






前言
随着人工智能领域计算机视觉的发展,相对于CNN或许transformer是更好的选择。但CNN中很多思想仍值得学习,其中可以说是最典型的网络就是Resnet了。看了很多人对它的理解,包括沐神,都有我认为不合理的地方或无法理解的地方(可能本人太菜,无法领悟大神的思想)。以下是我对于Resnet的一些拙见,如有不对,欢迎批评指正。
一、Resnet是什么?
如果你看过Resnet的论文或一些对于它的讲解,可以跳过本部分。
以下简述Resnet。
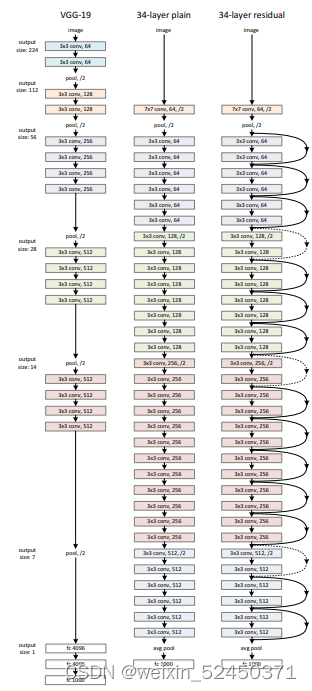
上图中,左侧为VGG网络,中间为直接摞了34层卷积的网络,左右侧则是在34层卷积网络中加入了残差结构。说白了就是当前层的输出在传入下一层的同时,再另辟一条道路,将这当前层的输出直接加到下一层的输出。如下图所示。
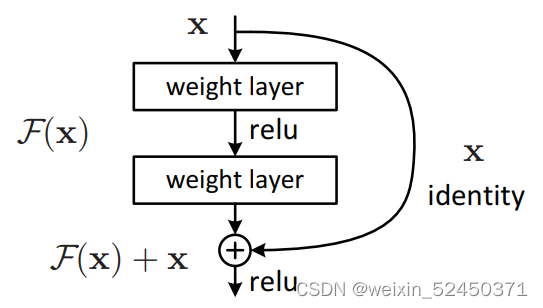
其中,x为当前层的输出(图上只有下一层,没有显示当前层,请在本结构上侧脑补一个当前层),F(x)为当前层,而当前层的输出不只是单纯的F(x),而是F(x)+x。接下来会将为什么要这样做。
二、Resnet原理
如果你有一些CNN的基础,那么你一定知道,随着卷积层数量的增加,网络的感受野会变大(一直做1*1卷积除外),也就是说每个通道的每个像素点包含的信息越来越多。这是一件好事。但随之而来的,是模型复杂度的上升。尽管可以通过数据预处理、Batch Normalization、模型权重初始化等操作来尽可能避免梯度爆炸或梯度消失,我们仍然很难通过随机梯度下降找到最优解。它十分容易陷入局部最优。
那么,如何改善这个问题呢?加残差!
在加深网络的同时,我们的目的是使这个网络变得更好、精度更高。但是一味的加深网络一定会带来性能的提升吗?很多的实验表明,并非如此。所以说,我们在加深网络时,最该考虑的是此操作不应使网络变差!
