







Abstract
问题:作者发现生成的人脸视频在风格潜在向量的时间变化上存在时间特异性,这种问题来源于生成过程试图在保持视频时间一致性(即视频看起来流畅)的同时,还需要适应不同帧中面部表情或几何变化的要求。
解决办法:
在分析风格潜在变量(style latent vectors)和风格潜在变量在时间变化上的异常行为(不同于真实视频的行为,abnormal behavior in temporal changes)的基础上,提出了一种新的检测方法:
1.利用通过对比学习训练的StyleGRU module来表示style latent vectors的动态属性,提取它们的时间变化特征
2.引入了一个style attention module,将 StyleGRU 生成的时间动态特征 与 基于内容的特征(content-based features) 融合,实现对视觉和时间伪造伪迹的联合检测。
一、Introduction
问题:早期的深度伪造检测研究解决了空间伪影,但它们未能考虑由多帧组成的深度伪造视频中的时间伪影,最近的研究整合了时间线索,最新的生成算法有效地抑制了空间伪影和时间伪影,基于空间伪影、时间线索的方法都有性能下降
提出时间伪影的算法:StA(2024)、CSDA(2024),这篇论文在创作时应该还没有提出时间伪影
解决办法:
关注风格潜在特征时间流动的抑制方差(the suppressed variance in the temporal flow of style latent features)
style latent feature:编码面部外观和面部动作的信息,例如表情和几何变换,以控制面部图像的生成。
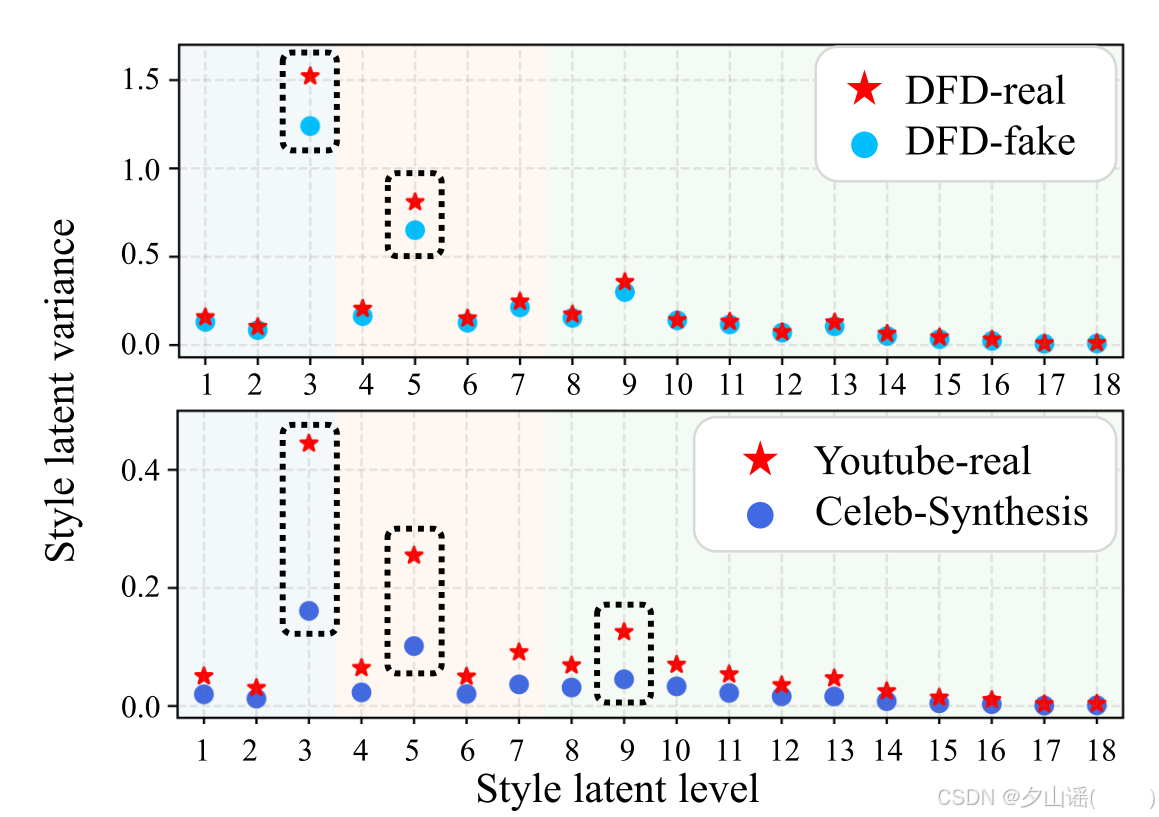
x轴:风格潜在向量的层级(level),代表不同粒度的风格表示(从细粒度到粗粒度)。
y轴:风格潜在向量的时间流动方差
表明:深伪视频为了生成时间上平滑、稳定的面部外观和动作,不可避免地会抑制风格潜在向量的时间变化,导致某些层级的方差显著低于真实视频。
问题:风格潜在向量的层级(粒度)是什么
总结论文贡献:
1.基于风格潜在向量的非自然变化的检测框架
2.StyleGRU(使用了对比学习):对风格潜在向量的变化进行编码,捕获风格潜在向量中的时间变化,提取基于风格的时间特征表示
3.style attention module:集成style-based temporal features 、包含时间和空间伪影的content features
二、Related work
