







 本文分析了2019年亚马逊畅销书籍数据集,包括书籍的名称、作者、评分、评论数、价格、出版年份和类型等信息。发现评论最多的书籍主要为小说,价格集中在0到20美元,评论数在0到40000之间,评分中位数为4.6,表明大多数书籍口碑良好。Gary Chapman在non-fiction排名中表现最佳,而Jeff Kinney在fiction排名中最多产。评论数与评分及价格呈正相关。
本文分析了2019年亚马逊畅销书籍数据集,包括书籍的名称、作者、评分、评论数、价格、出版年份和类型等信息。发现评论最多的书籍主要为小说,价格集中在0到20美元,评论数在0到40000之间,评分中位数为4.6,表明大多数书籍口碑良好。Gary Chapman在non-fiction排名中表现最佳,而Jeff Kinney在fiction排名中最多产。评论数与评分及价格呈正相关。
sale ranking analysis
01 | 数据集
kaggle:
https://www.kaggle.com/sootersaalu/amazon-top-50-bestselling-books-2009-2019
这是一份来自kaggle的数据集,内容是亚马逊2019年书籍的销售数据。通过pd.read_csv读取数据内容,查看columns。
Index([‘Name’, ‘Author’, ‘User Rating’, ‘Reviews’, ‘Price’, ‘Year’, ‘Genre’]
数据集包括书籍名称、作者、评分、评论数、价格、出版年份、类型这几个参数。
import pandas as pd
df = pd.read_csv(r'D:\pycharm\data\bestsellers with categories.csv')
print(df.columns)
02 | columns分析
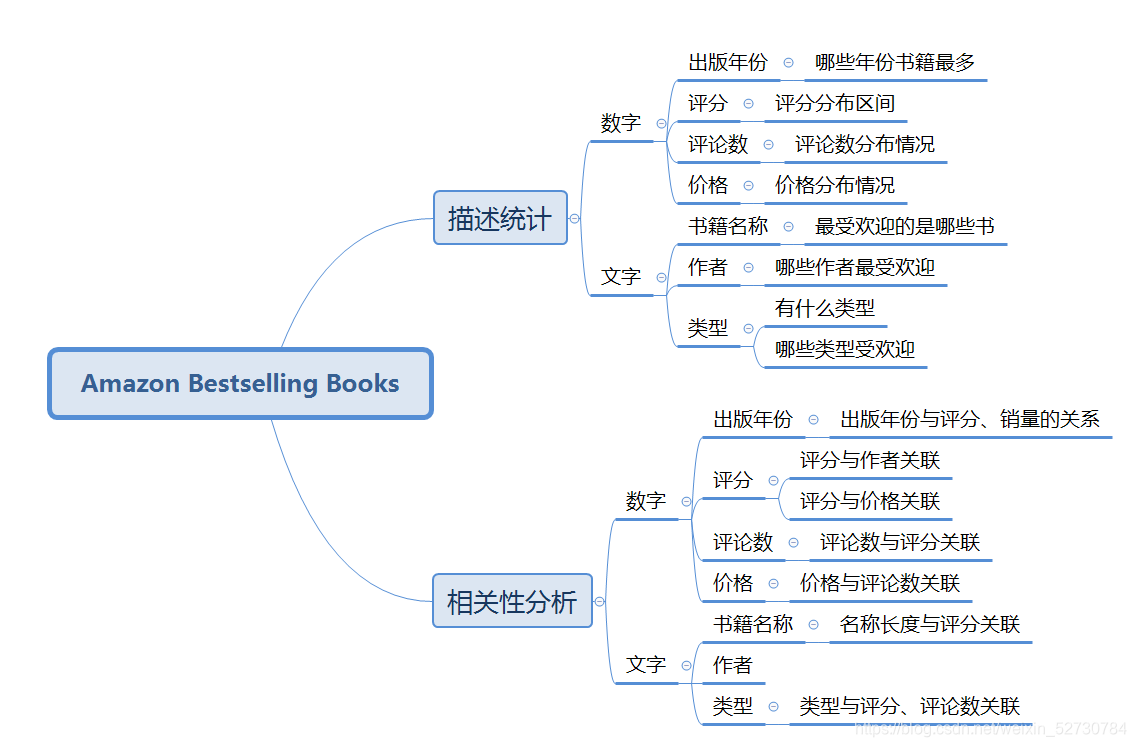
03 | 代码
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from collections import Counter
from pyecharts.charts import Line
from pyecharts import options as opts
pd.set_option('display.max_columns',1000)
pd.set_option('display.width',1000)
pd.set_option('display.max_colwidth',1000)
plt.rcParams['font.sans-serif'] = ['SimHei']
sns.set_style('whitegrid',{
'font.sans-serif':['simhei','Arial']})
'''
1.查看数据
'''
df = pd.read_csv(r'D:\pycharm\data\bestsellers with categories.csv')
print(df.info())
print(df.describe())
print(df.head())
'''
2.描述统计
'''
# 查看Genre
genre = df['Genre'].value_counts 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









