






7.一些面试问题
1.为什么要做这个项目?
通过自研RPC框架,深入理解分布式系统的核心问题(如服务发现、负载均衡、容错机制),并掌握Netty、Zookeeper等组件的底层原理。
2.你说说Netty框架吧?
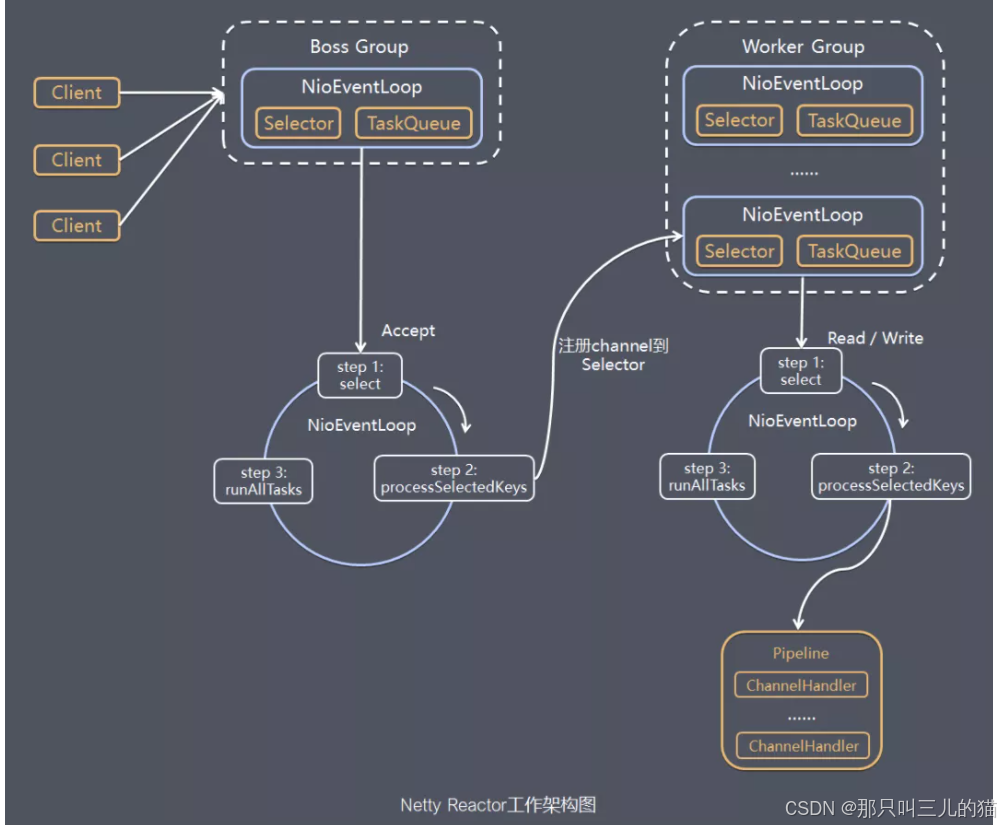
Netty是一个异步事件驱动的高性能网络框架,专为处理高并发、低延迟的场景设计(比如分布式系统、即时通讯)。它的核心架构采用主从多线程模型,简单来说就是:
抽象出来两个组:
BossGroup负责处理客户端的链接请求,建立好连接之后就把后续任务交给WokerGroup
WokerGroup,为每一个连接(channel)绑定一个线程,处理读写数据、业务逻辑,并且全程没有阻塞,避免线程空等
Channel与ChannelHandler,就像是工作上的流水线,可以灵活的添加handler处理器(编解码、加密、业务逻辑),按顺序处理数据包
2.你说说Zookeeper组件的底层原理
ZooKeeper 是一个分布式协调服务,核心是为分布式系统提供一致性数据管理(如配置中心、服务注册与发现)。
它的数据像文件夹一样组织成树形结构(叫ZNode),节点分两种——临时节点(服务下线自动删除)和持久节点(长期保存)。底层通过ZAB协议保证数据一致性:集群里有个主节点(Leader)负责处理写请求,先把操作日志同步给半数以上从节点(Follower),确认成功后才更新数据,确保所有节点最终一致;如果主节点挂了,会快速投票选新主,避免服务中断。客户端还能给节点设置监听(Watch),比如服务列表变化时,ZooKeeper 会主动通知,这样我们的RPC框架就能实时更新可用服务,不用一直轮询查状态,既省资源又高效。
ZAB协议面试问了在说
-
消息广播(写请求):
-
所有写请求由 Leader 处理,Leader 将操作转化为 Proposal(提案)广播给所有 Follower。
-
Follower 收到 Proposal 后先持久化到磁盘,再回复 ACK。
-
Leader 收到半数以上 ACK 后提交事务,通知 Follower 完成写入。
-
-
崩溃恢复(选主):
-
若 Leader 宕机,剩余节点通过投票选举新 Leader(优先选事务 ID 最大的节点)。
-
新 Leader 同步旧 Leader 未提交的 Proposal,确保数据一致。
-
3.rpc框架最核心的点是什么
1.使用netty实现高性能异步IO通信,并且通过自定写协议头解决了TCP的粘包问题。
2.使用Zookeeper作为注册中心,服务提供注册节点,消费者通过本地缓存+watcher监听试试感知服务状态滨化,选择可用节点
3.支持了java原始、fastjson、protobuf多种序列化方式,通过协议头动态选择
4.通过Guava-retry框架实现超时重传,并且通过jdk动态代理屏蔽网络细节,开发者只需要关注接口定义。
4.传输协议是自己写的吗,怎么考虑的
5.怎么实现自定义编解码的
在我的RPC框架中,自定义编解码通过动态选择序列化器实现,核心分为两步:
-
编码阶段:根据配置选择序列化器(如JSON或Java原生),将对象转为字节数组,并拼接协议头(解决粘包问题,告诉传输数据长度)。例如,JSON序列化会调用Fastjson的
toJSONBytes,并在协议头写入类型码1。 -
解码阶段:读取协议头中的类型码,动态选择对应的反序列化器。对于JSON数据,需根据
RpcRequest中的参数类型数组逐个转换参数,避免类型丢失问题。
java序列化:通过objectoutputstream和objectinputstream实现,缺点性能低,跨语言弱
fastjson
序列化:通过fastjson的tojsonbytes(任意对象转化为json格式字节数组)和parseobject(将字节数组反序列化为java对象)转化对象和json字节
Protobuf:调用生成的 toByteArray()(将消息对象转换为字节数组) 和 parseFrom() (字节数组转换回 Protobuf 定义的对象)方法

java序列化过程:

6.负载均衡采用了什么方案
1. 负载均衡策略类型
| 策略 | 实现逻辑 | 适用场景 |
|---|---|---|
| 随机(Random) | 从可用服务列表中随机选择一个节点,代码简单,适合节点性能相近的场景。 | 服务节点配置均衡,无显著性能差异。 |
