







 本文介绍了K-近邻算法的基本原理,包括算法的概念、优缺点以及一般流程。通过一个约会网站配对的例子,展示了如何使用该算法处理数据,包括数据准备、分析、归一化和模型测试。文章还提供了算法实现的代码示例,强调了特征归一化在处理不同尺度特征时的重要性,并给出了一个简单的命令行应用示例,让用户输入特征来预测匹配类型。
本文介绍了K-近邻算法的基本原理,包括算法的概念、优缺点以及一般流程。通过一个约会网站配对的例子,展示了如何使用该算法处理数据,包括数据准备、分析、归一化和模型测试。文章还提供了算法实现的代码示例,强调了特征归一化在处理不同尺度特征时的重要性,并给出了一个简单的命令行应用示例,让用户输入特征来预测匹配类型。
一、引言
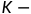 近邻
近邻  算法,也叫
算法,也叫  最近邻算法,1968年由
最近邻算法,1968年由 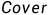 和
和 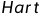 提出,是机器学习算法中比较成熟的算法之一。近邻算法使用的模型实际上对应于对特征空间的划分。
提出,是机器学习算法中比较成熟的算法之一。近邻算法使用的模型实际上对应于对特征空间的划分。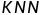 算法不仅可以用于分类,还可以用于回归。
算法不仅可以用于分类,还可以用于回归。
二、K-近邻算法内容
1、概念
近邻算法就是,先给定一个训练数据集,这个数据集中可能是某类物品的特征及分类,然后给出某个物品的特征,根据训练数据集中的各个物品的特征与这个需要判别分类的物品的“距离”远近,找出距离最近的 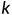 个,然后这 个物品中最多物品所归属的那个分类就是这个需要判别的物品所归属分类判断的结果。
个,然后这 个物品中最多物品所归属的那个分类就是这个需要判别的物品所归属分类判断的结果。
2、优缺点
优点: 精度高、对异常值不敏感、无数据输入假定。
缺点: 计算复杂度高、空间复杂度高。
3、算法的一般流程
(1) 收集数据
可以使用任何方法(爬虫、网络上公开的数据集等)
(2) 准备数据
距离计算所需要的数值,最好是结构化的数据格式(一般是用些
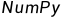 矩阵或者数组这种来方便储存结构化后的数据)
矩阵或者数组这种来方便储存结构化后的数据)
(3) 分析数据
可以用任何方法(一般常用
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 9万+
9万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











