






一,Load命令加载数据(官方推荐)
前面使用过HDFS直接web页面将文件上传的方法,官方推荐使用load命令进行上传
Load语法功能
所谓加载是指:将数据文件移动到与Hive表对应的位置,移动时是纯复制(本地加载是复制)、移动(hdfs加载是移动)操作。
纯复制、移动指在数据1oad加载到表中时,Hive不会对表中的数据内容进行任何转换,任何操作。
LOAD DATA [LOCAL] INPATH “filepath’ [OVERWRITE] INTO TABLE tablename;
案例一:load本地加载的案例
注意,load的本地指的是metastore和hiveserve2运行机器所在的客户端
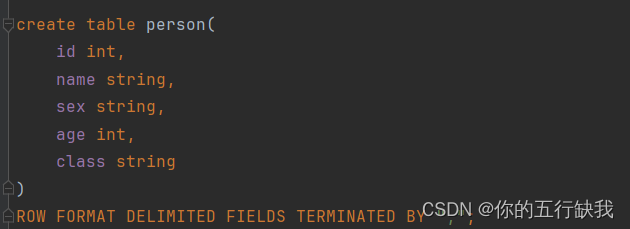
<1>创建表,使用分隔符”,"
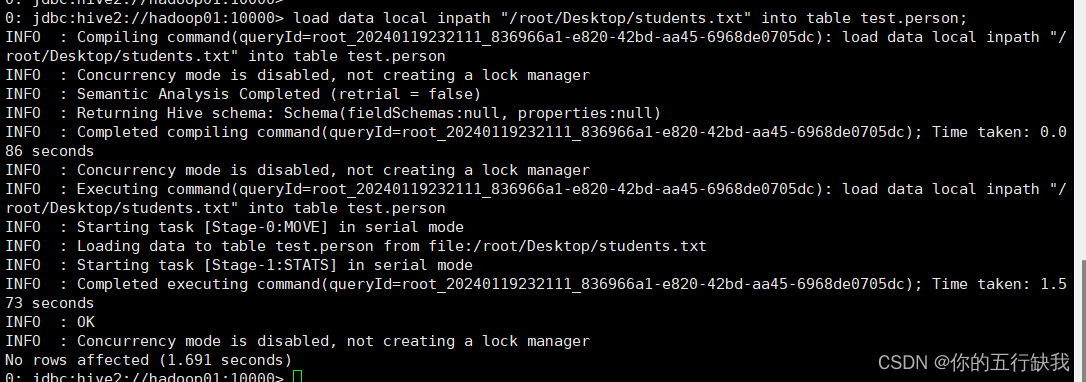
<2>使用load命令将文件加载到hdfs中(文件在运行hive的机器上面,文件路径也在其中)
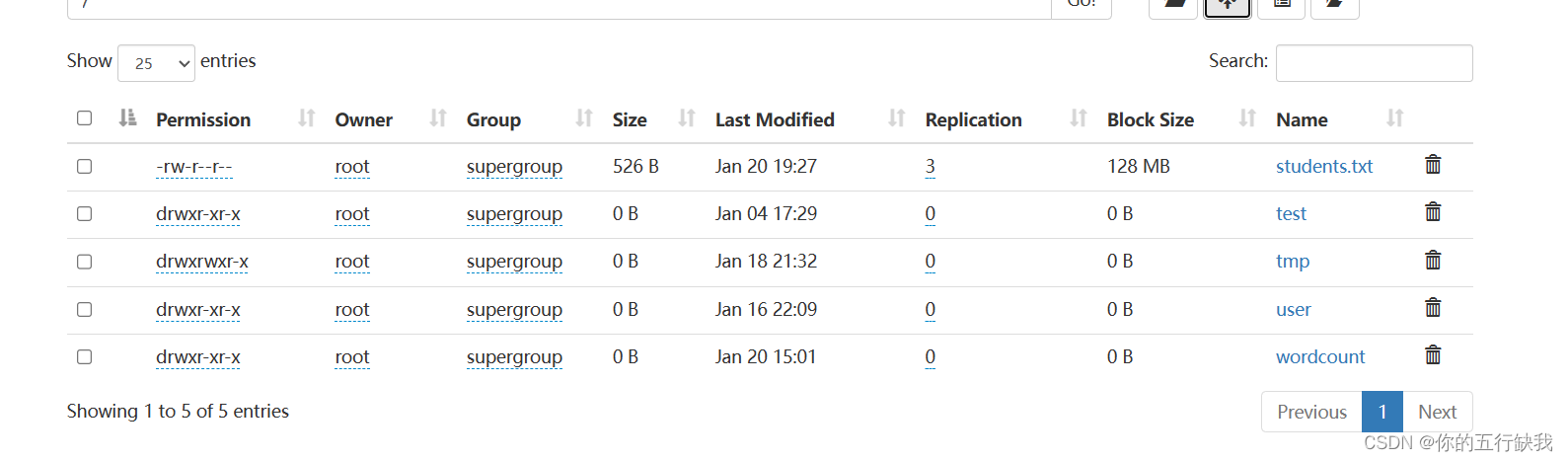
之后可以查询到表的数据。
案例二:load加载hdfs的文件的案例
我们将文件上传到hdfs的根目录下
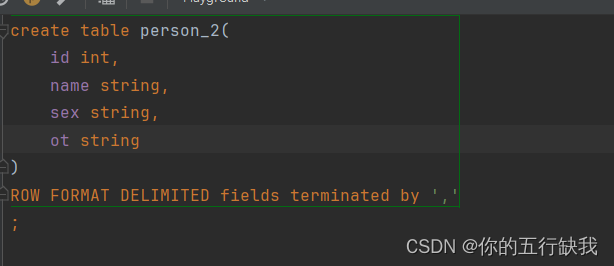
创建一张表
使用load加载数据到person_2中
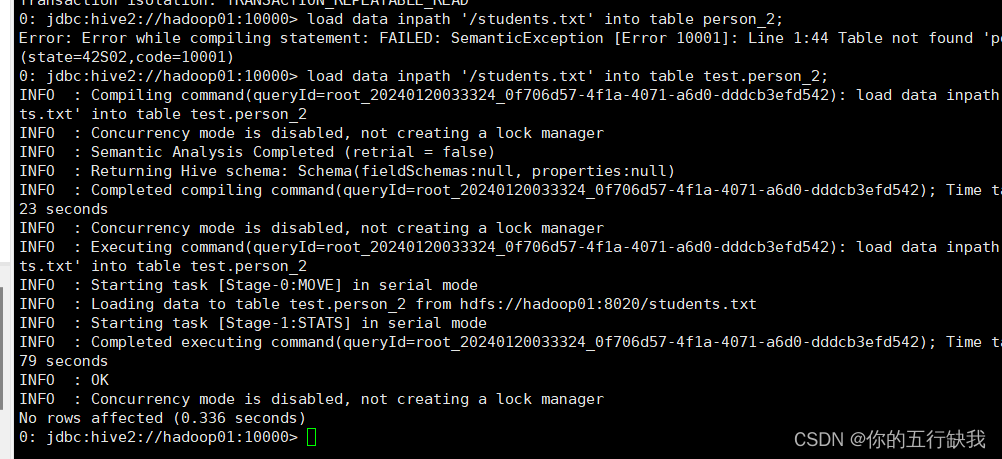
查看数据是否加载(成功)
二,INSERT语句的使用
Hive官方推荐加载数据的方式:
清洗数据成为结构化文件,再使用Load语法加载数据到表中。这样的效率更高。
也可以使用insert语法把数据插入到指定的表中,最常用的配合是把查询返回的结果插入到另一张表中。(除非是批量插入,否则插入一条数据也要mapreduce,执行速度缓慢)
下面这个,仅仅这一句,插入就花费了40秒,速度堪忧。

insert+select的使用(比较常用)
insert+select表示:将后面查询返回的结果作为内容插入到指定表中。
需要保证查询结果列的数目和需要插入数据表格的列数目一致。
如果查询出来的数据类型和插入表格对应的列数据类型不一致,将会进行转换,但是不能保证转换一定成功,转换失败的数据将会为NULL。
三,select查询操作
