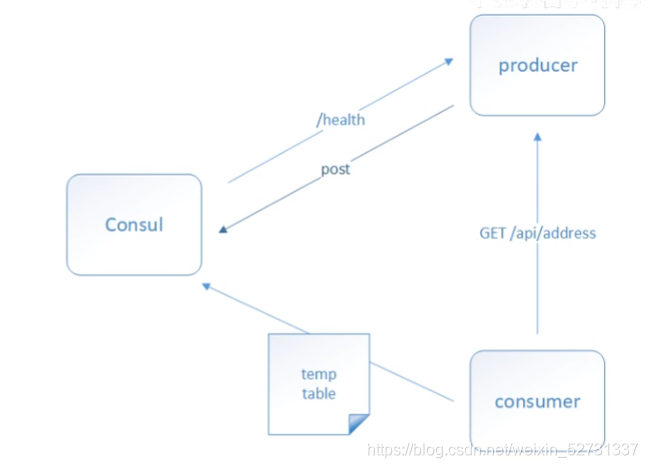
3.6.1 服务的发现以及注册
- 当服务 Producer启动时,会将自己的Ip/host等信息通过发送请求告知Consul,Consul接收到 Producer的注册信息后,每隔10s (默认)会向 Producer发送—个健康检查的请求。检验 Producer是否健康。
3.6.2 服务的调用
- 当Consumer请求 Product时,会先从Consul 中拿到存储Product 服务的I沪P和Port的临时表([temp table),从temp table表中任选一个-Producer的IP和Port,然后根据这个IP和Port,发送访问清求:
- temp table表只包含通过了健康检查的 Producer信息,并且每隔10s(默认)更新。
3.7 Consul安装
默认端口号8500
http://localhost:8500/ui/dc1/services
3.8 Consul入门案例
依赖
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.5.3</version>
</parent>
<properties>
<spring-cloud.version>2020.0.3</spring-cloud.version>
</properties>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>${spring-cloud.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
3.8.1 服务的提供者 service-provider
<parent>
<groupId>com.hardy</groupId>
<version>1.0-SNAPSHOT</version>
<artifactId>consul-demo</artifactId>
</parent>
<dependencies>
<!-- spring-cloud-consul 依赖 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-consul-discovery</artifactId>
</dependency>
<!-- spring-boot-actuator 依赖 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
<exclusions>
<exclusion>
<groupId>org.junit.vintage</groupId>
<artifactId>junit-vintage-engine</artifactId>
</exclusion>
</exclusions>
</dependency>
配置文件
server:
port: 7070
spring:
application:
name: service-provider
#配置consul 注册中心
cloud:
consul:
#注册中心访问地址
host: localhost
port: 8500
#服务提供者信息
discovery:
register: true #是否需要注册
instance-id: ${spring.application.name}-01 #注册实例ID (必须唯一)
service-name: ${spring.application.name} #服务,名称
port: ${server.port} #服务端口
prefer-ip-address: true #是否使用IP地址注册
ip-address: ${spring.cloud.client.ip-address} #服务请求IP
3.8.2 服务的消费者 service-consumer
依赖相同,配置微调
server:
port: 9090
spring:
application:
name: service-consumer
#配置consul 注册中心
cloud:
consul:
#注册中心访问地址
host: localhost
port: 8500
#服务提供者信息
discovery:
register: false #是否需要注册
instance-id: ${spring.application.name}-01 #注册实例ID (必须唯一)
service-name: ${spring.application.name} #服务,名称
port: ${server.port} #服务端口
prefer-ip-address: true #是否使用IP地址注册
ip-address: ${spring.cloud.client.ip-address} #服务请求IP
3.9 Consul集群
4.Feign 声明式服务调用
4.1 学习目标
4.2 什么是Feign
- Feign是Spring Cloud Netflix组件中的一个轻量级RESTful的HTTP服务客户端,实现了负载均衡和Rest调用的开源框架,封装了Ribbon和RestTemplate,实现了webService的面向接口编程,进一步降低了项目的耦合度。
- Feign内置了Ribbon,用来做客户端负载均衡调用服务注册中心的服务。
- Feign本身并不支持Spring MVc的注解,它有一套自己的注解,为了更方便的使用,Spring Cloud孵化了OpenFeign.
- Feign是—种声明式、模板化的 HTTP有户端(仅在Consumer中使用).
