




 本文详细介绍了如何使用Python的库如python-pptx, python-docx, pytesseract等将PPT内容包括文字和图片转换成Word文档,并探讨了利用百度API和tesseract进行OCR识别的技巧,以及注意事项。
本文详细介绍了如何使用Python的库如python-pptx, python-docx, pytesseract等将PPT内容包括文字和图片转换成Word文档,并探讨了利用百度API和tesseract进行OCR识别的技巧,以及注意事项。
一、Python安装和卸载库的方法
1.1 安装
在搜索栏搜索cmd,然后输入pip install +库名字,举个例子,需要安装python-pptx,那就输入 pip install python-docx。

1.2 卸载
在搜索栏搜索cmd,然后输入pip uninstall +库名字,举个例子,需要卸载python-pptx,那就输入 pip uninstall python-docx。
二、工具
我所使用的是pycharm,个人感觉比较好用。
下载配置教程可点击这里

三、将PPT内容转化为Word
3.1 将PPT文本框里的文字转化为Word
3.1.1 需要的库
所需要下载的库为:python-pptx和python-docx两个。
3.1.2 实现代码
from pptx import Presentation
from docx import Document
wordfile = Document()
# 给定ppt文件所在的路径
filepath = r'E:\vs\w.pptx'
pptx = Presentation(filepath)
# 遍历ppt文件的所有幻灯片页
for slide in pptx.slides:
# 遍历幻灯片页的所有形状
for shape in slide.shapes:
# 判断形状是否含有文本框,如果含有则顺序运行代码
if shape.has_text_frame:
# 获取文本框
text_frame = shape.text_frame
# 遍历文本框中的所有段落
for paragraph in text_frame.paragraphs:
# 将文本框中的段落文字写入word中
wordfile.add_paragraph(paragraph.text)
#word文档存放的路径
save_path = r'E:\vs\w.docx'
wordfile.save(save_path)
3.1.3 具体解释
具体的解释可以点击这里
或者这一个
需要注意的地方就是里面的Document后面的*要去掉,要不然会报错,还有在wordfile.add_paragraph(paragraph.text这一句中少了)。
3.2将PPT的图片也输出出来
3.2.1 需要的库
所需要下载的库为:python-pptx。
3.2.2 实现代码
如果有图片的话,会直接存放当前Pycharm的项目文件夹之中。
from pptx import Presentation
from pptx.shapes.picture import Picture
prs = Presentation("E:\k\w.pptx")#这是你ppt的路径
index = 1
#读取幻灯片的每一页
for slide in prs.slides:
# 读取每一板块
for shape in slide.shapes:
# print(dir(shape))
#是否有文字框
if shape.has_text_frame:
#读文字框的每一段落
for paragraph in shape.text_frame.paragraphs:
if paragraph.text:
# 输出段落文字,也有一些属性,可以用dir查看
# print(dir(paragraph))
print(paragraph.text)
#是否有表格
elif shape.has_table:
one_table_data = []
for row in shape.table.rows: # 读每行
row_data = []
