







一、Xgboost是怎么预测的
在XGBoost用于二分类问题时,模型会构建多棵决策树,每棵树的叶子节点会有相应的分数(或称为权重)。这些分数在所有树中对应叶子节点的分数会被累加起来,形成一个总和。
这个总和可以被视为样本属于正类(通常是1)的对数几率(log-odds)。为了将这个总和转换成概率值,通常会通过Sigmoid函数进行变换。Sigmoid函数的形式为:
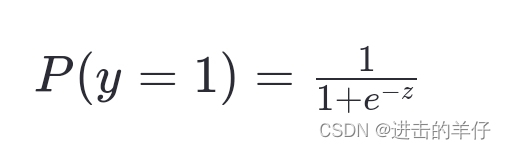
其中 z 就是所有树的叶子节点分数之和。经过Sigmoid函数变换后,输出值会被限制在0到1之间,可以解释为样本属于正类的概率。
因此,在XGBoost的二分类任务中,最终的预测结果是通过上述过程计算得到的。如果要得到的是类别标签而非概率,通常会设定一个阈值(例如0.5),根据这个阈值来决定样本最终被分类为正类还是负类。
二、XGBoost中叶子节点值如何计算?
在XGBoost中,叶子节点的值是通过优化目标函数来确定的。具体来说,XGBoost在构建每一棵树时,会尝试最小化一个包含损失项和正则化项的目标函数。对于第\( t \)棵树,目标函数可以表示为:

为了简化计算,XGBoost采用了一阶导数(梯度)和二阶导数(Hessian)来近似损失函数的变化,从而推导出叶子节点值的更新公式。对于每个叶子节点,其值的更新可以通过以下公式计算:

通过这种方式,XGBoost能够有效地计算出每个叶子节点的值,同时通过正则化项来平衡模型的复杂度和泛化能力。
三、正则化项公式
正则化项通常包括两个部分:一个是与叶子节点数量相关的项,另一个是与叶子节点输出值大小相关的项。具体的正则化项公式如下:

通过这两个正则化项,XGBoost能够在优化目标函数时,不仅考虑损失函数的最小化,还考虑了模型的复杂度,从而达到更好的泛化性能。

















 2354
2354

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