基于图像的方法不能利用时间线索,基于视频的方法能够利用时间线索,但是现有的方法主要集中在像素这样的底层特征上,忽略了像面部属性这样的高层上下文的时间变化,论文提出的方法同时考虑了低层和高层的时间特征,从而增强了整体上下文,提高了深度伪造检测的水平。
Style Latent Vectors:训练良好的生成对抗网络(GAN)模型能够成功生成解耦的潜在空间,这一进步使得通过操作风格潜在特征来生成目标面部图像变得更加简单。GAN 反演技术最初由 [Generative visual manipulation on the natural image manifold] 提出,其目标是在潜在空间中找到一个潜在编码,从而生成与目标图像高度相似的图像。MegaFS [60] 进一步将源图像和目标图像都反演到经过精细调整的 StyleGAN 潜在空间中,以实现人脸交换。通过 GAN 反演进行人脸交换具有在潜在空间中分离面部身份并交换潜在特征的优势,从而在像 StyleGAN [20] 这样的模型中保持较高的真实感。此外,这种方法还被用于多种深度伪造生成技术,包括修改面部属性,而不仅限于改变面部身份。这些方法超越了现有的技术,例如通过直接修改风格潜在特征的 StyleRig [45]。基于 GAN 反演的人脸交换方法 [31, 53, 54] 继续展示出良好的性能。
论文同样采用基于 GAN 反演模型的风格潜在特征来表示面部属性的时间变化。考虑到最近的大多数 GAN 反演模型(包括基于 StyleGAN 架构的模型 [20])都利用了风格特征,类似的情况也适用于深度伪造生成模型的构建。因此,我们提出了使用 StyleGRU,这非常适合用于抵抗对最先进的深度伪造检测模型的攻击。
总结:
获取风格潜在特征的方法:GAN反演模型,使用训练良好的生成对抗网络。利用风格潜在特征在潜在空间实现人脸交换取得了良好的性能,那么利用real、fake视频在潜在特征空间的区别进行分类检测或许可行,(如果高质量deepfake生成方法再潜在特征空间交换生成人脸,这种方法获取更具有针对性)
三、Methodology
(1)StyleGRU module:为每个单独的帧提取pSp features,使用GRU将style latent vectors在时间上的变化编码为基于风格的时间特征(style-based temporal feature )
E
s
t
y
l
e
E_{style}
Estyle
(2) 3D ResNet-50 module:将视频clip编码为content feature
C
c
o
n
t
e
n
t
C_{content}
