






 本文详细介绍了HDFS的基本操作,包括文件上传、下载、移动和删除。在文件上传过程中,客户端首先创建FileSystem对象,然后通过DistributedFileSystem与NameNode交互,选择DataNode进行数据块的上传。NameNode会考虑距离因素选择接收节点。文件下载则涉及从HDFS到本地的复制。同时,文章还阐述了HDFS的写数据流程,包括NameNode的检查、Block的分配、数据的分块传输等步骤。
本文详细介绍了HDFS的基本操作,包括文件上传、下载、移动和删除。在文件上传过程中,客户端首先创建FileSystem对象,然后通过DistributedFileSystem与NameNode交互,选择DataNode进行数据块的上传。NameNode会考虑距离因素选择接收节点。文件下载则涉及从HDFS到本地的复制。同时,文章还阐述了HDFS的写数据流程,包括NameNode的检查、Block的分配、数据的分块传输等步骤。
对HDFS进行操作,需要先新建FileSystem对象
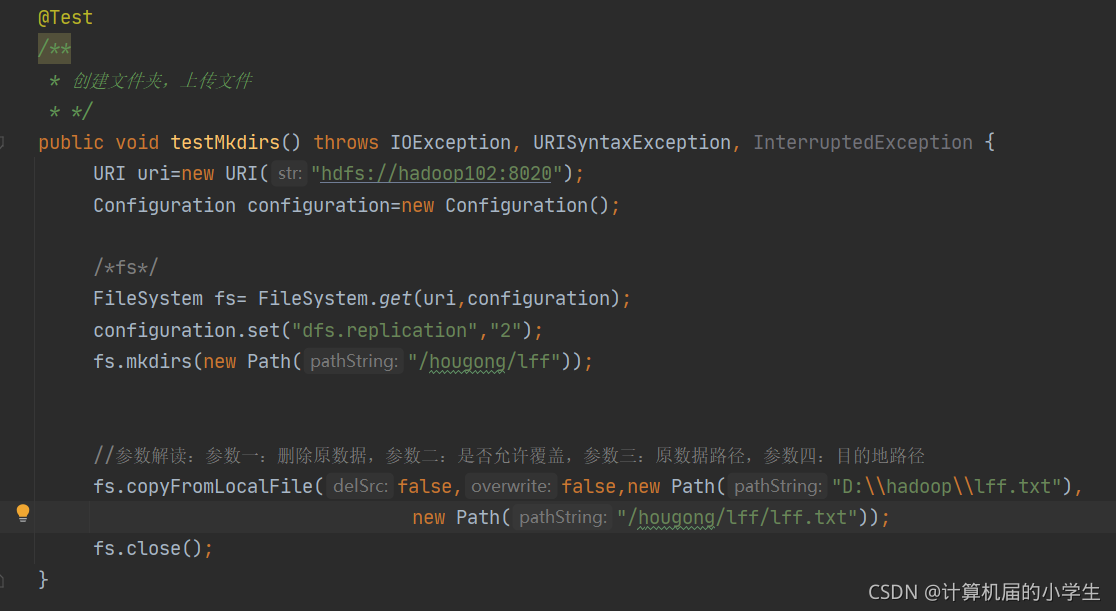
1.文件上传
FileSystem fs= FileSystem.get(uri,configuration);
fs.mkdirs(new Path("/hougong/lff"));
//参数解读:参数一:删除原数据,参数二:是否允许覆盖,参数三:原数据路径,参 数 四:目的地路径
fs.copyFromLocalFile(false,false,new Path(“D:\hadoop\lff.txt”),new Path("/hougong/lff/lff.txt"));
fs.close();
}
2.文件下载:
// boolean delSrc 指是否将原文件删除 // Path src 指要下载的文件路径 // Path dst
指将文件下载到的路径 // boolean useRawLocalFileSystem 是否开启文件校验public void copyToLocalFile(boolean delSrc, Path src, Path dst, boolean useRawLocalFileSystem)