<1>select的语法树
从哪里查询取决于FROM关键字后面的table_reference,这是我们写查询SQL的首先要确定的事即你查询谁
表名和列名不区分大小写。
SELECT [ALL | DISTINCT] select_expr, select_expr, …FROM table_reference
[WHERE where_condition]//过滤(在这些关键字中,执行顺序为一条一条向下执行)
[GROUP BY col_list]//分组
[ORDER BY col_list]//排序
[LIMIT [offset,] rows];//排序
SQL的执行顺序
FROM 子句组装来自不同数据源的数据;
WHERE 子句基于指定的条件对记录行进行筛选;
GROUP BY 子句将数据划分为多个分组;
使用聚集函数进行计算;
使用 HAVING 子句筛选分组;
计算所有的表达式;
SELECT 的字段;
使用 ORDER BY 对结果集进行排序。
<2>select_expr:为待查询的字段
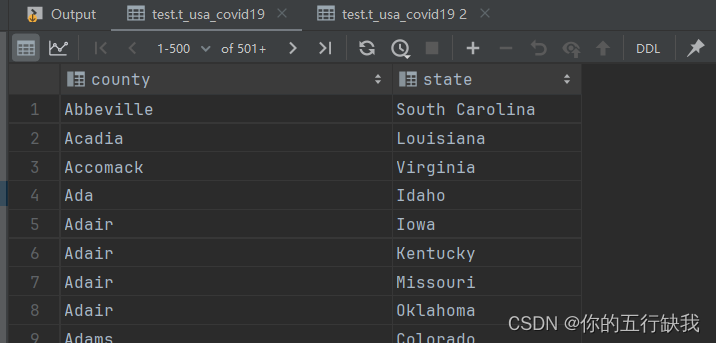
查询表中的所有数据
select * from t_usa_covid19;
查询指定的字段名
select county,cases,deaths from t_usa_covid19;
查询的与表的字段,全部为1
select 1 from t_usa_covid19;
查询当前使用的数据库
select current_database();
1.select t_usa_covid19.state from t_usa_covid19等价与select all t_usa_covid19.state from t_usa_covid19;会返回重复数据
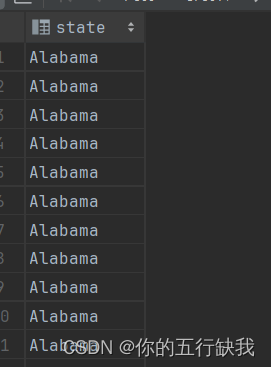
2.select DISTINCT t_usa_covid19.state from t_usa_covid19;会去除重复的数据。
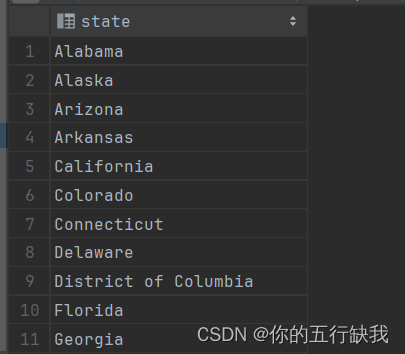
3.select DISTINCT county,state from t_usa_covid19;会对两个字段整体去重
<3>where使用(进行过滤一定的规矩)
select * from t_usa_covid19 where 1>2;