for cell in row.cells: # 读一行中的所有单元格
c = cell.text
row_data.append(c)
one_table_data.append(row_data) # 把每一行存入表
#用二维列表输出表格行和列的数据
print(one_table_data)
# 是否有图片
elif isinstance(shape, Picture):
#shape.image.blob:二进制图像字节流,写入图像文件
with open(f'{index}.jpg', 'wb') as f:
f.write(shape.image.blob)
index += 1
四、利用OCR将图片信息存放在Word里
4.1 使用百度的api
4.1.1 需要的库
所需要下载的库为:baidu-aip和python-docx两个。
4.1.2 实现代码
# 从相应的aip导入AipOcr模块
from aip import AipOcr
from docx import Document
wordfile = Document()
# 输入凭证
APP_ID = "19307867"
API_Key = "HM1UDlzRPrr7TE6xw9YHDSnZ"
Secret_Key = "6jUGVGRLMrbByWz0vPs5w5NOS8m6GMOl"
aipOcr = AipOcr(APP_ID, API_Key, Secret_Key)
# 输入资源
filePath = r"D:\pythonProject"
for i in range(1, 499):
filePath1 = filePath + "\\" + str(i) + ".jpg" # 最好是jpg,名称统一
image = open(filePath1, "rb").read()
# 接通ocr接口
result = aipOcr.basicGeneral(image)
# 输出
mywords = result["words_result"]
for i in range(len(mywords)):
print(mywords[i]["words"])
wordfile.add_paragraph(mywords[i]["words"])
save_path = r'E:\vs\w.docx'
wordfile.save(save_path)
4.1.3 具体解释
4.1.4 存在的问题
这个是直接调用api的,调用多次的话就会失效,需要过一段时间才可以再次调用。所以,需要大批量的识别的话,不建议这种方式。
4.2 基于tesseract的OCR识别
4.2.1 需要的库和软件
所需要下载的库为:python-pptx、pytesseract和pillow。
所需要下载的软件为 tesseract
具体安装和配置方法参考其他博主
4.2.2 实现代码
from PIL import Image
import pytesseract
import pptx
image = Image.open(r'2.jpg')#打开图片
result = pytesseract.image_to_string(image,lang='eng')#使用简体中文字库识别图片并返回结果
print(result)#打印识别的图片内容
4.2.3 具体解释
Python3使用 pytesseract 进行图片识别
Python3.6实现图片转文字
4.2.4 存在的问题
这一个方法识别率刚好不符合我的要求,因为它不可以很好的识别出图片里面数字的正负。
4.3 一些另外的方法
4.3.1 需要安装的库
所需要下载的库为:requests和python-docx(要转化为word才需要)。
4.3.2 实现代码
import requests
import base64
from docx import Document
wordfile = Document()
def ocr(img_path: str) -> list:
'''
根据图片路径,将图片转为文字,返回识别到的字符串列表
'''
# 请求头
headers = {
