






一、简述:
-
HBase原本是由Yahoo公司开发后来贡献给了Apache的一套开源的、基于Hadoop的、分布式的、可扩展的、非关系型数据库
-
如果需要对大量数据进行随机且实时读写,那么可以考虑使用HBase
-
HBase能够管理非常大的表:billions of rows*millions of columnsHBase是仿照Google的Big Table来进行实现的,因此,HBase和BigTable的原理几乎一致,只有实现语言不同。HBase是使用Java语言实现的,BigTable使用的是C语言实现的-HBase最终将数据落地到HDFS上
二、基本概念:
1.RowKey:行键
a. 在HBase中没有主键的概念,取而代之的是行键不同于传统的关系型数据库,在HBase中,定义表的时候不需要指定行而是在添加数据的时候来手动添加行键
2.Column Family:列族/列簇
a.在HBase中,没有表关联的概念,取而代之的是用列族来进行设计
b.在HBase中,一个表中至少要包含1个列族,可以包含多个列族,理论上不限制列族的数量
c.在HBase中强调列族,但是不强调列-在定义表的时候必须定义列族,但是列可以动态增删,一个列族中可以包含8到多个列
d.Hbase能够存储稀疏类型的数据,因此你能够存储结构化数据和半结构化数据
三、常用命令:
命令(例如针对person表)
| 命令 | 描述 |
|---|---|
| processlist | 查看当前HBase在执行的任务 |
| status | 查看HBase的运行状态 |
| version | 查看HBase的版本 |
| who am i | 查看HBase的当前用户 |
| create person,{NAME =>‘basic’},{NAME =>‘info’},{NAME =>‘other’}或者create ‘person’,‘basic’,‘info’,‘other’ | 建立一个person表,包含3个列族:basic,info, other |
| append’person’,‘p1’,‘basic:name’,Bob’ | 在person表中添加一个行键为p1的数据,向basic列族的name列中添加数据 |
| get person’,"p1 | 获取指定行键的数据 |
| get ‘person’,‘p1’,{COLUMN => basic’} 或者get ‘person’,‘p1’, ‘basic’ | 获取指定行键指定列族的数据 |
| get ‘person’,‘p1’, {COLUMN => [‘basic’,‘info’ ]}或者 get ‘person’,‘p1’,‘basic’,‘info’ | 获取指定行键多列族的数据 |
| get ‘person’,‘p1’, {COLUMN => [‘basic’,‘name’ ]}或者 get ‘person’,‘p1’,'basic:name | 获取指定行键指定列的数据 |
| scan 'person | 扫描整表 |
| scan personr,{COLUMNS =>‘basic’} | 获取指定列族的数据 |
四、安装部署
1.准备三台虚拟机(我的分别是ali-kafka-vm1,ali-kafka-vm2,ali-kafka-vm3),确保已搭建zookeeper和hadoop集群环境。可参考我的其他两篇文章:最新版zookeeper集群搭建 ,最新版hadoop集群搭建
2.在vm1根目录下新建目录:
mkdir hbase
3.官网下载最新版安装包到ali-kafka-vm1的hbase目录.官网地址:Apache Download Mirrors
4.解压安装包到该目录:
tar -zxvf hbase-2.6.0-bin.tar.gz
5.解压成功:

6.进入hbase的配置目录
cd hbase-2.6.0/conf
7.编辑hbase-env.sh文件
添加如下配置(编写完后 source hbase-env.sh生效:
export JAVA_HOME=/usr/java/jdk1.8.0-x64
export HBASE_MANAGES_ZK=false #使用我们自己安装的zookeeper
8.编辑hbase-site.xml
<!--开启HBase的分布式-->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.tmp.dir</name>
<value>./tmp</value>
</property>
<!--指定HBase在HDFS上的数据存储目录-->
<property>
<name>hbase.rootdir</name>
<value>hdfs://ali-kafka-vm1:9000/hbase</value>
</property>
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
<!--配置Zookeeper的连接地址-->
<property>
<name>hbase.zookeeper.quorum</name>
<value>ali-kafka-vm1:2181,ali-kafka-vm2:2181,ali-kafka-vm3:2181</value>
</property>
<property>
<name>hbase.wal.provider</name>
<value>filesystem</value>
</property>
9.编辑regionservers文件,添加三台主机名

10.需要将Hadoop的核心配置文件拷贝到当前的HBase的配置目录下
cp /hadoop/hadoop-3.4.0/etc/hadoop/core-site.xml ./

11.将整个hbase目录分发到另外两台服务器:
scp -r /hbase root@ali-kafka-vm2:/hbase
scp -r /hbase root@ali-kafka-vm3:/hbase
12.去另外两台服务器查看是否拷贝成功:

13.配置服务器hbase环境变量(三台服务器都需配置)
vim /etc/profile
配置内容:
export HBASE_HOME=/hbase/hbase-2.6.0
export PATH=$PATH:$HBASE HOME/bin
14.source使其生效后在vm1服务器启动hbase(在此之前保证已启动zookeeper和hadoop):
start-hbase.sh
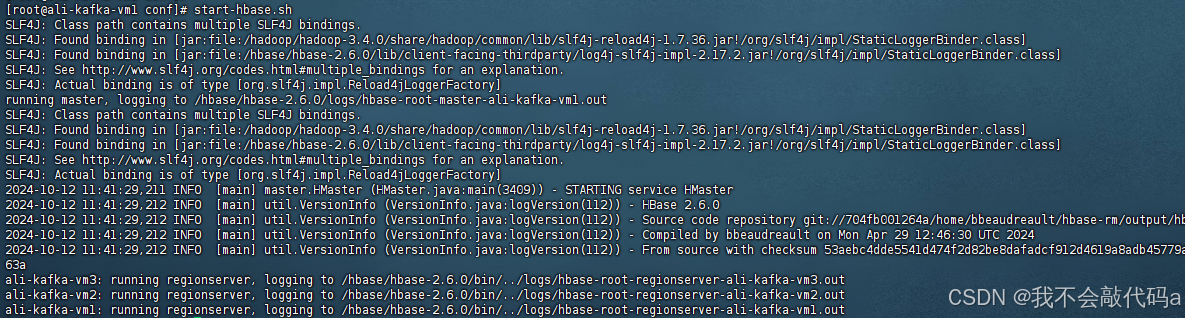
主节点jps查看:
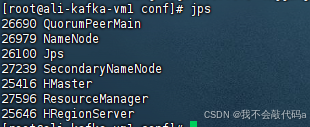
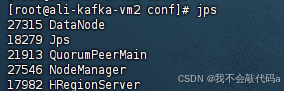
从节点jps查看:
至此,分布式hbase搭建成功!!觉得有用的小伙伴点个免费的赞赞吧,谢谢!!



















 1160
1160

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