Ccontent
(3) Style Attention Module (SAM):通过注意力机制将
E
s
t
y
l
e
E_{style}
Estyle和
C
c
o
n
t
e
n
t
C_{content}
Ccontent结合
(4) Temporal Transformer Encoder(TTE):将结合的特征映射为二分类
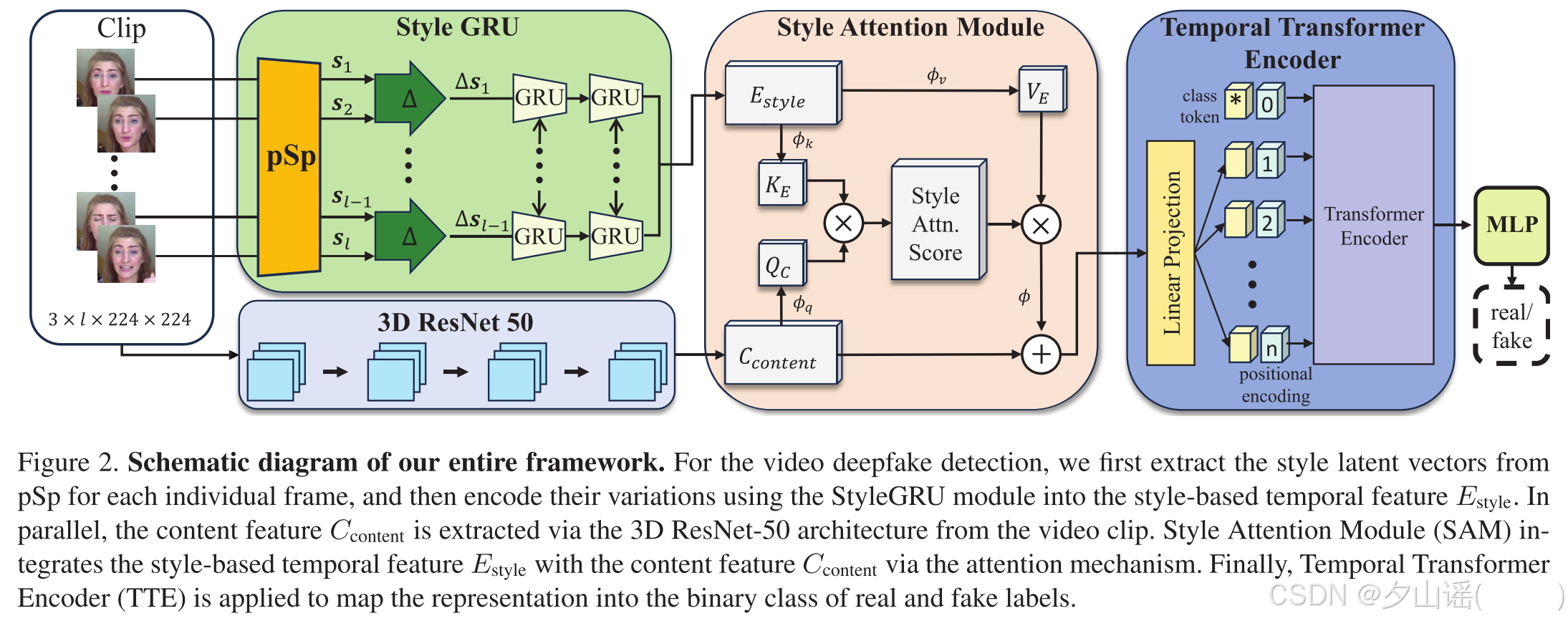
首先从pSp中提取每一帧的风格潜在向量,然后利用StyleGRU模块将其变化编码为基于风格的时间特征 E s t y l e E_{style} Estyle,同时利用3D ResNet-50架构从视频片段中提取内容特征 C c o n t e n t C_{content} Ccontent。风格注意模块(SAM)通过注意机制将基于风格的时间特征 E s t y l e E_{style} Estyle与内容特征 C c o n t e n t C_{content} Ccontent集成在一起。最后,利用TTE将表示映射为真实的标签的二元类。
3.1. Overall Architecture
3.1.1 Input configuration
输入:
l
l
l个连续帧的序列
I
I
I
I
I
I→检测并裁剪出所有帧中的人脸区域,经过了 FFHQ中定义的预处理步骤→resize
[
256
,
256
,
l
]
[256,256,l]
[256,256,l]→
I
p
I_p
Ip→styleGRU
I
I
I→resize
[
224
,
224
,
l
]
[224,224,l]
[224,224,l]→3DResNet50
FFHQ(Flickr-Faces-HQ Dataset)
A style-based generator architecture for generative adversarial networksh中提出的一个数据集
常见的预处理步骤包括:人脸检测与裁剪(dlib 或 MTCNN)、人脸对齐、图像标准化、去背景与增强
3.1.2 StyleGRU module
输入:
I
p
I_p
Ip,维度
[
256
,
256
,
l
]
[256,256,l]
[256,256,l]
pSp encoder(pSp):将图像逆映射到 StyleGAN 的潜在空间(Encoding in style: a stylegan encoder for image-to-image translation)
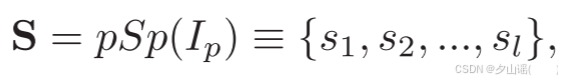
