






1. MapReduce是什么?
MapReduce是一种编程模型,是面向大数据并行处理的计算模型、框架和平台。
2. 基本特点
分布可靠,对数据集的操作分发给集群中的多个节点实现可靠性,每个节点周期性返回它完成的任务和最新状态。
封装了实现细节,基于框架API编程,面向业务展开分布式编码。
提供跨语言编程的能力
3.MapReduce运行流程
3.1 MapReduce的主要功能
1. 数据划分和计算任务调度
2.数据代码相互定位
3.系统优化
4.出错检测和恢复
4.MapReduce的运行流程
4.1运行流程
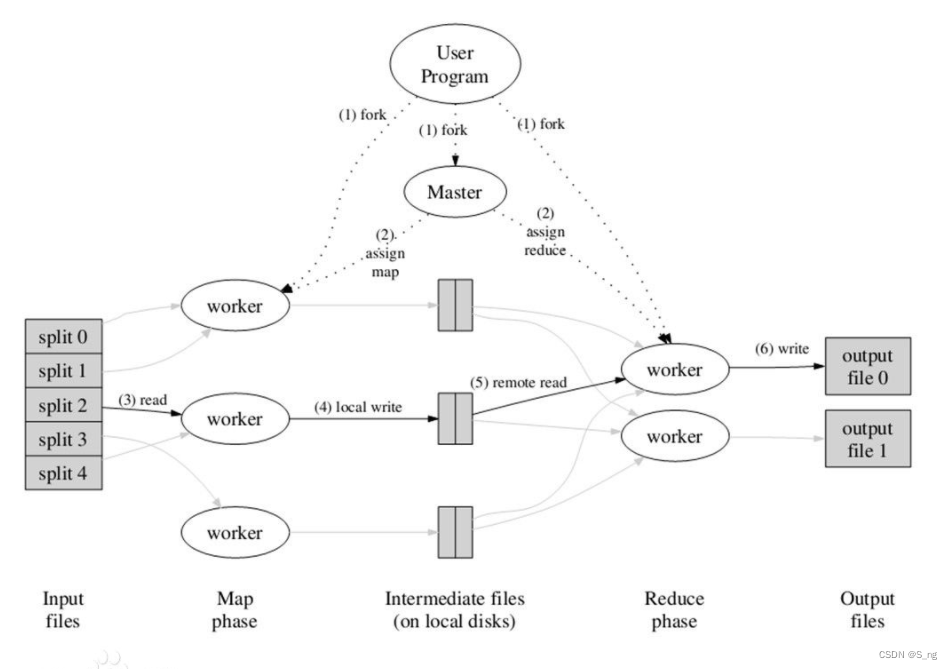
由上图可以看到MapReduce执行下来主要包含这样几个步骤:
1) 首先正式提交作业代码,并对输入数据源进行切片
2) master调度worker执行map任务
3) worker当中的map任务读取输入源切片
4) worker执行map任务,将任务输出保存在本地
5) master调度worker执行reduce任务,reduce worker读取map任务的输出文件
6) 执行reduce任务,将任务输出保存到HDFS
4.2 运行流程详解
- 以WordCount为例
给定任意的HDFS的输入目录,其内部数据为“f a c d e……”等用空格字符分隔的字符串,通过使用MapReduce计算框架来统计以空格分隔的每个单词出现的频率,输出结果如<a,10>,<b,20>,<c,2>形式的结果到HDFS目录中。
- WordCount运行图解
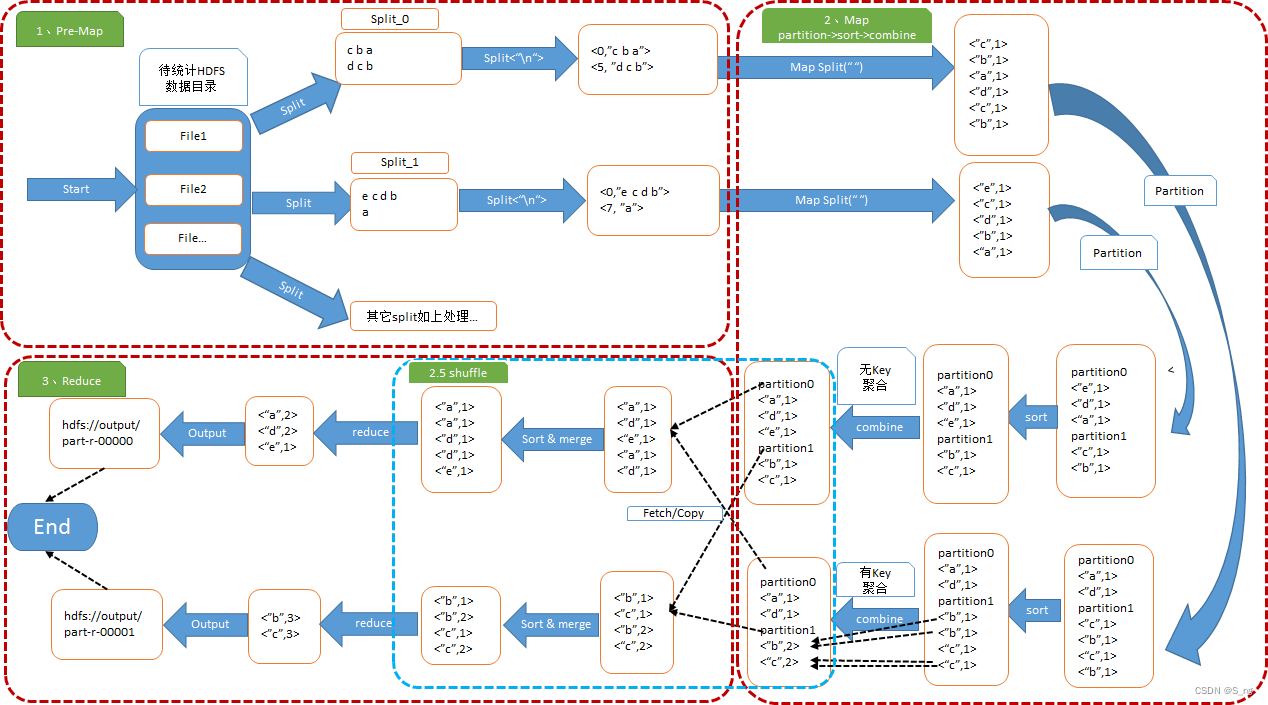
MapReduce将作业的整个运行过程分为两个阶段:Map阶段Reduce阶段。
Map阶段由一定数量的Map Task组成,流程如下:
- 输入数据格式解析:InputFormat
- 输入数据处理:Mapper
- 数据分区:Partitioner
- 数据按照key排序
- 本地规约
- 数据按照key排序和文件合并merge
- 数据处理:Reducer
- 数据输出格式:OutputFormat
通常我们把从Mapper阶段输出数据到Reduce阶段的reduce计算之间的过程称之为shuffle。

















 1082
1082

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