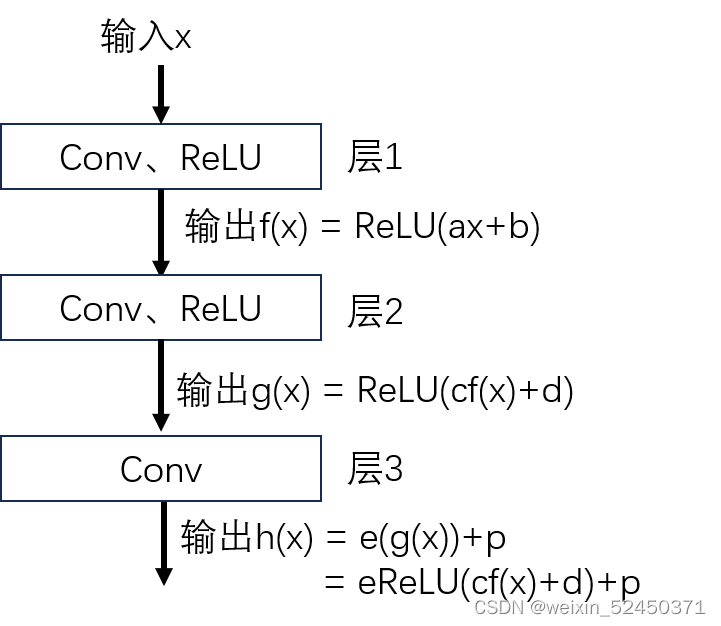
在没有残差的概念时,我们想在层1的基础上再加一些(大于1)层,即层2和层3,此时这个网络输出可以看作eReLU(cf(x)+d)+p。
加了两层以后,理论上我们的模型效果会变得更好(这里指在数据集上)。但是,随着层数的累计增加了复杂度,计算机难以找到最优解,模型在数据集上都难以收敛,更不要说验证集上的泛化能力了。我们想,就算增加的层不能优化模型,你别让模型能力下降总行了吧!我就当做没加你这个层,我让最后一层的输出直接变成第一层的输出f(x)。但是对于我们的网络来说,这可行吗?
这就等于令最后一层的输出eReLU(cf(x)+d)+p=f(x),模型很难随着梯度下降达到这样,这个ReLU太恶心了!既然你模型达不到,那么我手动加一个得了。
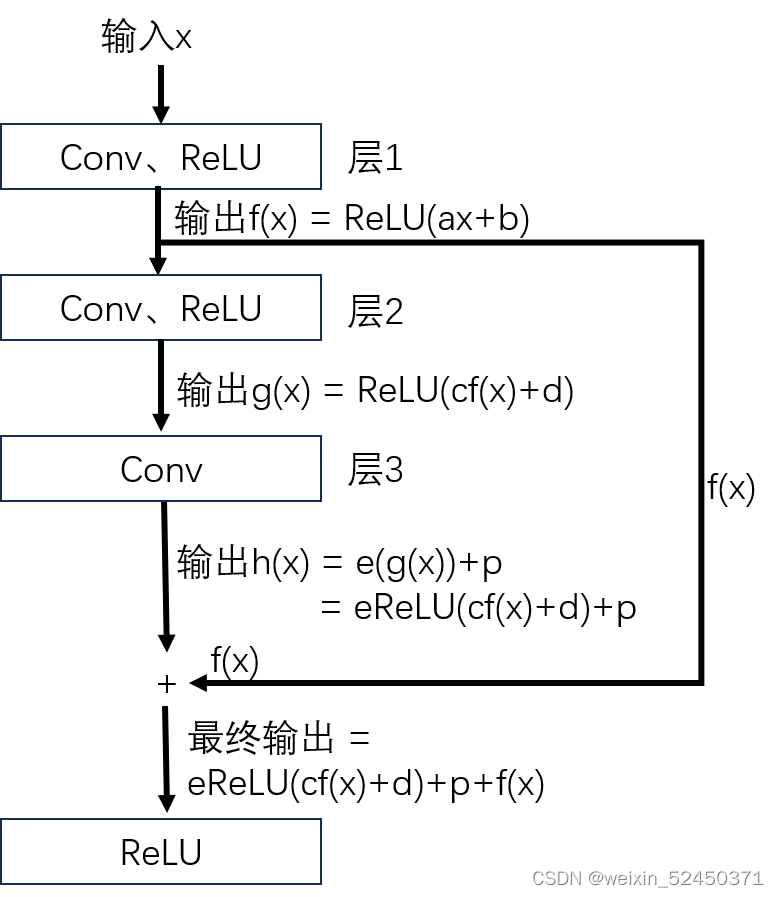
这回让eReLU(cf(x)+d)+p+f(x) = f(x) 简单多了吧!大不了我直接令层3的系数全为零(e和p都为0)即层2层3作用消失不就得了!
这下,无论我再多增加多少层,随着网络训练不断迭代,都不会使我的精度降低,最差也就是与我原网络的精度一样!
总结
应该是这样理解吧,如有不对,欢迎批评指正!!

















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









