







 论文提出GraphAttentionNetworks(GATs),一种利用自注意力解决图卷积局限的神经网络,能在不同大小邻域中赋予节点不同权重,适用于归纳学习。实验结果显示在多个节点分类任务中表现出先进性能。
论文提出GraphAttentionNetworks(GATs),一种利用自注意力解决图卷积局限的神经网络,能在不同大小邻域中赋予节点不同权重,适用于归纳学习。实验结果显示在多个节点分类任务中表现出先进性能。
Graph Attention Network
- 作者:Petar Veličković、Guillem Cucurull、Arantxa Casanova、Adriana Romero、Pietro Liò
- 来源:ICLR(国际表征学习大会,是深度学习领域的顶级会议)
- 时间:2018年
- 链接:Graph Attention Network (arxiv.org)
Abstract
论文提出了图注意力网络(GATs),一种操作于图结构数据的新型神经网络架构,利用隐藏的自注意层来解决基于图卷积或其近似的先前方法的缺点。通过堆叠层,其中节点能够关注其邻域的特征,能够(隐式地)为邻域中的不同节点指定不同的权重,而不需要任何类型的代价高昂的矩阵操作(如反转)或依赖于预先知道图结构。通过这种方式,同时解决了基子频谱的图神经网络的几个关键挑战,并使模型易于适用于归纳和传导问题。
Introduction
卷积神经网络(CNN)已成功用于图像分类,语义分割,机器翻译等方面。
-
问题
许多有趣的任务涉及到不能用网格状结构表示的数据,而是位于不规则域中。这是3D网格﹑社交网络、电信网络、生物网络或大脑连接体的情况。这类数据通常可以用图表的形式表示。
-
解决办法
(1)光谱方法:受图形结构影响较大,在特定结构上训练的模型不能直接应用于具有不同结构的图。
(2)非光谱方法(论文所用):这些方法的挑战之一是定义一个算子,它适用于不同大小的邻域,并保持 CNN 的权值共享属性。在某些情况下,这需要学习每个节点度的特定权重矩阵,使用转换矩阵的幂来定义邻域,同时学习每个输入通道和邻域度的权重,或者提取并规范化包含固定数量节点的邻域。 -
注意力机制的好处之一是,它们允许处理可变大小的输入,专注于输入中最相关的部分来做出决策。当一种注意机制被用来计算单个序列的表示时,它通常被称为自我注意或内部注意。
本文引入了一种基于注意力的架构来执行图结构数据的节点分类。
其思想是计算图中每个节点的隐藏表示,通过关注它的邻居,遵循自关注策略。注意结构有几个有趣的特性:(1)操作是有效的、因为它在节点-邻居对之间是并行的;(2)通过给邻居指定任意权值,可以应用到不同度的图节点上;(3)该模型直接适用于归纳学习问题,包括模型必须推广到完全看不见的图的任务。
GAT ARCHITECTURE
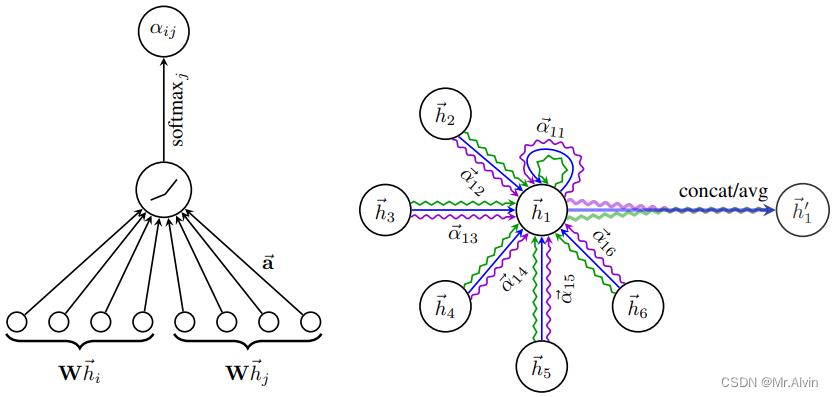
-
左图:模型使用的注意力机制,由权重向量参数化,应用 LeakyReLU 激活。
-
右图:节点1在其邻域上的多头注意力(具有K=3头)的说明。不同的箭头样式和颜色表示独立的注意力计算。来自每个头部的聚合特征被连接或平均以获得。
-
图注意力层
注意力层的输入是一组节点特征 h = { h ⃗ 1 , h ⃗ 2 , … , h ⃗ N } , h ⃗ i ∈ R F \mathbf{h}=\{\vec{h}_1,\vec{h}_2,\dots,\vec{h}_N\},\vec{h}_i\in\R^F h={ h1,h2,…,hN},hi∈RF,其中 N N N 是节点的数量, F F F 是每个节点中的特征的数量。该层生成一组新的节点特征(可能具有不同的基数 F ′ F^′ F′), h ′ = { h ⃗ 1 ′ , h ⃗ 2 ′ , … , h ⃗ N ′ } , h ⃗ i ′ ∈ R F ′ h^′=\{\vec{h}_1^′,\vec{h}_2^′,\dots,\vec{h}_N^′\},\vec{h}_i^′\in\R^{F^′} h′={ h1′
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5747
5747

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