3.文件移动和更名
var1:原路径和文件名 var2:目标路径和文件名
public abstract boolean rename(Path var1, Path var2)
4.删除文件和目录
public abstract boolean delete(Path var1, boolean var2)
二.HDFS读写流程
1.HDFS写数据流程
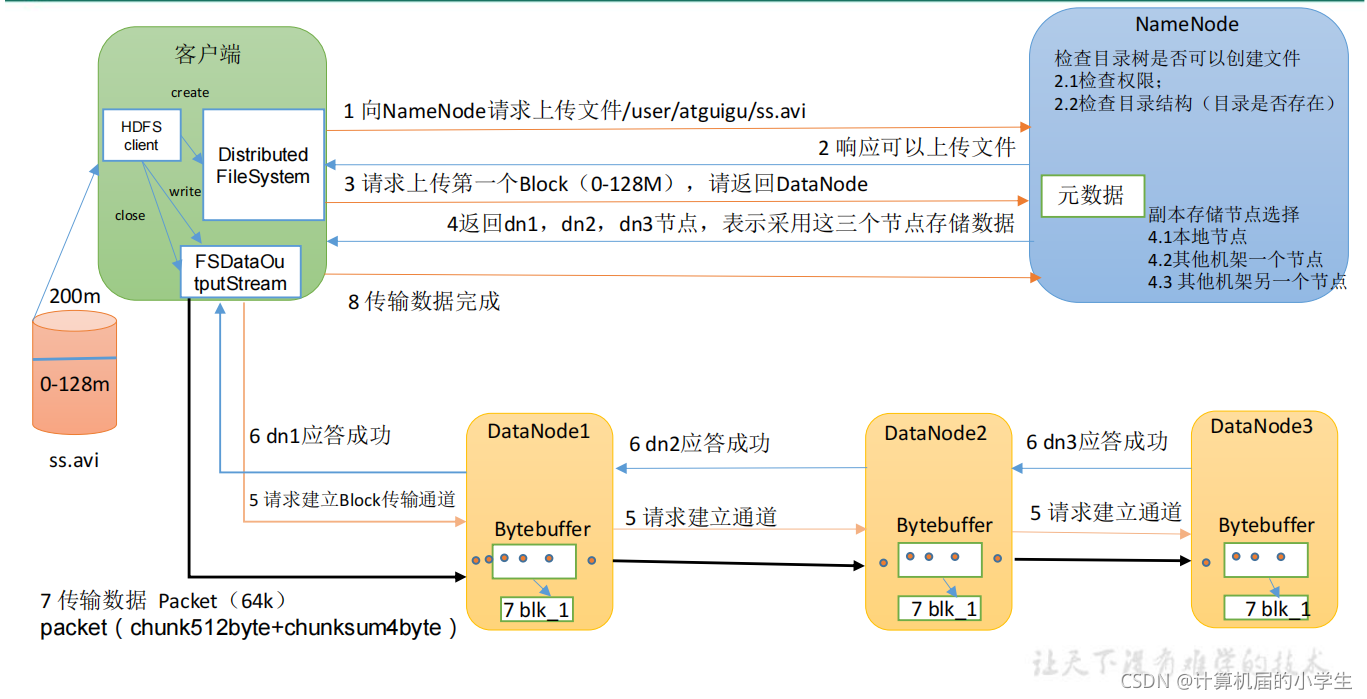 (1)客户端通过 Distributed FileSystem 模块向 NameNode 请求上传文件,NameNode 检
(1)客户端通过 Distributed FileSystem 模块向 NameNode 请求上传文件,NameNode 检
查目标文件是否已存在,父目录是否存在。
(2)NameNode 返回是否可以上传。
(3)客户端请求第一个 Block 上传到哪几个 DataNode 服务器上。
(4)NameNode 返回 3 个 DataNode 节点,分别为 dn1、dn2、dn3。
(5)客户端通过 FSDataOutputStream 模块请求 dn1 上传数据,dn1 收到请求会继续调用
dn2,然后 dn2 调用 dn3,将这个通信管道建立完成。
(6)dn1、dn2、dn3 逐级应答客户端。
(7)客户端开始往 dn1 上传第一个 Block(先从磁盘读取数据放到一个本地内存缓存),
以 Packet 为单位,dn1 收到一个 Packet 就会传给 dn2,dn2 传给 dn3;dn1 每传一个 packet会放入一个应答队列等待应答。
(8)当一个 Block(数据块) 传输完成之后,客户端再次请求 NameNode 上传第二个 Block 的服务器。(重复执行 3-7 步)。
2.计算节点距离
在 HDFS 写数据的过程中,NameNode 会选择距离待上传数据最近距离的 DataNode 接
收数据。
节点距离:两个节点到达最近的共同祖先的距离总和。
3.HDFS的写数据流程

















 3606
3606

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