S
:
[
l
,
D
]
S :[l,D]
S:[l,D],为每一帧图像提取一个D维的风格特征表示


通过pSp编码器提取的风格特征向量是GAN反演任务的特征,不足以直接应用于深度伪造检测任务,通过相邻两帧的style latent vectors做差获取style flow
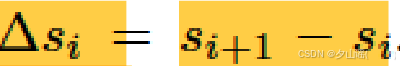
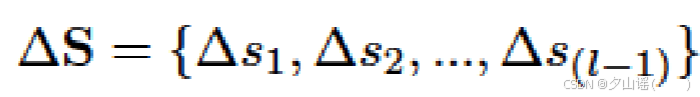
style flow
Δ
S
:
[
l
−
1
,
D
]
\Delta{S}:[l-1,D]
ΔS:[l−1,D]→输入GRU,获得temporal embedded style flow
E
s
t
y
l
e
E_{style}
Estyle
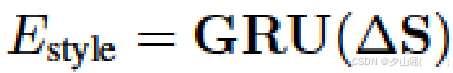
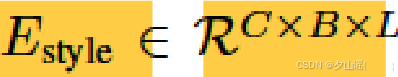
C 表示 GRU 的隐藏单元的个数,C=4096
B 表示 GRU 的方向数量,B=2
L 表示 GRU 的层数,L=2
3.1.3 3D ResNet-50 module
内容特征
C
c
o
n
t
e
n
t
,
[
1024
,
16
]
C_{content},[1024,16]
Ccontent,[1024,16]同时包括时间不一致和空间不一致,使用FTCN预训练的3DR50,通过在3D-ResNet-50的最后一个卷积层上应用全局平均池化,提取出大小为 1024×16 的特征
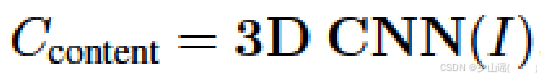
3.1.4 Style attention module(SAM)
C
c
o
n
t
e
n
t
C_{content}
Ccontent作为query,
E
s
t
y
l
e
E_{style}
Estyle作为key和value
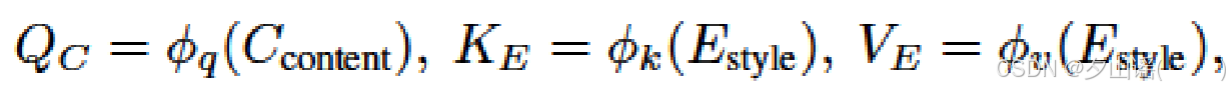

ϕ
q
、
ϕ
k
和
ϕ
v
ϕq、ϕk 和 ϕv
ϕq、ϕk和ϕv表示线性投影层
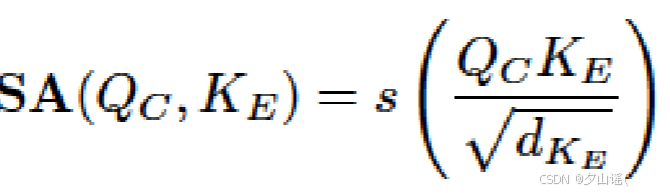
整个SAM:
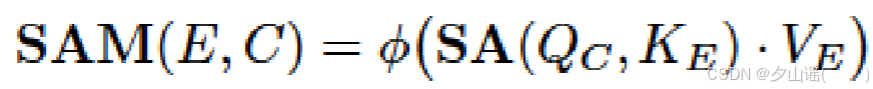

3.1.5 Temporal transformer encoder module