1>2,返回的值始终为false,因此不会返回任何数据。
select * from t_usa_covid19 where 1=1;
1=1,返回值始终为true,因此会返回数据库所有的内容。
1.通过匹配字段的内容进行筛选
select * from t_usa_covid19 where state=‘Colorado’;
会将state为Colorado的行返回。
2.可以使用一些简单的函数
select * from t_usa_covid19 where length(state)>=10;
会将state成都大于等于10的行返回
3.where中不能使用聚合函数
–注意:where条件中不能使用聚合函数
–报错 SemanticException:Not yet supported place for UDAF ‘count’–聚合函数要使用它的前提是结果集已经确定。
-而where子句还处于"确定"结果集的过程中,因而不能使用聚合函数。
4.聚合操作
select count(county) as county_cnts from t_usa_covid19;
统计有多少行county
select count(distinct county) as county_cnts from t_usa_covid19;
加上distinct字段,可以去除重复从而统计出多少个county
select count(county) from t_usa_covid19 where state = “California”;
where过滤得到的数据,可以被聚合函数所统计
5.where中可以使用的字段
比较运算、逻辑运算
比较运算符包涵 :=><>= ,<=,!=,<>表示(不等于)
Select *from emp where ename=‘SMITH’;
逻辑运算
And:与 同时满足两个条件的值,
Select *from emp where sal>2000 and sal< 3000:
Or:或 满足其中一个条件的值
Select from emp where sal>2000 orcomm >500;
空值判断 :is null
Selectfrom emp where comm is null;
between and(在 之间的值)
