







文章目录
MySQL之InnoDB索引
注:本文基于Linux系统上MySQL v8.0.26进行讲解
1.索引分类、区别
而在在InnoDB存储引擎中,根据索引的存储形式,又可以分为以下两种:
聚集索引(ClusteredIndex)==聚簇索引
二级索引(SecondaryIndex)==辅助索引==非聚集索引==非聚簇索引
2.聚集索引
聚集索引(ClusteredIndex):
将数据存储与索引放到了一块,索引结构的叶子节点保存了行数据,即聚集索引的叶子节点下挂的是这一行的数据;
一个表中必须有聚集索引,而且只有一个
聚集索引选取规则:
如果存在主键,主键索引就是聚集索引。
如果不存在主键,将使用第一个唯一(UNIQUE)索引作为聚集索引。
如果表没有主键,或没有合适的唯一索引,则InnoDB会自动生成一个6字节长整型的rowid字段来构建索引,作为隐藏的聚集索引。rowid字段在插入新行时自动递增
3.二级索引
二级索引(SecondaryIndex):
除聚簇索引之外的所有索引都称为辅助索引。
索引结构的叶子节点关联的是对应的主键,即二级索引的叶子节点下挂的是该字段值对应的主键值;
可以存在多个二级索引
4.索引区别
在 InnoDB 里,索引B+ Tree的叶子节点存储了整行数据的是主键索引,也被称之为聚簇索引,即将数据存储与索引放到了一块,找到索引也就找到了数据。
而索引B+ Tree的叶子节点存储了主键的值的是非主键索引,也被称之为非聚簇索引、二级索引。
聚簇索引与非聚簇索引的区别:
1.非聚集索引与聚集索引的区别在于非聚集索引的叶子节点不存储表中的数据,而是存储该列对应的主键(行号)
