







1、线上服务
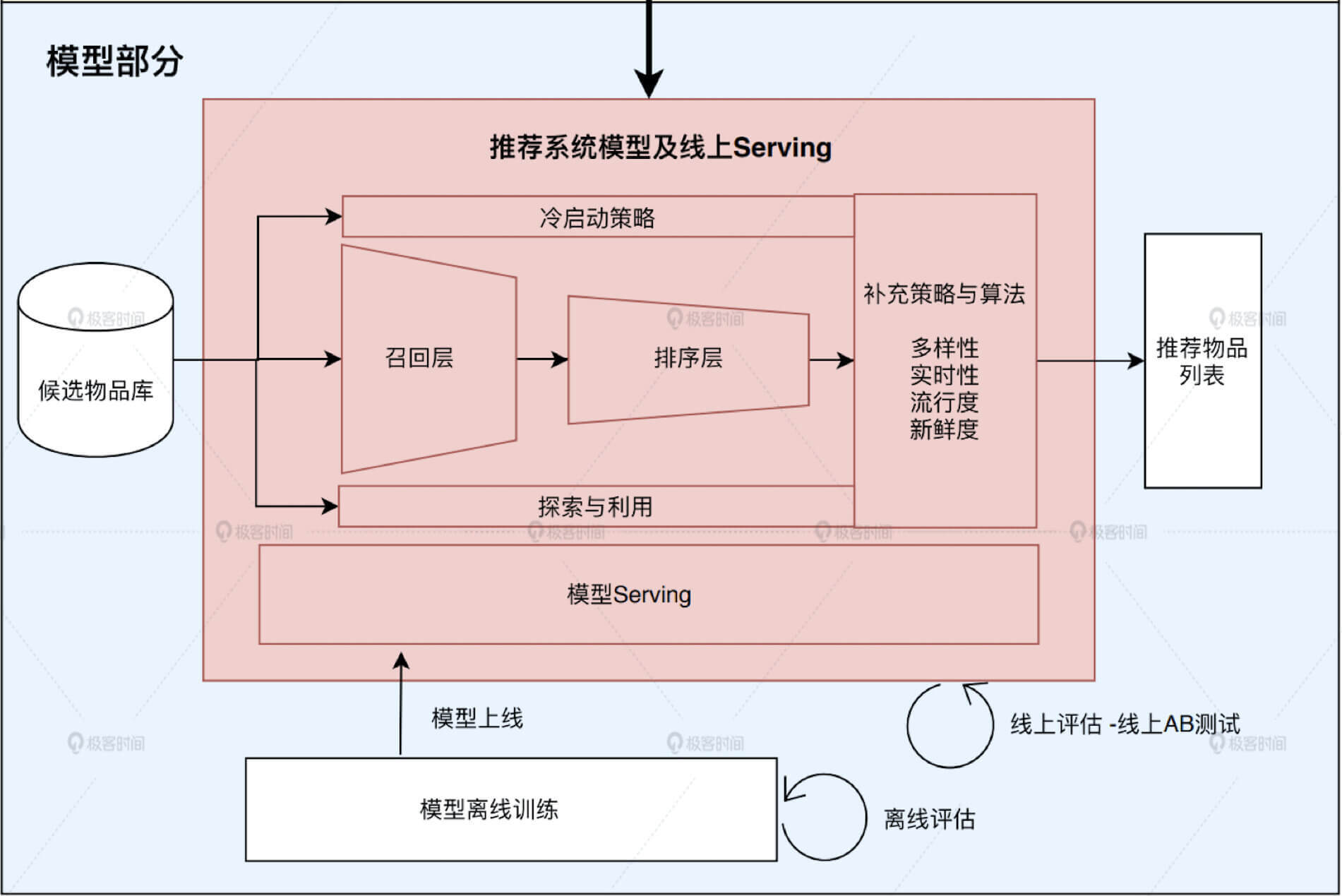
总之,“负载均衡”提升服务能力,“缓存”降低服务压力,“服务降级”机制保证故障时刻的服务不崩溃,压力不传导,这三点