- Feign支持的注解和用法请参考官方文档: https://github.com/OpenFeign/feign或spring.io官网文档
- Feign的使用方式是:使用Feign的注解定义接口,调用这个接口,就可以调用服务注册中心的服务。
4.3 Feign 解决什么问题
-
Feign旨在使编写JAVA HTTP客户端变得更加容易,Feign简化了RestTemplate代码,实现了Ribbon负载均衡,使代码变得更加简洁,也少了客户端调用的代码,使用Feign实现负载均衡是首选方案。只需要你创建一个接口,然后在上面添加注解即可。
-
Feign是声明式服务调用组件,其核心就是:像调用本地方法一样调用远程方法,无感知远程HTTP请求。
-
它解决了让开发者调用远程接口就跟调用本地方法一样的体验,开发者完全感知不到这是远程方法,更感知不到这是个HTTP请求。无需关注与远程的交互细节,更无需关注分布式环境开发。
-
它像Dubbo—样,Consumer直接调用Provider接口方法,而不需要通过常规的Http Client构造请求再解析返回数据。
4.4 Feign vs OpenFeign
- OpenFeign是Spring Cloud 在Feign的基础上支持了Spring Mvc的注解,如@RequesMapping 、 @Pathvariable等等
- OpenFeign的 @FeignClient 可以解析SpringMVc的@RequestMapping注解下的接口,并通过动态代理的方式产生实现类,实现类中做负载均衡并调用服务。
4.5 Feign 入门案例
Feign的使用主要分为以下几个步骤:
- 服务消费者添加Feign依赖;
- 创建业务层接口,添加@FeignClient注解声明需要调用的服务;
- 业务层抽象方法使用SpringMVC 注解配置服务地址及参数;
- 启动类添加@EnableFeignClients 注解激活Feign组件。
4.5.1 创建项目
4.5.2 添加依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>
4.5.3 注册中心 eureka-server
4.5.4 服务提供者 service-provider
还是用eureka的项目,要注掉安全依赖和配置类,并修改配置
4.5.5 服务消费者 service-consumer
/**
* 订单服务
*/
@Service
public class OrderServiceImpl implements OrderService {
@Autowired
private ProductService productService;
@Override
public Order selectOrderById(Integer id) {
return new Order(id,"order-001","中国",31990D,productService.selectProductList());
}
}
4.6 Feign 负载均衡
- Feign封装了Ribbon自然也就集成了负载均衡的功能,默认采用轮询策略。如何修改负载均衡策略呢?与之前学习Ribon时讲解的配置是—致的。
4.6.1 全局
@Bean
public RandomRule randomRule(){
return new RandomRule();
}
4.6.2 局部
##负载均衡策略
#service-provider 为调用服务的名称
service-provider:
ribbon:
NFLoadBalancerRuleClassName: com.netflix.loadbalance.RandomRule
4.7 Feign 请求传参
4.7.1 GET
- 使用@PathVariable注解或**@RequestParam注解**接收请求参数。
4.7.2 POST
- 使用@RequestBody注解接收请求参数。
4.8 Feign 性能优化
4.8.1 Gzip 压缩
- 局部
- 全局
server:
port: 9090 #端口
#配置Gzip压缩
compression:
enabled: true
mime-types: application/json,application/xml,text/html,text/xml,text/plain
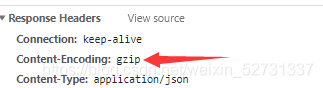
4.8.2 HTTP 连接池
- HTTP连接池
为什么HTTP连接池能提升性能?
- HTTP的背景原理
- 两台服务器建立HTTP连接的过程是很复杂的一个过程,涉及到多个数据包的交换,很耗时间。。
- HTTP连接需要的3次握手4次挥手开销很大,这一开销对于大量的比较小的HTTP消息来说更大。
- 解决方案
采用HTTP连接池,可以节约大量的3次握手4次挥手,这样能大大提升吞吐量。
Feign的HTTP客户端支持3种框架: HttpURLConnection 、HttpClient , OkHttp;默认是HttpURLConnection ,可以通过查看源码FeignRibbonClientAutoConfiguration.java得知
传统的 HtpURLConnection 是JDK自带的,并不支持连接池,如果要实现连接池的机制,还需要自己来管理连接对象。对于网络请求这种底层相对复杂的操作,如果有可用的其他方案,没有必要自己去管理连接对象。
HttpClient相比传统JDK自带的HttpURLConnection,它封装了访问HTTP的请求头,参数,内容体,响应等等;它不仅使客户端发送HTTP请求变得容易,而且也方便了开发人员测试接口(基于HTTP协议的),既提高了开发的效率,又提高了代码的健壮性;另外高并发大量的请求网络的时候,也是用""连接池"提升吞吐量.