| 轮询(Round Robin) | 按顺序依次选择节点,保证请求均匀分布(需维护全局索引,高并发时需原子操作)。 | 需要严格均匀分配请求,避免局部过热。 |
| 一致性哈希(Consistent Hash) | 对请求参数(如用户ID)哈希计算,固定映射到某个节点,保证相同请求总落到同一节点。 | 需要会话保持或本地缓存的场景(如缓存命中)。 |
2. 实现步骤(结合项目代码)
(1) 服务发现与列表维护
-
Zookeeper 监听:消费者启动时从 Zookeeper 拉取服务提供者的临时节点列表(如
/services/order-service),并注册 Watcher 监听子节点变化。 -
本地缓存:服务列表缓存在客户端内存中,避免每次调用都访问 Zookeeper(减少网络开销)。
JAVA// 伪代码:从Zookeeper获取服务列表并监听
List<String> providers = zk.getChildren("/services/order-service", watchedEvent -> {
if (event.type == NodeChildrenChanged) {
// 子节点变化时更新本地缓存
providers = zk.getChildren(event.getPath(), true);
}
});
(2) 策略选择与路由
-
策略接口抽象:定义
LoadBalance接口,不同策略实现select方法。
JAVApublic interface LoadBalance {
String select(List<String> providers, RpcRequest request);
}
-
随机策略实现:
JAVApublic class RandomLoadBalance implements LoadBalance {
@Override
public String select(List<String> providers, RpcRequest request) {
int index = ThreadLocalRandom.current().nextInt(providers.size());
return providers.get(index);
}
}
-
一致性哈希策略实现:
JAVApublic class ConsistentHashLoadBalance implements LoadBalance {
private final int replicaCount; // 虚拟节点数
private final TreeMap<Integer, String> virtualNodes = new TreeMap<>();
public ConsistentHashLoadBalance(List<String> providers, int replicaCount) {
this.replicaCount = replicaCount;
for (String provider : providers) {
for (int i = 0; i < replicaCount; i++) {
String virtualNode = provider + "#" + i;
int hash = hash(virtualNode);
virtualNodes.put(hash, provider);
}
}
}
@Override
public String select(List<String> providers, RpcRequest request) {
int keyHash = hash(request.getUserId()); // 假设按用户ID哈希
SortedMap<Integer, String> tailMap = virtualNodes.tailMap(keyHash);
int targetHash = tailMap.isEmpty() ? virtualNodes.firstKey() : tailMap.firstKey();
return virtualNodes.get(targetHash);
}
private int hash(String key) {
// 使用FNV1_32_HASH算法
// ... 具体实现省略 ...