可以看成是一个成熟稳定的高并发推荐服务的基石。
2、存储模块(数据存储到数据库/内存中)
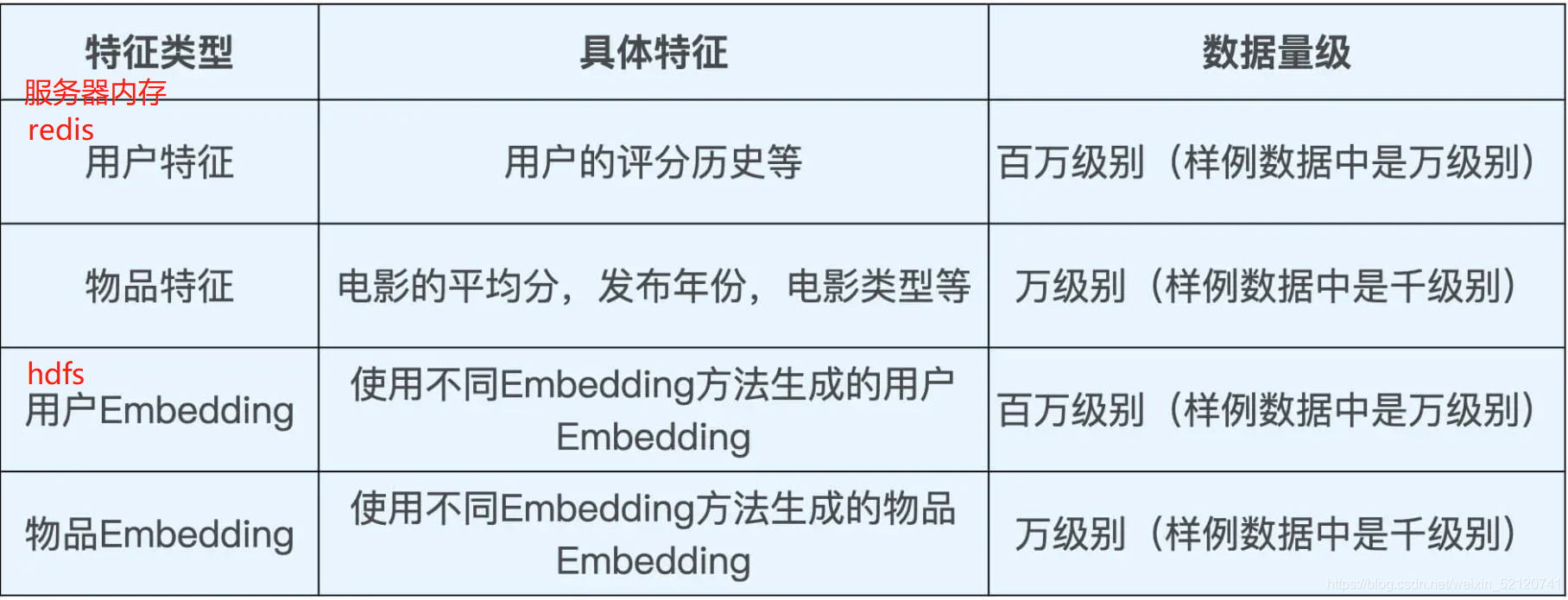
离线的特征数据是如何导入到线上让推荐服务器使用的呢?