导入依赖
<!--feign-httpclient依赖 -->
<dependency>
<groupId>io.github.openfeign</groupId>
<artifactId>feign-httpclient</artifactId>
<version>11.6</version>
</dependency>
4.8.3 状态查看
浏览器发起的请求我们可以借助F12 Devtools 中的
Network来查看请求和响应信息。对于微服务中每个接口我们又该如何查看URL,状态码和耗时信息?我们可以使用配置日志的方式进行查看。
日志文件
<?xml version="1.0" encoding="UTF-8"?>
<!-- 从高到地低 OFF 、 FATAL 、 ERROR 、 WARN 、 INFO 、 DEBUG 、 TRACE 、 ALL -->
<!-- 日志输出规则 根据当前ROOT 级别,日志输出时,级别高于root默认的级别时 会输出 -->
<!-- 以下 每个配置的 filter 是过滤掉输出文件里面,会出现高级别文件,依然出现低级别的日志信息,通过filter 过滤只记录本级别的日志-->
<!-- 属性描述 scan:性设置为true时,配置文件如果发生改变,将会被重新加载,默认值为true scanPeriod:设置监测配置文件是否有修改的时间间隔,如果没有给出时间单位,默认单位是毫秒。当scan为true时,此属性生效。默认的时间间隔为1分钟。
debug:当此属性设置为true时,将打印出logback内部日志信息,实时查看logback运行状态。默认值为false。 -->
<configuration scan="true" scanPeriod="60 seconds" debug="false">
<contextName>my_logback</contextName>
<!-- 定义日志文件 输入位置 -->
<property name="log.path" value="${catalina.base}/service2-consumer/logs" />
<!-- 日志最大的历史 30天 -->
<property name="maxHistory" value="30"/>
<!-- ConsoleAppender 控制台输出日志 -->
<appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender">
<!-- 对日志进行格式化 -->
<encoder>
<pattern>%d{yyyy-MM-dd HH:mm:ss} [%thread] %-5level %logger -%msg%n</pattern>
</encoder>
</appender>
<!-- ERROR级别日志 -->
<!-- 滚动记录文件,先将日志记录到指定文件,当符合某个条件时,将日志记录到其他文件 RollingFileAppender-->
<appender name="ERROR" class="ch.qos.logback.core.rolling.RollingFileAppender">
<!-- 过滤器,只记录WARN级别的日志 -->
<filter class="ch.qos.logback.classic.filter.LevelFilter">
<level>ERROR</level>
<onMatch>ACCEPT</onMatch>
<onMismatch>DENY</onMismatch>
</filter>
<!-- 最常用的滚动策略,它根据时间来制定滚动策略.既负责滚动也负责出发滚动 -->
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<!--日志输出位置 可相对、和绝对路径 -->
<fileNamePattern>${log_dir}/%d{yyyy-MM-dd}/error-log.log</fileNamePattern>
<!-- 可选节点,控制保留的归档文件的最大数量,超出数量就删除旧文件假设设置每个月滚动,且<maxHistory>是6,
则只保存最近6个月的文件,删除之前的旧文件。注意,删除旧文件是,那些为了归档而创建的目录也会被删除-->
<maxHistory>${maxHistory}</maxHistory>
</rollingPolicy>
<!-- 按照固定窗口模式生成日志文件,当文件大于20MB时,生成新的日志文件。窗口大小是1到3,当保存了3个归档文件后,将覆盖最早的日志。
<rollingPolicy class="ch.qos.logback.core.rolling.FixedWindowRollingPolicy">
<fileNamePattern>${log_dir}/%d{yyyy-MM-dd}/.log.zip</fileNamePattern>
<minIndex>1</minIndex>
<maxIndex>3</maxIndex>
</rollingPolicy> -->
<!-- 查看当前活动文件的大小,如果超过指定大小会告知RollingFileAppender 触发当前活动文件滚动
<triggeringPolicy class="ch.qos.logback.core.rolling.SizeBasedTriggeringPolicy">
<maxFileSize>5MB</maxFileSize>
</triggeringPolicy> -->
<encoder>
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger - %msg%n</pattern>
</encoder>
</appender>
<!-- WARN级别日志 appender -->
<appender name="WARN" class="ch.qos.logback.core.rolling.RollingFileAppender">
<!-- 过滤器,只记录WARN级别的日志 -->
<filter class="ch.qos.logback.classic.filter.LevelFilter">
<level>WARN</level>
<onMatch>ACCEPT</onMatch>
<onMismatch>DENY</onMismatch>
</filter>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<!-- 按天回滚 daily -->
<fileNamePattern>${log_dir}/%d{yyyy-MM-dd}/warn-log.log
</fileNamePattern>
<!-- 日志最大的历史 60天 -->
<maxHistory>${maxHistory}</maxHistory>
</rollingPolicy>
<encoder>
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger - %msg%n</pattern>
</encoder>
</appender>
<!-- INFO级别日志 appender -->
<appender name="INFO" class="ch.qos.logback.core.rolling.RollingFileAppender">