Select from emp where sal between 1500 and 3000;
In
Selectfrom emp where sal in(5000,3000,1590);
<4>聚合操作
SQL中拥有很多可用于计数和计算的内建函数,其使用的语法是:SELECT function(列)FROM 表Avg等函数。
这里我们要介绍的叫做聚合(Aggregate)操作函数,如:Count、Sum、Max,Min。
聚合函数的最大特点是不管原始数据有多少行记录,经过聚合操作只返回一条数据,这一条数据就是聚合的结果
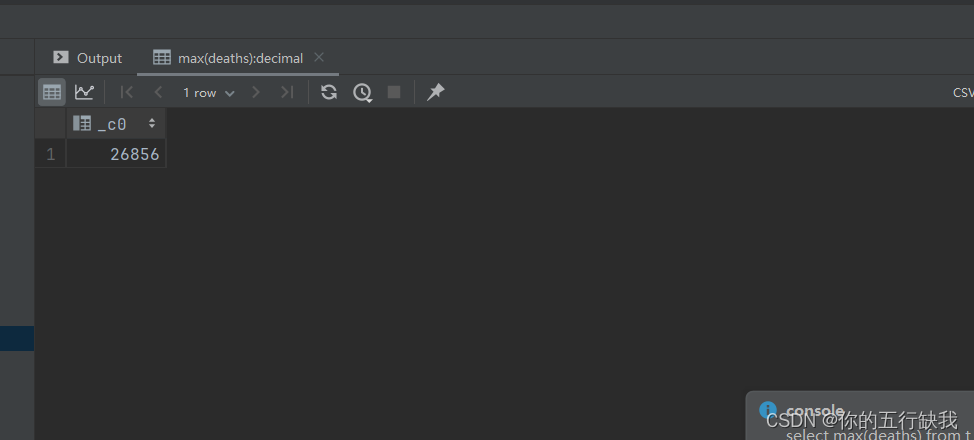
select max(deaths) from t_usa_covid19;
查询deaths中最大的数据
<5>group by分组操作
GROUP BY语法限制
出现在GROUP BY中select_expr的字段:要么是GROUP BY分组的字段;要么是被聚合函数应用的字段。
原因:避免出现一个字段多个值的歧义。
1.分组字段出现select_expr中,一定没有歧义,因为就是基于该字段分组的,同一组中必相同;
2.被聚合函数应用的字段,也没歧义,因为聚合函数的本质就是多进一出,最终返回一个结里。
select state,sum(deaths) from t_usa_covid19 group by state;
按照州分组,并且将每个组的死亡人数相加
<6>having过滤
查询2021年1月28号死亡人数大于30000的州
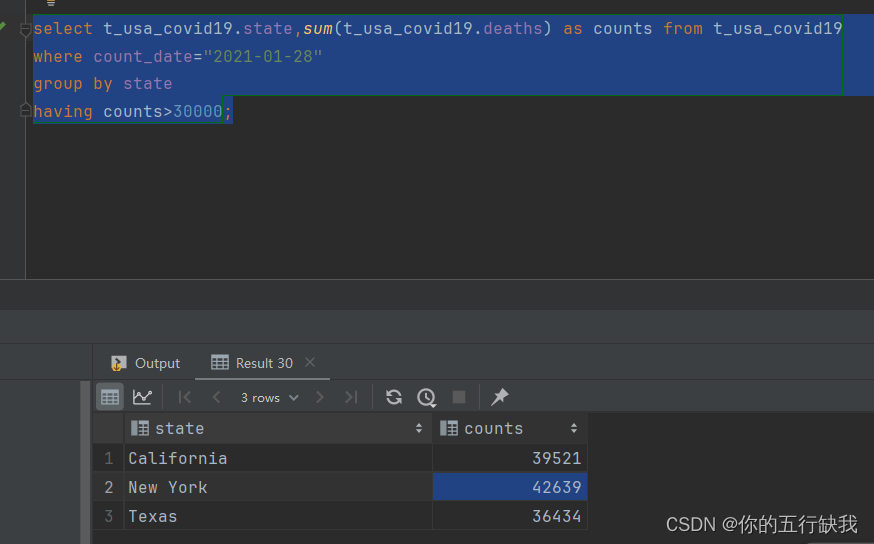
对该语句执行过程的分析:首先,from先整合来自不同数据源的数据,之后where过滤出2021年1月28号的统计数据,之后gruop by对过滤的数据进行分组,之后执行聚合函数,最后再由having过滤出死亡人数大于30000的数据。
<7>order by 进行排序
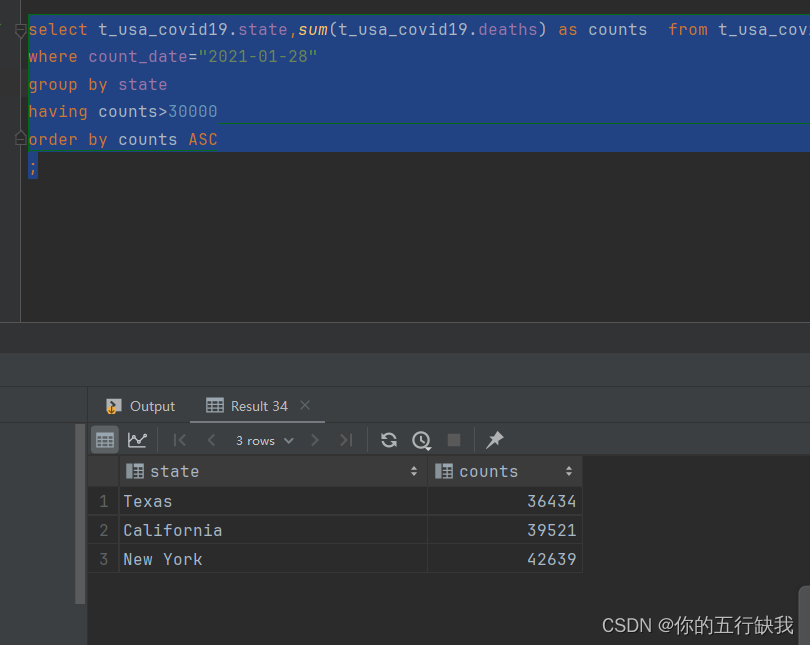
select t_usa_covid19.state,sum(t_usa_covid19.deaths) as counts from t_usa_covid19
where count_date=“2021-01-28”
group by state
having counts>30000
order by counts ASC