The output from the SAM is linearly projected into 16 time steps (n=16),然后输入TTE,TTE is composed of standard transformer encoder blocks
疑问:The output from the SAM is linearly projected into 16 time steps (n=16)是什么意思
TTE由多少个编码器组成
TTE架构见FTCN
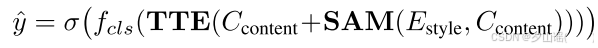
sigmoid function
σ
σ
σ,
f
c
l
s
f_{cls}
fcls:MLP,用于分类,其实就是classification head
3.2 Training Procedure
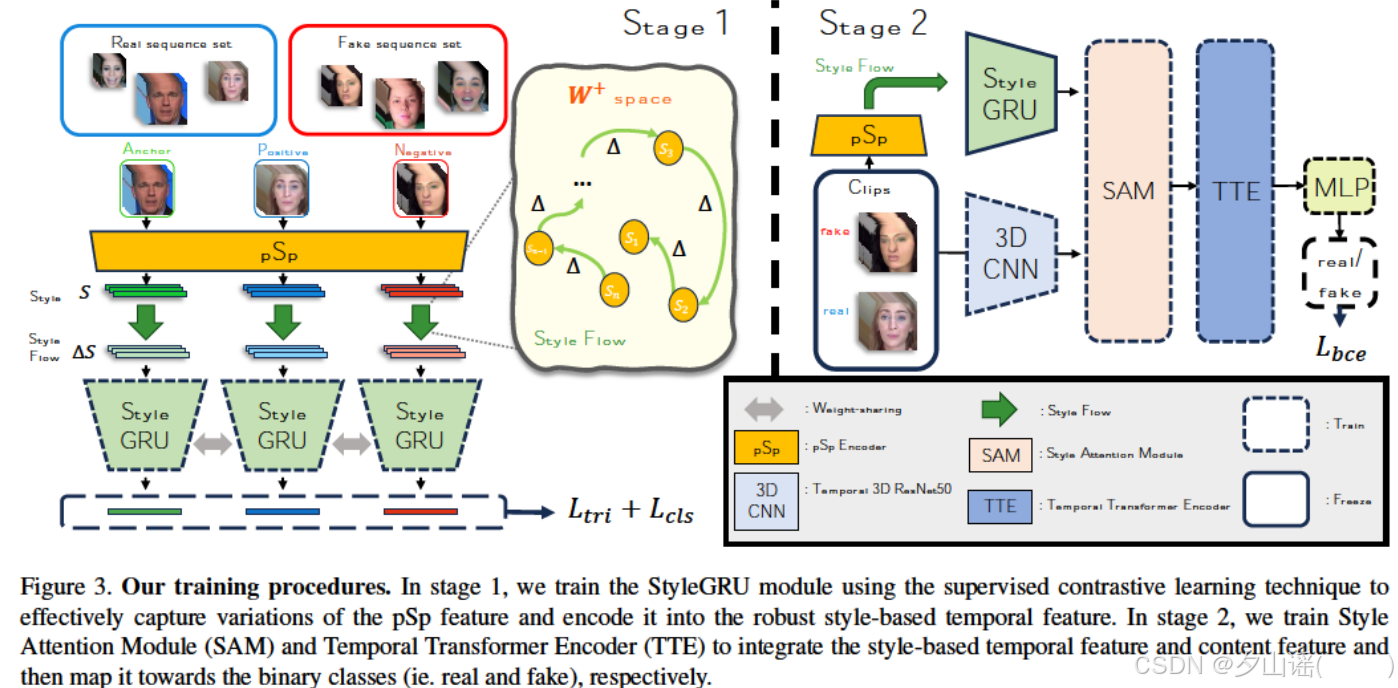
第1阶段,使用监督对比学习技术训练StyleGRU模块,以有效捕获pSp特征的变化并将其编码为鲁棒的基于风格的时间特征。
第2阶段,训练风格注意力模块(SAM)和时间变换编码器(TTE)来整合基于风格的时间特征和内容特征,然后将其映射到二进制类。
3.2.1 Stage 1: style representation learning
使用supervised contrastive learning和triplet loss、classification loss
获取clip:
anchor style flow (
∆
S
a
∆S_a
∆Sa):通过滑动窗口采样策略从视频序列中采样的clip中提取。
positive style flow (
∆
S
p
∆S_p
∆Sp):通过随机抽样策略,从和anchor具有相同标签的预处理片段中提取
为什么要随机采样,随机抽帧不是会损失时间信息吗
negative style flow (
∆
S
n
∆S_n
∆Sn):随机选择与 anchor 和 positive 样本标签不同的clip,随机选择使用滑动窗口采样策略或随机采样策略
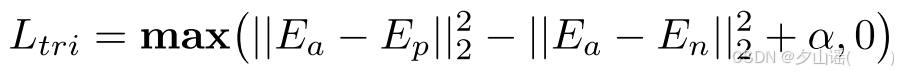
triplet loss:最小化anchor和positive的差异、最大化anchor和negative的差异
auxiliary classifier:GRU的隐藏状态E被输入到辅助分类器中来获得分类标签,辅助分类器:由三个全连接层组成,在前两个全连接层之后,应用了残差连接,每个全连接层的隐藏层大小(即神经元数量)为4096
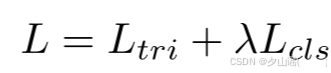
λ的值?