2.对于InnoDB来说,想要查找数据我们还需要根据主键再去聚集索引中进行查找,这个再根据聚集索引查找数据的过程,我们称为回表。第一次索引一般是顺序IO,回表的操作属于随机IO。需要回表的次数越多,即随机IO次数越多,我们就越倾向于使用全表扫描 。
3.通常情况下, 主键索引(聚簇索引)查询只会查一次,而非主键索引(非聚簇索引)需要回表查询多次。当然,如果是覆盖索引的话,查一次即可
5.演示(聚集索引、二级单列普通索引、等值查询、回表查询)
id是主键,主键索引就是聚集索引,叶子节点下面挂的数据就是它所对应的那一行的数据(行数据),比如5下面挂的row就是“id=5 name = Kit gender=男”
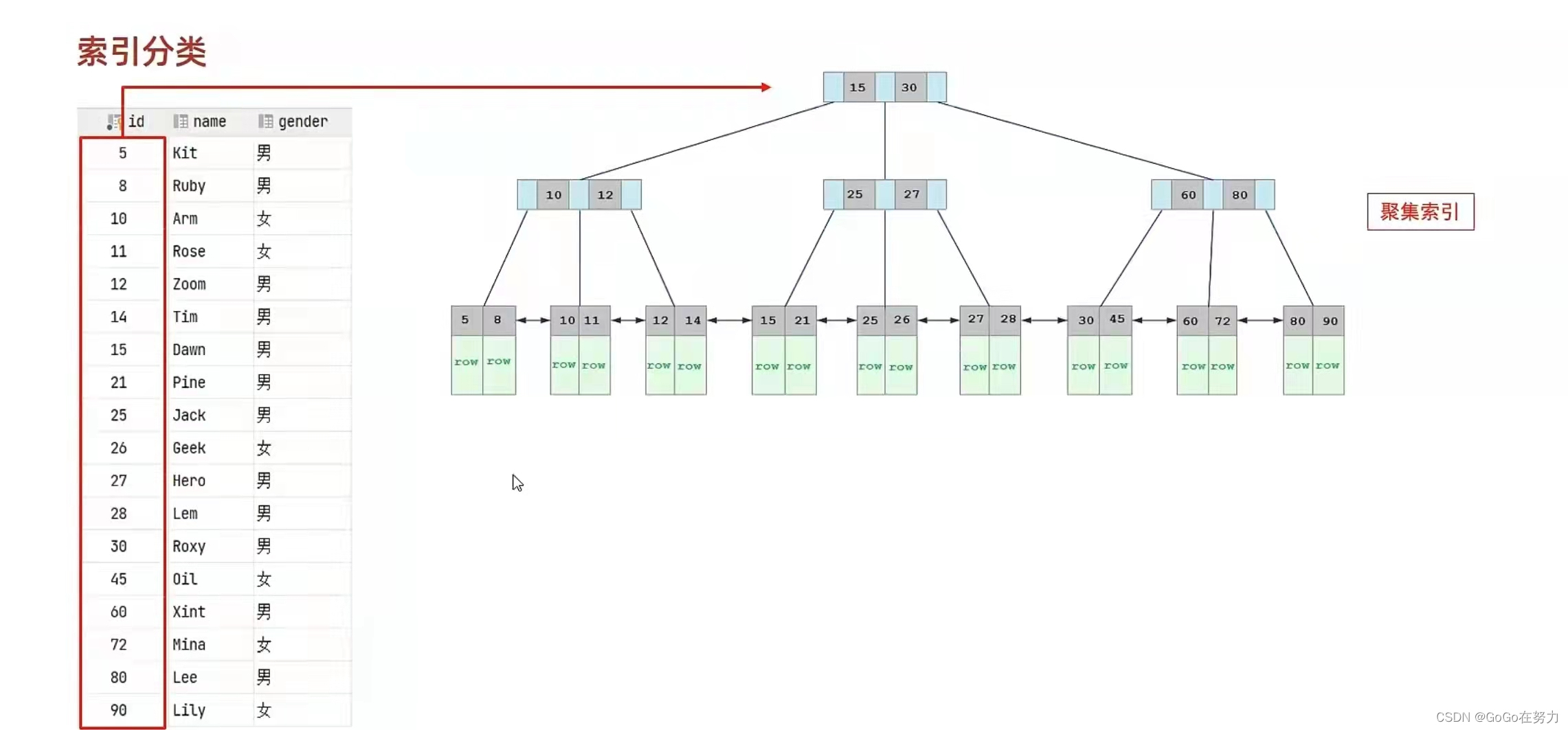
id已经是主键索引了,主键索引就是聚集索引,而且假如现在又让name字段成为索引,那么name索引不是聚集索引,原因是聚集索引只可以有一个;
name索引及其他索引称为二级索引;
如果二级索引它的叶子节点页存储的是是这一行的数据则会数据冗余,所以二级索引下面挂的是Arm、Dawn这个name值对应的是所在行的id值
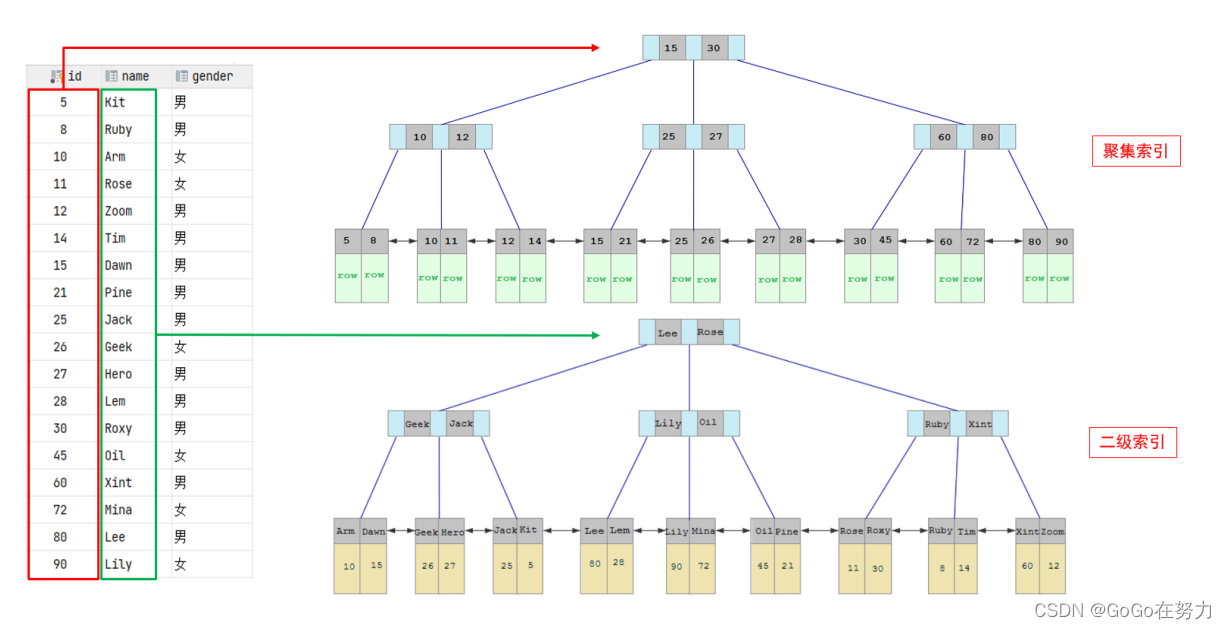
回表查询: 这种先到二级索引中查找数据,找到主键值,然后再到聚集索引中根据主键值,获取数据的方式,就称之为回表查询。
紧接着以上,id已经是主键索引了,主键索引就是聚集索引;name字段也是索引
select * from user where name = ‘Arm’;
具体过程如下:
①由于是根据name字段进行查询,所以先根据name='Arm’到name字段的二级索引中进行匹配查找。但是在二级索引中只能查找到 Arm 对应的主键值 10(先定位到lee,经过lee与arm对比,arm在lee之前,所以会走lee左侧的指针,定位到geek;经过lee与geek对比,arm在geek之前,所以会走lee左侧的指针,定位到arm,发现一样,拿到了id值;)
②由于查询返回的数据是*,所以此时,还需要根据主键值10,到聚集索引中查找10对应的记录,最终找到10对应的行row。(到聚集索引中再找,10<15,走15左边的指针;10>=10,走10与12之间的指针,再往下去,最终定位到10)
③最终拿到这一行的数据,直接返回即可。
6.演示(聚集索引、二级单列普通索引、等值查询、回表查询)
这里以user_innodb为例,user_innodb的id列为主键,age列为普通索引。
InnoDB的数据和索引存储在一个文件t_user_innodb.ibd中。InnoDB的数据组织方式,是聚簇索引。
主键索引的叶子节点会存储数据行,辅助索引只会存储主键值。
CREATE TABLE `user_innodb`
(
`id` int(11) NOT NULL AUTO_INCREMENT,
`username` varchar(20) DEFAULT NULL,
`age` int(11) DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE,
KEY `idx_age` (`age`) USING BTREE