;
对6的结果进行升序排序
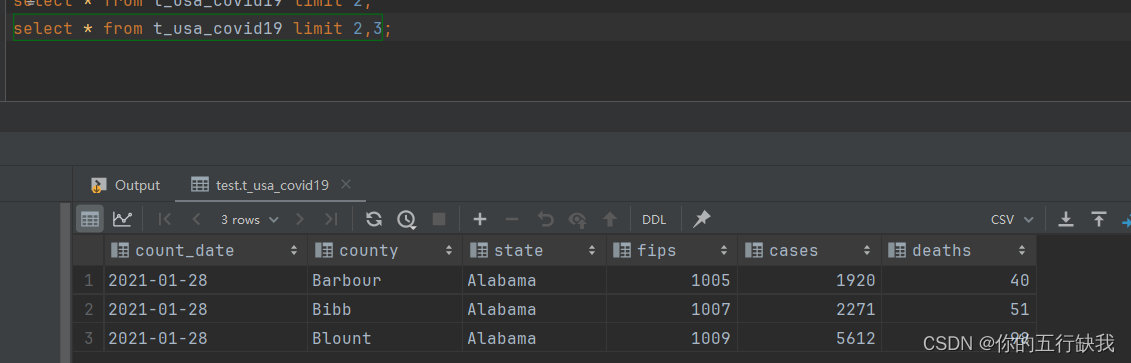
<8>limit限制返回的行数
在工作的过程中,如果表的数量太多,会撑爆内存
返回从偏移量2开始后的3行数据。
<9>join语法的练习
有时需要基于多张表查询才能得到最终完整的结果
join语法的出现是用于根据两个或多个表中的列之间的关系,从这些表中共同组合查询数据。
在Hive中,使用最多,最重要的两种join分别是inner join(内连接)、left join(左连接)
join语法规则
table reference:是join查询中使用的表名,
table_factor:与table_reference相同,是联接查询中使用的表名,
join condition:join查询关联的条件,如果在两个以上的表上需要连接,则使用AND关键字。
join table:
table reference [INNER ]JOlN table factor [join condition]
|table reference {LEFT}[OUTER] JOlN table reference join condition
join condition:
ON expression
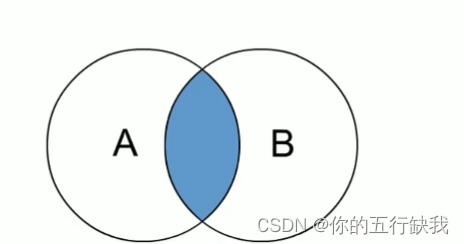
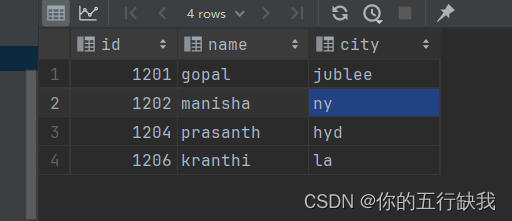
inner join 内连接:
内连接是最常见的一种连接,它也被称为普通连接,其中inner可以省略:inner join ==join;
只有进行连接的两个表中都存在与连接条件相匹配的数据才会被留下来。
(以条件e.id=e_a.id为例,只有e中的id=e_a中的id,满足这样的行才会进行连接)
select employee.id,employee.name,employee_address.city from employee join employee_address on employee.id=employee_address.id;(inner可以省略)
等价于以下写法
select employee.id,employee.name,employee_address.city
from employee,employee_address