使用Adam optimizer
3.2.2 Stage 2: style attention-based deepfake detection.
固定the StyleGRU module,利用Binary Cross-Entropy (BCE) loss训练train the 3D ResNet-50, SAM, and TTE modules
0 is real and 1 is fake
使用SGD optimizer
四、 Experiments
Implementation Details:
- 使用Dlib提取面部特征点并进行对齐,使用Retinaface进行人脸裁剪
- 输入 l = 32 l=32 l=32
- 在stage1,style flow和StyleGRU之间包含一个dropout层,dropout rate of p = 0.2
- StyleGRU中,RNN dropout rate of p = 0.1
- 对比学习:50,000 samples,batch size of 256,over 100 epochs
- ADAM,learning rate of 5e−4
- stage 2,SGD,weight decay to 1e−4,batch size of 16
- 前10个epoch,SGD学习率从0.01逐渐升温到0.1,使用余弦学习率调度器(Cosine Annealing)降低100个epoch的学习率
Datasets and Measurement: - FF++(C23版本)、FaceShfiter (FSh)、DeeperForensics、CelebDF-v2 (CDF)、DeepfakeDetection (DFD)
- 使用FF++(C23版本)进行训练
4.1. Generalization to cross-datasets
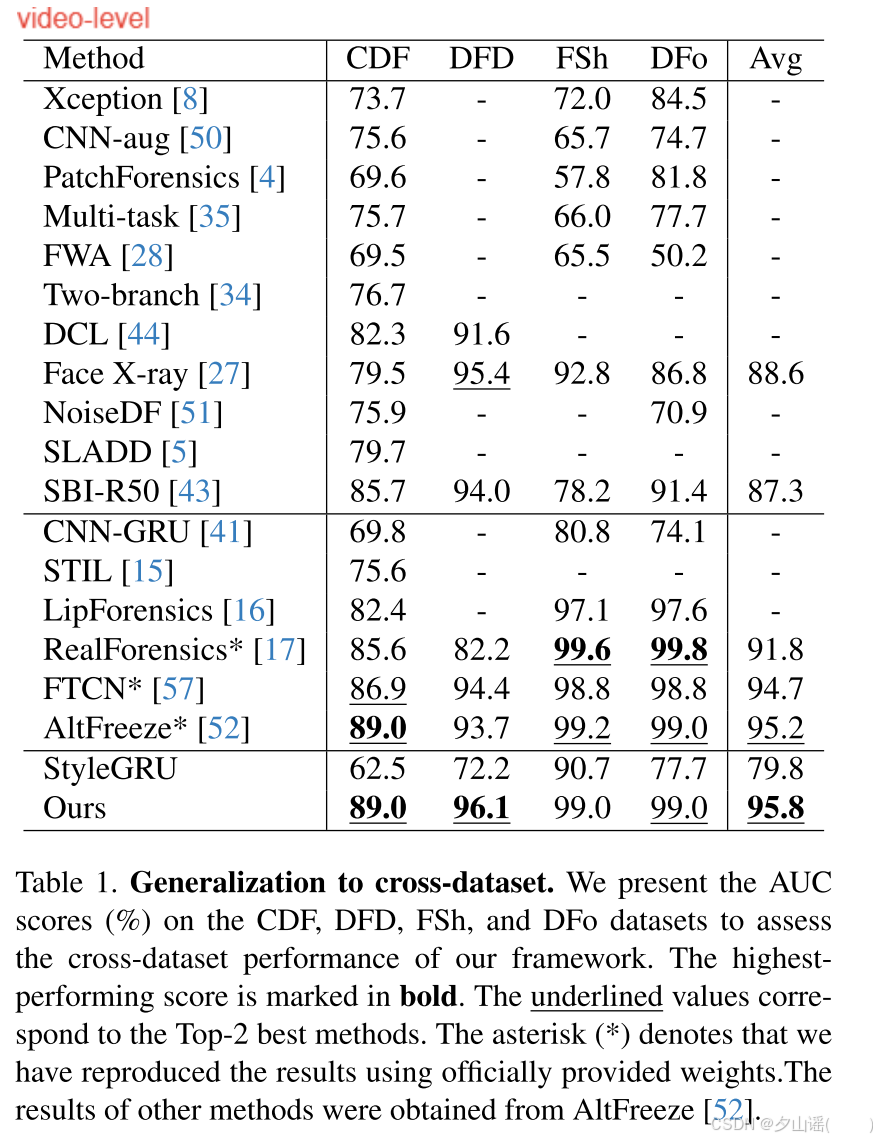
4.2. Generalization to cross-manipulations
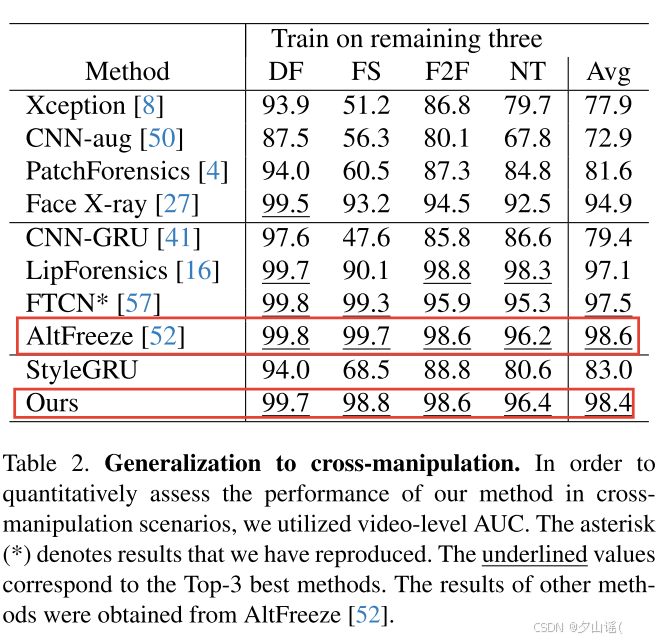
4.3. Ablation Study
4.3.1 Component-wise Ablation Study
没有StyleGRU的实验,使用MLP处理从clip中提取的样式潜在向量,以匹配3DCNN特征的维度。
没有SAM的实验中,简单地将StyleGRU特征添加到3DCNN特征中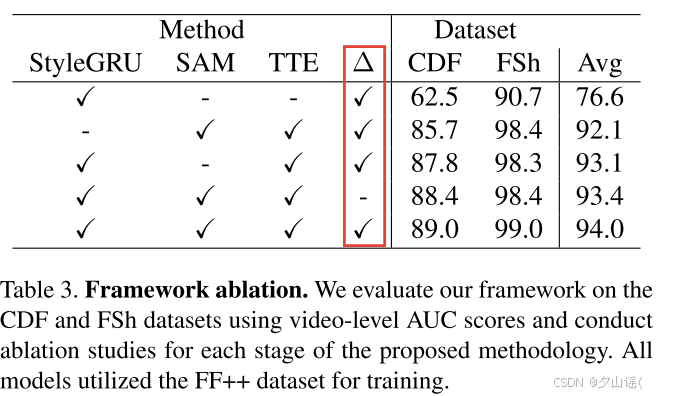
Finally, the influence of differentiating (∆) the style latent vectors is investigated by replacing the input of the style flow with the original style latent vectors.