) ENGINE = InnoDB;
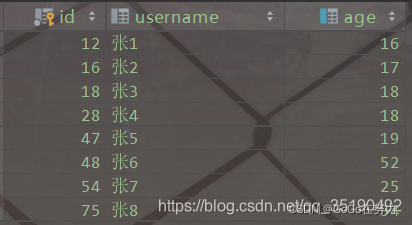
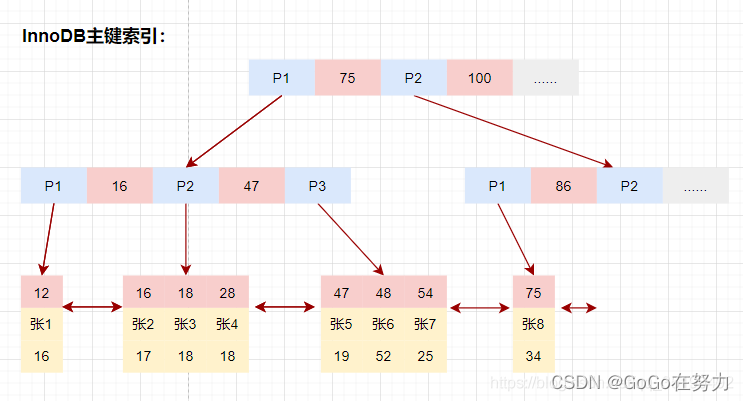
等值查询数据:
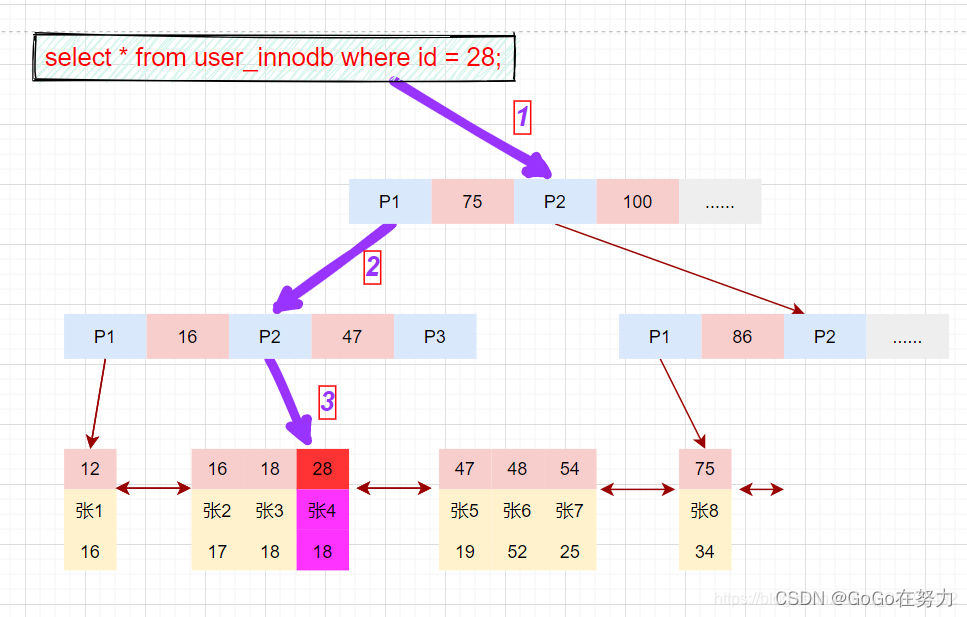
先在主键树中从根节点开始检索,将根节点加载到内存,比较28<75,走左路。(1次磁盘IO)
将左子树节点加载到内存中,比较16<28<47,向下检索。(1次磁盘IO)
检索到叶节点,将节点加载到内存中遍历,比较16<28,18<28,28=28。查找到值等于28的索引项,直接可以获取整行数据。将改记录返回给客户端。(1次磁盘IO)
磁盘IO数量:3次。
select * from user_innodb where id = 28;
除聚簇索引之外的所有索引都称为辅助索引,InnoDB的辅助索引只会存储主键值而非磁盘地址。
以表user_innodb的age列为例,age索引的索引结果如下图:
底层叶子节点的按照(age,id)的顺序排序,先按照age列从小到大排序,age列相同时按照id列从小到大排序。
使用辅助索引需要检索两遍索引:首先检索辅助索引获得主键,然后使用主键到主索引中检索获得记录。
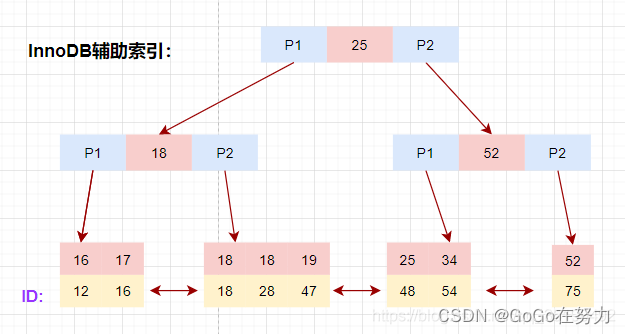
底层叶子节点的按照(age,id)的顺序排序,先按照age列从小到大排序,age列相同时按照id列从小到大排序。
使用辅助索引需要检索两遍索引:首先检索辅助索引获得主键,然后使用主键到主索引中检索获得记录。