where employee.id=employee_address.id;
left join 左连接
left join中文叫做是左外连接(Left 0uter Join)或者左连接,其中outer可以省略,left outer ioin是早期的写法。
left join的核心就在于1eft左。左指的是join关键字左边的表,简称左表。
通俗解释:join时以左表的全部数据为准,右边与之关联;左表数据全部返回,右表关联上的显示返回,关联不上的显示null返回。
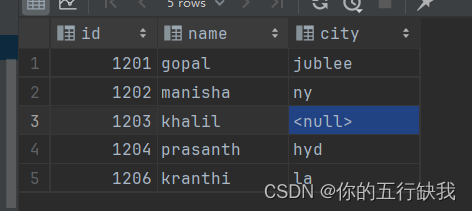
select employee.id,employee.name,employee_address.city
from employee left join employee_address on employee.id=employee_address.id;
返回结果如下(我们发现,employee的行被选取的字段全部被返回,但中另一个表中没有匹配到的行则返回NULL)
四,hive的函数
1.show functions ;查看hive中能够使用的函数
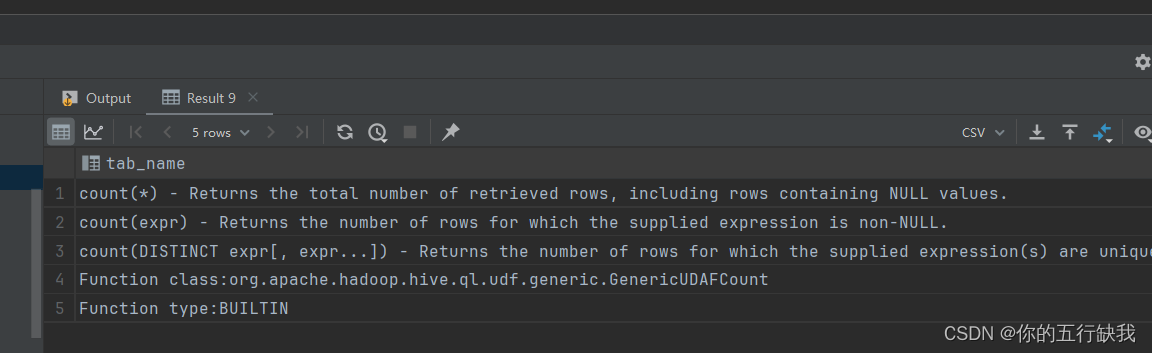
2.describe function extended count;查看某些函数的作用
3.hive函数的分类
根据函数输入输出的行数:
UDF:普通函数,一进一出
UDAF(User-Defined Aggregation Function)聚合函数,多进一出
UDTF(User-Defined Table-Generating Functions)表生成函数,一进多出
4.hive的常用的内置函数
------------String Functions 字符串函数------------
select length(“itcast”);//得到字符串的长度
select reverse(“itcast”);//将字符串反转
select concat(“angela”,“baby”);//将字符串进行拼接
–带分隔符字符串连接函数:concat_ws(separator, [string | array(string)]+)
select concat_ws(‘.’, ‘www’, array(‘itcast’, ‘cn’));//将字符串拼接,并且加上分隔符.