过将风格流的输入替换为原始风格潜在向量,研究了区分(∆)风格潜向量的影响。
original style latent vectors应该是指提取的psp特征,即没有做差的风格潜在向量
4.3.2 Ablation Study for Losses
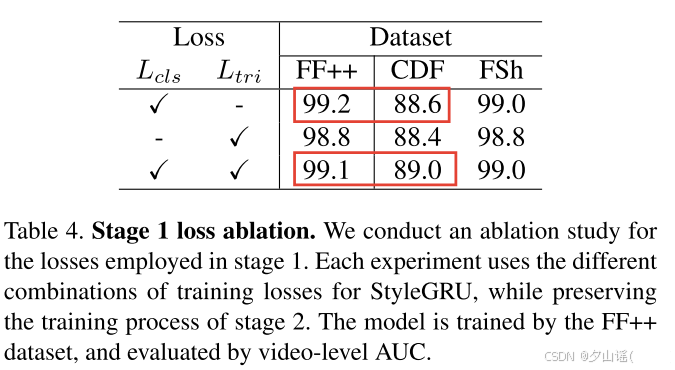
同时使用在可见数据集上的性能略有下降,对不可见数据集是有益的
4.4. Analytic Experiments
4.4.1 t-SNE for Domain Generalization

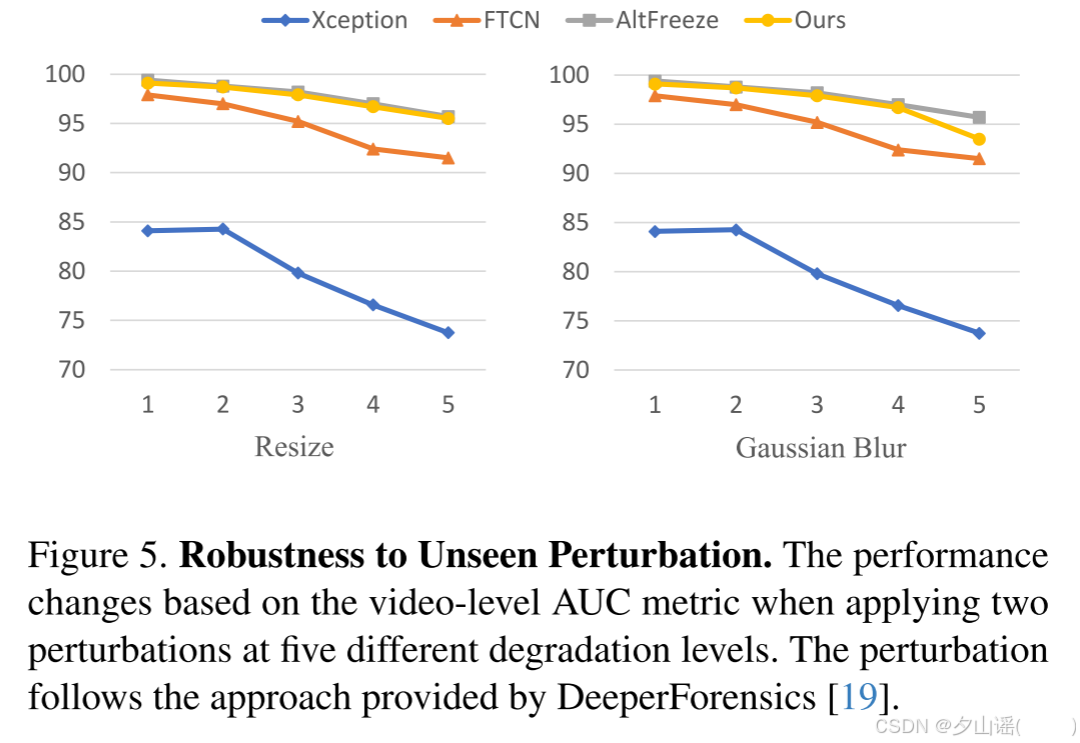
4.4.2 Robustness to Unseen Perturbation


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