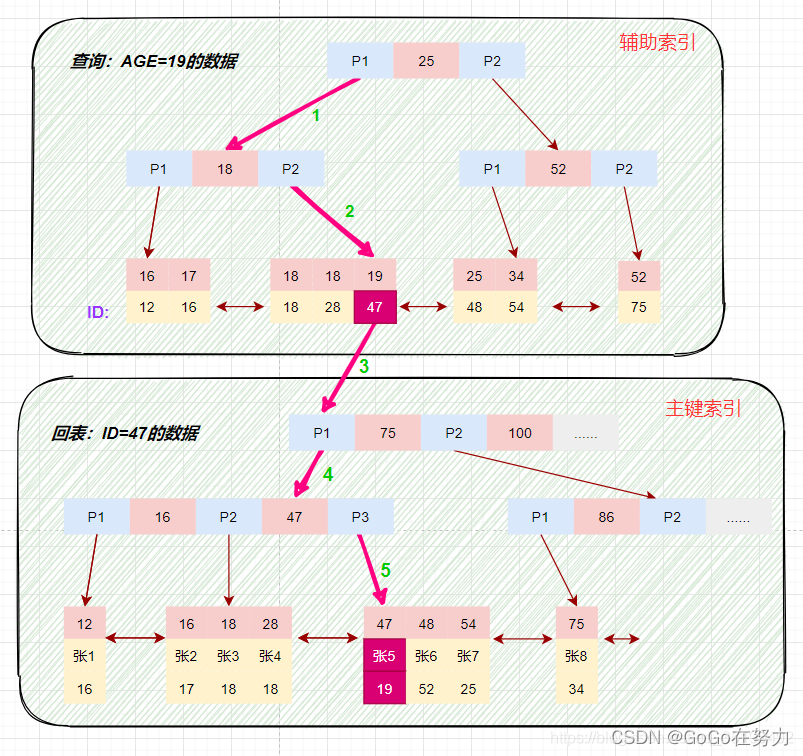
画图分析等值查询的情况:
根据在辅助索引树中获取的主键id,到主键索引树检索数据的过程称为回表查询。
磁盘IO数:辅助索引3次+获取记录回表3次
select * from t_user_innodb where age=19;
7.演示(聚集索引、二级组合普通索引、等值查询、回表查询、最左匹配原则、覆盖索引)
以自己创建的一个表为例:表 abc_innodb,id为主键索引,创建了一个联合索引idx_abc(a,b,c)。
CREATE TABLE `abc_innodb`
(
`id` int(11) NOT NULL AUTO_INCREMENT,
`a` int(11) DEFAULT NULL,
`b` int(11) DEFAULT NULL,
`c` varchar(10) DEFAULT NULL,
`d` varchar(10) DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE,
KEY `idx_abc` (`a`, `b`, `c`)
) ENGINE = InnoDB;
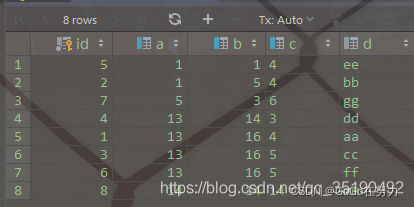
select * from abc_innodb order by a, b, c, id;
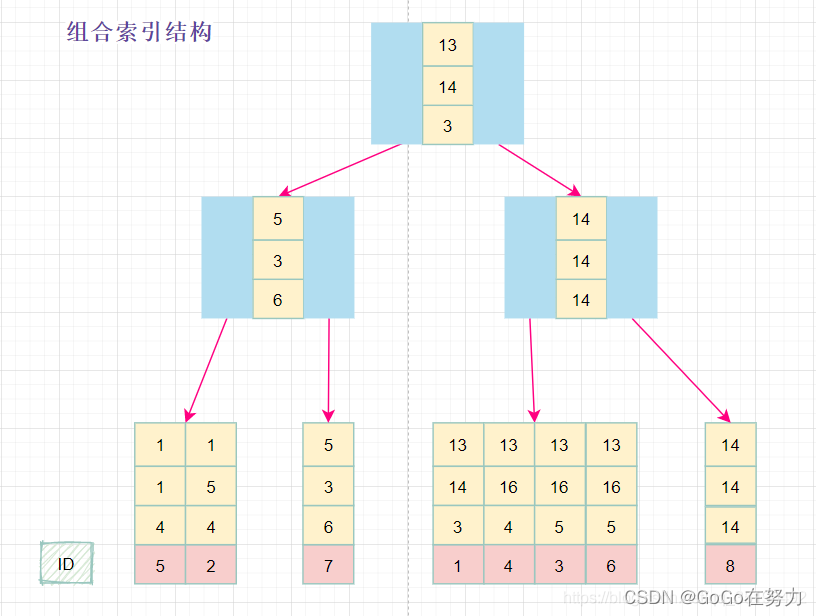
组合索引的数据结构:
组合索引的查询过程:
select * from abc_innodb where a = 13 and b = 16 and c = 4;