把特征的存储做成分级存储,把越频繁访问的数据放到越快的数据库甚至缓存中,把海量的全量数据放到便宜但是查询速度较慢的数据库中。
使用基础的文件系统保存全量的离线特征和模型数据,用 Redis 保存线上所需特征和模型数据,使用服务器内存缓存频繁访问的特征。
3、召回层策略
在推荐物品候选集规模非常大的时候,我们该如何快速又准确地筛选掉不相关物品,从而节约排序时所消耗的计算资源呢?这其实就是推荐系统召回层要解决的问题。
召回层就是要快速、准确地过滤出相关物品,缩小候选集,
排序层则要以提升推荐效果为目标,作出精准的推荐列表排序。
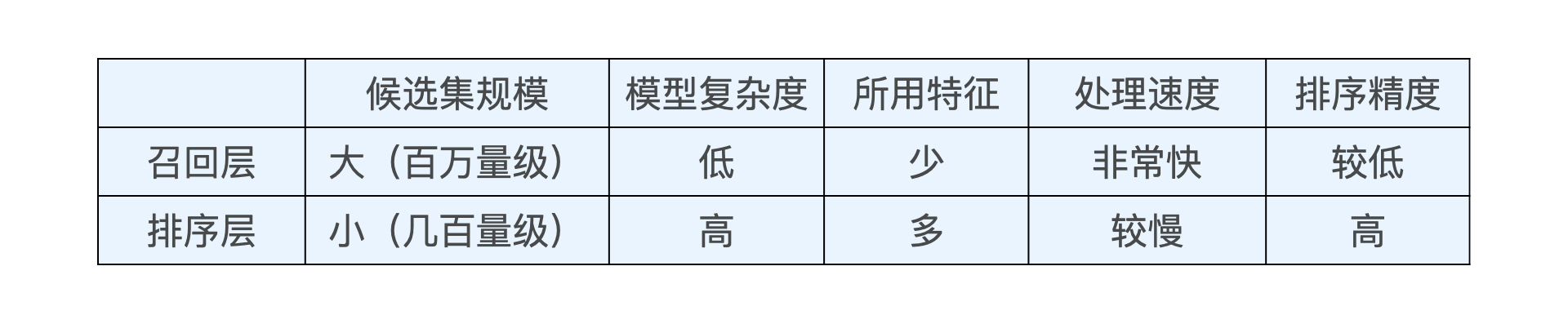
计算速度 vs 召回率 都需要考量,发展出三个主要的召回方法:
-
单策略召回
通过制定一条规则或者利用一个简单模型来快速地召回可能的相关物品。
优点:
计算速度快
在推荐电影的时候,我们首先要想到用户可能会喜欢什么电影。按照经验来说,很有可能是这三类,分别是大众口碑好的、近期非常火热的,以及跟我之前喜欢的电影风格类似的。
缺点:
用户的兴趣是非常多元的,他们不仅喜欢自己感兴趣的,也喜欢热门的,当然很多时候也喜欢新上映的。这时候,单一策略就难以满足用户的潜在需求了
-
多路召回
采用不同的策略、特征或简单模型,分别召回一部分候选集,然后把候选集混合在一起供后续排序模型使用的策略。
优点:
各简单策略保证候基于 Embedding 的召回方法选集的快速召回,从不同角度设计的策略又能保证召回率接近理想的状态,不至于损害排序效果。
缺点:
在确定每一路的召回策略和候选级大小参数等,都需要大量的人工参与;且各策略之间的信息是割裂的,无法综合考虑不同策略对同一个物品的影响
-
基于 Embedding 的召回方法
利用物品和用户 Embedding 相似性来构建召回层,是深度学习推荐系统中非常经典的技术方案

4、局部敏感哈希(业界解决近似 Embedding 搜索的主要方法)
如何快速找到与一个 Embedding 最相似的 Embedding?