'Host': 'cloud.baidu.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36 Edg/89.0.774.76',
'Accept': '*/*',
'Origin': 'https://cloud.baidu.com',
'Sec-Fetch-Site': 'same-origin',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Dest': 'empty',
'Referer': 'https://cloud.baidu.com/product/ocr/general',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
}
# 打开图片并对其使用 base64 编码
with open(img_path, 'rb') as f:
img = base64.b64encode(f.read())
data = {
'image': 'data:image/jpeg;base64,'+str(img)[2:-1],
'image_url': '',
'type': 'https://aip.baidubce.com/rest/2.0/ocr/v1/general_basic',
'detect_direction': 'false'
}
# 开始调用 ocr 的 api
response = requests.post(
'https://cloud.baidu.com/aidemo', headers=headers, data=data)
# 设置一个空的列表,后面用来存储识别到的字符串
ocr_text = []
result = response.json()['data']
if not result.get('words_result'):
return []
# 将识别的字符串添加到列表里面
for r in result['words_result']:
text = r['words'].strip()
ocr_text.append(" ")
ocr_text.append(text)
wordfile.add_paragraph(ocr_text)
# 返回字符串列表
return ocr_text
'''
img_path 里面填图片路径,这里分两种情况讨论:
第一种:假设你的代码跟图片是在同一个文件夹,那么只需要填文件名,例如 test1.jpg (test1.jpg 是图片文件名)
第二种:假设你的图片全路径是 D:/img/test1.jpg ,那么你需要填 D:/img/test1.jpg
'''
for i in range(300, 400):
img_path10 = str(i) + ".jpg"
content = "".join(ocr(img_path10))
print(content)
# img_path = '2.jpg'
# # content 是识别后得到的结果
# content = "".join(ocr(img_path))
# # 输出结果
# print(content)
save_path = r'E:\vs\前400.docx'
wordfile.save(save_path)
4.3.3 具体解释
4.3.4 存在的问题
这一个实质上也是在调用api接口,所以调用多次后会失效,需要过一阵子才可以继续使用。
五、注意点
Python的解释器最好选择你安装Python路径下面的python.exe,这样可以避免你安装了一些库,但是你编译的时候显示找不到库的问题。
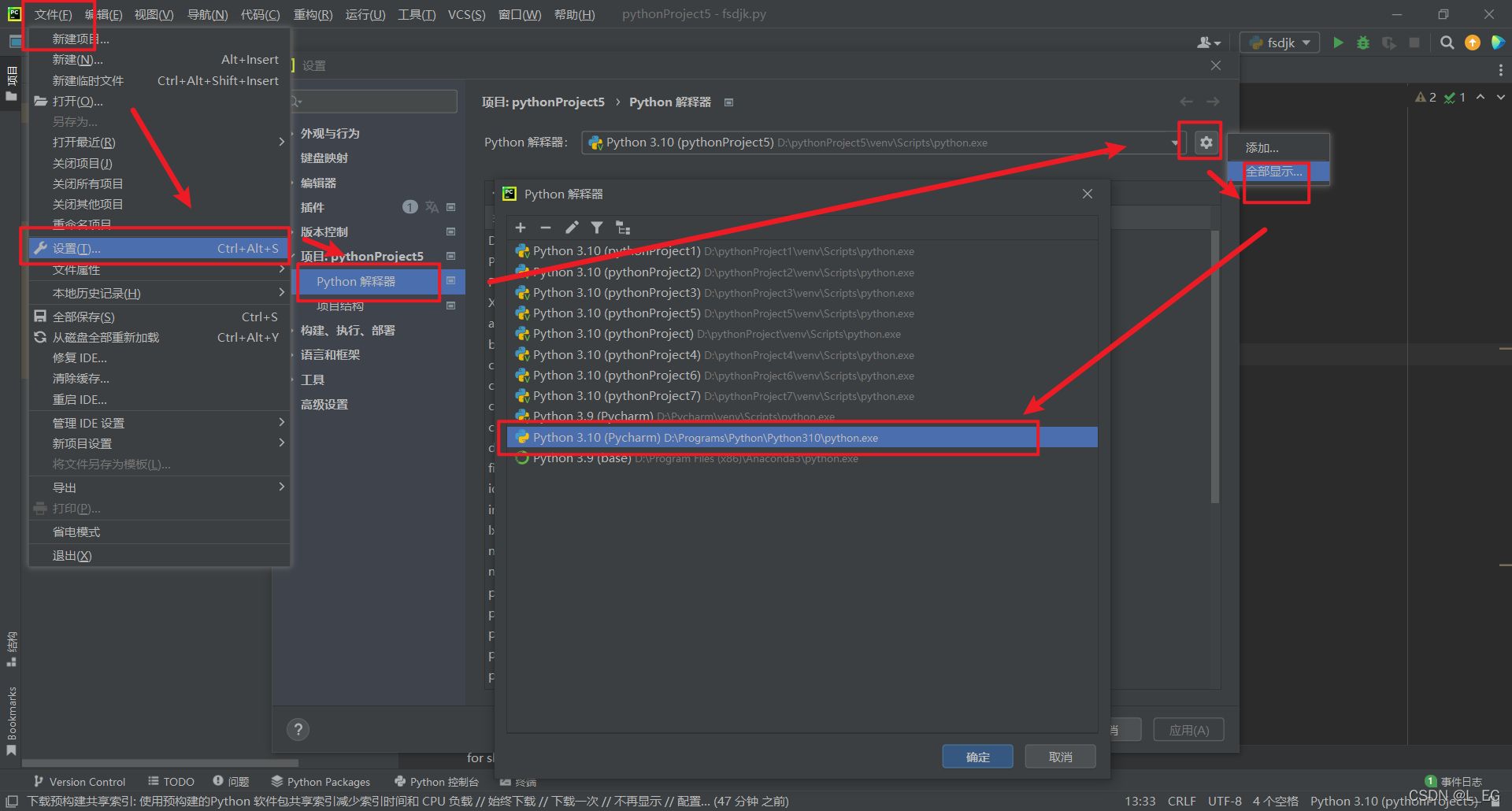
--------------------------------下面未整理------------------------------
出现的问题
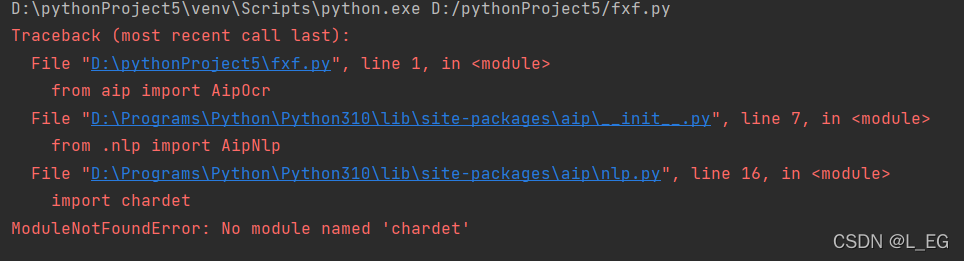



















 2188
2188

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