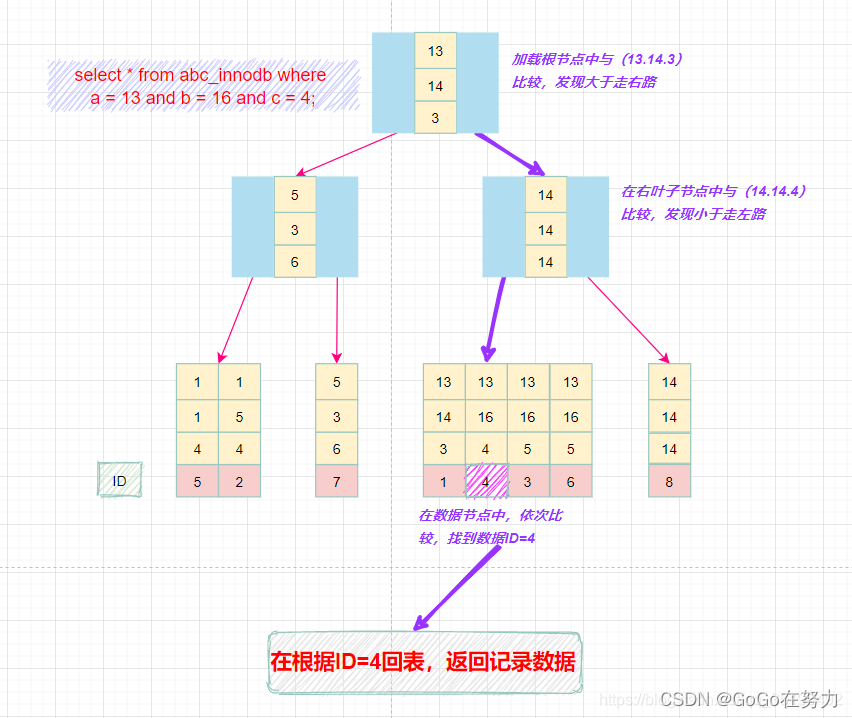
最左匹配原则:
最左前缀匹配原则和联合索引的索引存储结构和检索方式是有关系的。
在组合索引树中,最底层的叶子节点按照第一列a列从左到右递增排列,但是b列和c列是无序的,b列只有在a列值相等的情况下小范围内递增有序,而c列只能在a,b两列相等的情况下小范围内递增有序。
就像上面的查询,B+树会先比较a列来确定下一步应该搜索的方向,往左还是往右。如果a列相同再比较b列。但是如果查询条件没有a列,B+树就不知道第一步应该从哪个节点查起。
可以说创建的idx_abc(a,b,c)索引,相当于创建了(a)、(a,b)(a,b,c)三个索引。、
组合索引的最左前缀匹配原则:使用组合索引查询时,mysql会一直向右匹配直至遇到范围查询(>、<、between、like)就停止匹配。
覆盖索引
覆盖索引并不是说是索引结构,覆盖索引是一种很常用的优化手段。因为在使用辅助索引的时候,我们只可以拿到主键值,相当于获取数据还需要再根据主键查询主键索引再获取到数据。但是试想下这么一种情况,在上面abc_innodb表中的组合索引查询时,如果我只需要abc字段的,那是不是意味着我们查询到组合索引的叶子节点就可以直接返回了,而不需要回表。这种情况就是覆盖索引。
可以看一下执行计划:
覆盖索引的情况:

未使用到覆盖索引:




















 1206
1206

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