召回与用户向量最相似的物品 Embedding 向量这一问题,其实就是在向量空间内搜索最近邻的过程:聚类、索引(kd-tree)

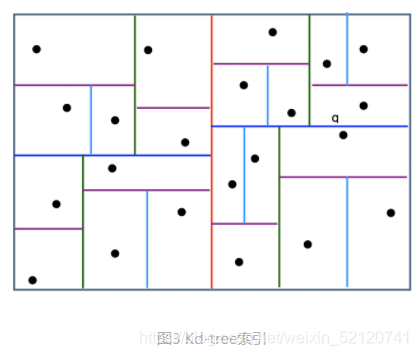
-
局部敏感哈希原理
让相邻的点落入同一个“桶”,这样在进行最近邻搜索时,我们仅需要在一个桶内,或相邻几个桶内的元素中进行搜索即可。如果保持每个桶中的元素个数在一个常数附近,我们就可以把最近邻搜索的时间复杂度降低到常数级别。
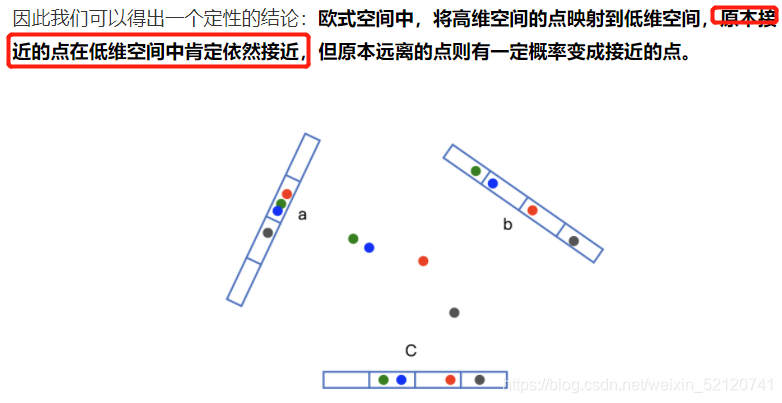
利用内积操作可以将 v 映射到一维空间,得到数值 h(v)=v⋅x。 
采用 m 个哈希函数同时进行分桶。如果两个点同时掉进了 m 个桶,那它们是相似点的概率将大大增加
-
多桶策略
具体应该如何处理不同桶之间的关系?



5、模型服务(模型部署到服务中)
-
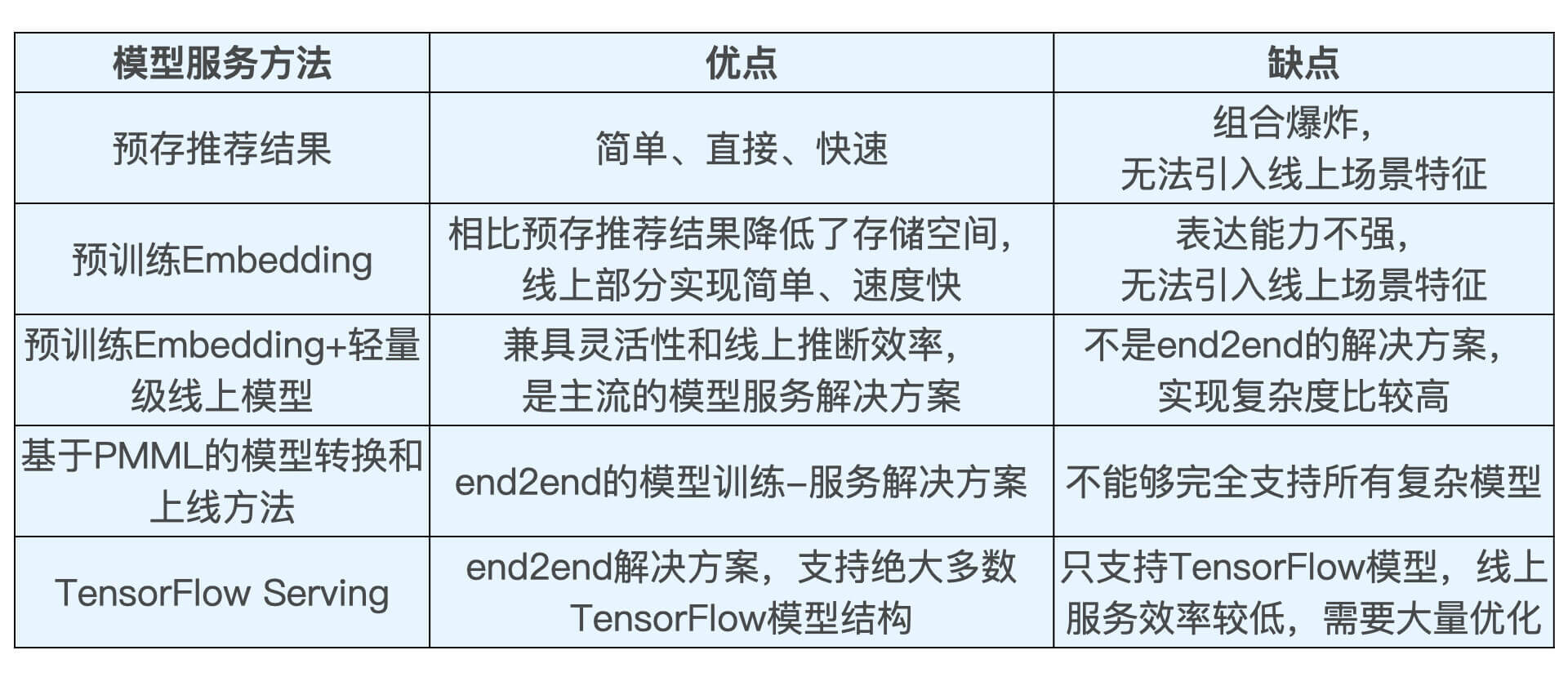
预存推荐结果或 Embedding 结果(无法支持线上场景特征的引入)
先离线训练好 Embedding,然后在线上通过相似度运算得到最终的推荐结果。

-
预训练 Embedding+ 轻量级线上模型(还是把模型割裂了)
用复杂深度学习网络离线训练生成 Embedding,存入内存数据库,再在线上实现逻辑回归或浅层神经网络等轻量级模型来拟合优化目标
-
利用 PMML(预测模型标记语言) 转换和部署模型(直接部署模型)
JPMML 在 Java Server 部分只进行推断,不考虑模型训练、分布式部署等一系列问题,因此 library 比较轻,能够高效地完成推断过程
-
TensorFlow Serving(DL)
PMML 语言的表示能力还是比较有限的,还不足以支持复杂的深度学习模型结构
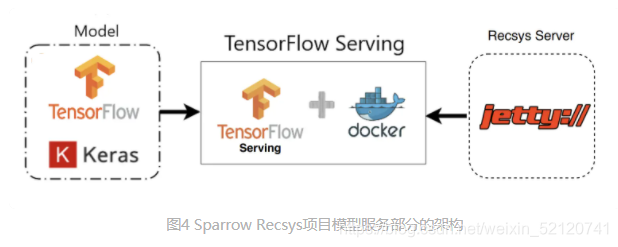
实战搭建 TensorFlow Serving 模型服务
Docker 是一个开源的应用容器引擎,你可以把它当作一个轻量级的虚拟机。它可以让开发者打包他们的应用以及依赖包到一个轻量级、可移植的容器中,然后发布到任何流行的操作系统。