<!-- 过滤器,只记录INFO级别的日志 -->
<filter class="ch.qos.logback.classic.filter.LevelFilter">
<level>INFO</level>
<onMatch>ACCEPT</onMatch>
<onMismatch>DENY</onMismatch>
</filter>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<!-- 按天回滚 daily -->
<fileNamePattern>${log_dir}/%d{yyyy-MM-dd}/info-log.log
</fileNamePattern>
<!-- 日志最大的历史 60天 -->
<maxHistory>${maxHistory}</maxHistory>
</rollingPolicy>
<encoder>
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger - %msg%n</pattern>
</encoder>
</appender>
<!-- DEBUG级别日志 appender -->
<appender name="DEBUG" class="ch.qos.logback.core.rolling.RollingFileAppender">
<!-- 过滤器,只记录DEBUG级别的日志 -->
<filter class="ch.qos.logback.classic.filter.LevelFilter">
<level>DEBUG</level>
<onMatch>ACCEPT</onMatch>
<onMismatch>DENY</onMismatch>
</filter>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<!-- 按天回滚 daily -->
<fileNamePattern>${log_dir}/%d{yyyy-MM-dd}/debug-log.log
</fileNamePattern>
<!-- 日志最大的历史 60天 -->
<maxHistory>${maxHistory}</maxHistory>
</rollingPolicy>
<encoder>
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger - %msg%n</pattern>
</encoder>
</appender>
<!-- TRACE级别日志 appender -->
<appender name="TRACE" class="ch.qos.logback.core.rolling.RollingFileAppender">
<!-- 过滤器,只记录ERROR级别的日志 -->
<filter class="ch.qos.logback.classic.filter.LevelFilter">
<level>TRACE</level>
<onMatch>ACCEPT</onMatch>
<onMismatch>DENY</onMismatch>
</filter>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<!-- 按天回滚 daily -->
<fileNamePattern>${log_dir}/%d{yyyy-MM-dd}/trace-log.log
</fileNamePattern>
<!-- 日志最大的历史 60天 -->
<maxHistory>${maxHistory}</maxHistory>
</rollingPolicy>
<encoder>
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger - %msg%n</pattern>
</encoder>
</appender>
<logger name="java.sql.PreparedStatement" value="DEBUG" />
<logger name="java.sql.Connection" value="DEBUG" />
<logger name="java.sql.Statement" value="DEBUG" />
<logger name="com.ibatis" value="DEBUG" />
<logger name="com.ibatis.common.jdbc.SimpleDataSource" value="DEBUG" />
<logger name="com.ibatis.common.jdbc.ScriptRunner" level="DEBUG"/>
<logger name="com.ibatis.sqlmap.engine.impl.SqlMapClientDelegate" value="DEBUG" />
<!-- root级别 DEBUG -->
<root level="debug">
<!-- 控制台输出 -->
<appender-ref ref="STDOUT" />
<!-- 文件输出 -->
<appender-ref ref="ERROR" />
<appender-ref ref="INFO" />
<appender-ref ref="WARN" />
<appender-ref ref="DEBUG" />
<appender-ref ref="TRACE" />
</root>
</configuration>
全局
/**
* NONE:不记录任何信息,默认值
* BASIC:记录请求方法、请求URL、状态码和用时
* HEADERS:在BASIC基础上再记录一些常用信息
* FULL:记录请求和相应的所有信息
* @return
*/
@Bean
public Logger.Level getLog(){
return Logger.Level.FULL;
}
4.8.4 请求超时
Feign的负载均衡底层用的就是Ribbon,所以这里的请求超时配置其实就是配置Ribbon.
分布式项目中,服务压力比较大的情况下,可能处理服务的过程需要花费一定的时间,而默认情况下请求超时的配置是1s所以我们需要调整该配置廷长请求超时时间。
全局
consumer项目中配置请求超时的处理
ribbon:
Connect: 5000 #请求连接的超拍时间默认的时间为1秒
ReadTimeout: 5000 #请求处理的超时间
局部
##负载均衡策略
#service-provider 为调用服务的名称
service-provider:
ribbon:
NFLoadBalancerRuleC1assName: com.netflix.loadbalancer.RandomRule
OkToRetryOnA110perations: true #对所有请求都进行重试
MaxAutoRetries: 2 #对当前实例的重试次数
MaxAutoRetriesNextServer: 0 #切换实例的重试次数
ConnectTimeout: 3000 #请求连接的超时时间
ReadTimeout: 3000 #请求处理的超时时间


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









