




一、研究背景与问题动机
近年来,视觉理解(如视觉问答)与视觉生成(如文本到图像)通常被拆分为两条独立的研究路线,各自采用不同的模型架构、损失函数与训练范式。这种割裂带来了三大痛点:
-
参数冗余:两套模型各自维护大量权重,难以共享知识。
-
接口复杂:跨模态任务需额外桥接模块(如视觉投影层),增加系统复杂度。
-
训练低效:不同目标函数导致梯度冲突,收敛慢。
本文提出“视觉即方言”的观点,认为视觉信号可以像一门新语言那样,直接融入大语言模型的统一离散空间,从而把理解与生成整合到单一的自回归框架内。
二、总体框架:Tar 统一多模态大模型
Tar 由以下三个核心组件构成:
-
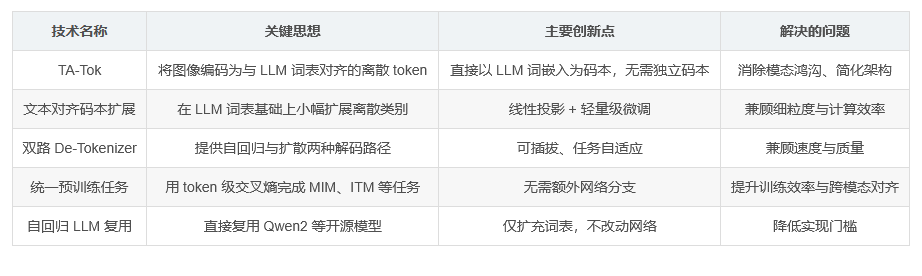
TA-Tok(Text-Aligned Tokenizer):将图像编码为与 LLM 词表对齐的离散 token。
-
自回归 LLM:沿用现有大语言模型(如 Qwen2),仅通过扩充词表即可同时处理文本 token 与视觉 token。
-
视觉 De-Tokenizer:把离散视觉 token 还原为高保真图像,提供两种可选实现——自回归模型与扩散模型。
三、TA-Tok:文本对齐的视觉分词器
3.1 设计思想
传统 VQVAE 等离散 tokenizer 使用独立学习到的码本,导致视觉 token 与文本 token 语义空间不一致。TA-Tok 直接把预训练 LLM 的词嵌入矩阵当作码本,使得视觉 token 天然携带文本语义。
3.2 结构细节
-
以 SigLIP2 为视觉编码器,提取连续特征 z。
-
在 SigLIP2 顶部附加矢量量化(VQ)层,将 z 映射到最近的 LLM token 嵌入 e_k。
-
由于 LLM 词表有限,采用“投影-扩展”策略:先用线性投影将高维视觉特征压缩到词嵌入维度,再允许码本在训练中轻微扩展,兼顾粒度与计算开销。
四、可扩展的视觉解码器(De-Tokenizer)
TA-Tok 本身不能直接从 token 还原像素图像,因此 Tar 引入两种互补的 de-tokenizer:
| 类型 | 技术路线 | 优点 | 适用场景 |
|---|---|---|---|
| 自回归解码器 | 基于离散 token 的自回归 Transformer | 与 LLM 训练目标一致、推理延迟低 | 快速草稿或低分辨率输出 |
| 扩散解码器 | 在潜空间内执行扩散过程 | 高保真、细节丰富 | 最终高分辨率输出 |
五、训练策略:统一预训练任务
为增强视觉-文本融合,Tar 在标准下一个 token 预测之外引入三项辅助任务:
-
掩码图像建模(MIM):随机遮盖部分视觉 token,让模型自回归恢复。
-
文本-图像匹配(ITM):判断给定文本是否与图像 token 描述一致。
-
图像-文本重排:给定打乱顺序的图像 token,要求恢复正确空间布局。
这些任务均以 token 级交叉熵损失实现,无需额外网络分支。
六、实验结果
6.1 视觉理解
在 POPE、MME-P、MME-C 等基准上,Tar-1.5B 与 Tar-7B 均优于同量级模型,且仅用 1.5B 参数就逼近 7B 模型的精度。
6.2 视觉生成
GenEval 整体得分:
-
Tar-1.5B 达到 0.78
-
Tar-7B 达到 0.85
-
加入 Self-Reflection 机制后进一步提升至 0.84/0.87。
6.3 训练效率
由于视觉 token 与文本 token 共享嵌入空间,模型收敛步数减少约 30%,显存占用降低 20%。
七、结论
Tar 通过文本对齐的离散视觉表示,首次在 1.5B~7B 参数量级上实现视觉理解与生成统一建模。其模块化设计(TA-Tok + 双路 De-Tokenizer)为未来多模态 LLM 提供了可插拔、易扩展的新范式。
八、核心技术汇总表


















 167
167

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