1、安装Docker Desktop
2、# 从docker仓库中下载tensorflow/serving镜像
docker pull tensorflow/serving
3、# 把tensorflow/serving的测试代码clone到本地
git clone git://github.com/tensorflow/serving
4、# 启动TensorFlow Serving容器,在8501端口运行模型服务API
docker run -t --rm -p 8501:8501 -v "C:\Users\Think\serving\tensorflow_serving\servables\tensorflow\testdata\saved_model_half_plus_two_cpu:/models/half_plus_two" -e MODEL_NAME=half_plus_two tensorflow/serving '&'
在 Docker 的管理界面中看到了 TenSorflow Serving 容器,就证明 TensorFlow Serving 服务被你成功建立起来了。
5、# 请求模型服务API
curl -Uri 'http://localhost:8501/v1/models/half_plus_two:predict' -Body '{"instances":[1.0, 2.0, 5.0]}' -Method 'POST'
# 返回模型推断结果如下
# Returns => { "predictions": [2.5, 3.0, 4.5] }
6、相似电影推荐的结果和初步分析
方法一:人肉测试(SpotCheck)(是否符合自己的常识)
遇到推荐结果不合理的情况,我们需要做更多的调查研究,发掘这些结果出现的真实原因,才能找到改进方向。
方法二:指定 Ground truth(可以理解为标准答案)
指定一些比较权威的验证集
方法三:利用商业指标进行评估
可以跃过评估相似度这样一个过程,直接去评估它的终极商业指标。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