–字符串截取函数:substr(str, pos[, len]) 或者 substring(str, pos[, len])
select substr(“angelababy”,-2); --pos是从1开始的索引,如果为负数则倒着数
select substr(“angelababy”,2,2);
–分割字符串函数: split(str, regex)
–split针对字符串数据进行切割 返回是数组array 可以通过数组的下标取内部的元素 注意下标从0开始的
select split(‘apache hive’, ’ ');
select split(‘apache hive’, ’ ')[0];//得到分割的第一个字符串
select split(‘apache hive’, ’ ')[1];//得到分割的第二个字符串
----------- Date Functions 日期函数 -----------------
–获取当前日期: current_date
select current_date();
–获取当前UNIX时间戳函数: unix_timestamp//时间戳,是一个确定的时间,当前的时间是在时间戳的基础上,再加上累积的数字
select unix_timestamp();
–日期转UNIX时间戳函数: unix_timestamp
select unix_timestamp(“2011-12-07 13:01:03”);
–指定格式日期转UNIX时间戳函数: unix_timestamp
select unix_timestamp(‘20111207 13:01:03’,‘yyyyMMdd HH:mm:ss’);
–UNIX时间戳转日期函数: from_unixtime
select from_unixtime(1618238391);
select from_unixtime(0, ‘yyyy-MM-dd HH:mm:ss’);
–日期比较函数: datediff 日期格式要求’yyyy-MM-dd HH:mm:ss’ or ‘yyyy-MM-dd’
select datediff(‘2012-12-08’,‘2012-05-09’);
–日期增加函数: date_add
select date_add(‘2012-02-28’,10);
–日期减少函数: date_sub
select date_sub(‘2012-01-1’,10);
----Mathematical Functions 数学函数-------------
–取整函数: round 返回double类型的整数值部分 (遵循四舍五入)
select round(3.1415926);
–指定精度取整函数: round(double a, int d) 返回指定精度d的double类型
select round(3.1415926,4);
–取随机数函数: rand 每次执行都不一样 返回一个0到1范围内的随机数
select rand();
–指定种子取随机数函数: rand(int seed) 得到一个稳定的随机数序列
select rand(3);
-----Conditional Functions 条件函数------------------
–使用之前课程创建好的student表数据
select * from student limit 3;
–if条件判断: if(boolean testCondition, T valueTrue, T valueFalseOrNull)
select if(1=2,100,200);
select if(sex =‘男’,‘M’,‘W’) from student limit 3;
–空值转换函数: nvl(T value, T default_value)
select nvl(“allen”,“itcast”);
select nvl(null,“itcast”);
–条件转换函数: CASE a WHEN b THEN c [WHEN d THEN e]* [ELSE f] END
select case 100 when 50 then ‘tom’ when 100 then ‘mary’ else ‘tim’ end;
select case sex when ‘男’ then ‘male’ else ‘female’ end from student limit 3;


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