}
}
(3) 负载均衡与RPC调用整合
消费者在发起调用前,通过负载均衡器选择目标地址,再通过 Netty 发送请求:
“项目中负载均衡在客户端实现,支持随机、轮询、一致性哈希等策略。服务列表通过Zookeeper动态维护,消费者根据配置的策略选择目标节点。例如一致性哈希策略,通过对请求参数哈希计算,结合虚拟节点确保请求均匀分布,适用于需要会话保持的场景。整个过程通过策略模式解耦,未来可无缝扩展新的均衡算法
回答:“项目中负载均衡在客户端实现,支持随机、轮询、一致性哈希等策略。服务列表通过Zookeeper动态维护,消费者根据配置的策略选择目标节点。例如一致性哈希策略,通过对请求参数哈希计算,结合虚拟节点确保请求均匀分布,适用于需要会话保持的场景。整个过程通过策略模式解耦,未来可无缝扩展新的均衡算法。”
7.给你优化的话你会从哪个点入手
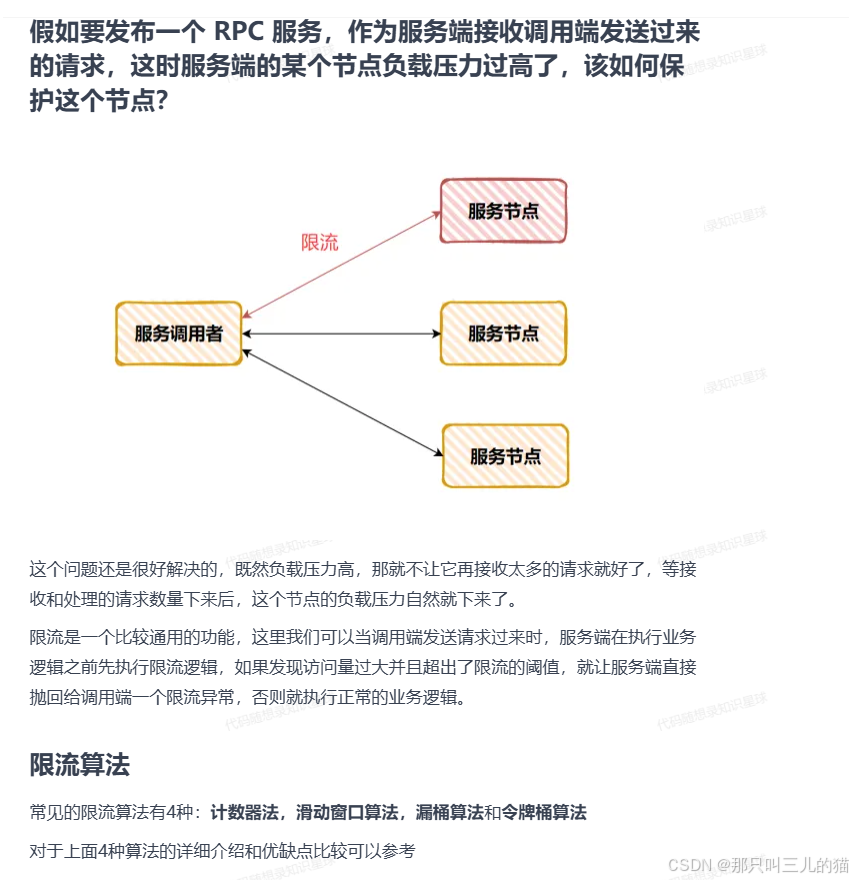
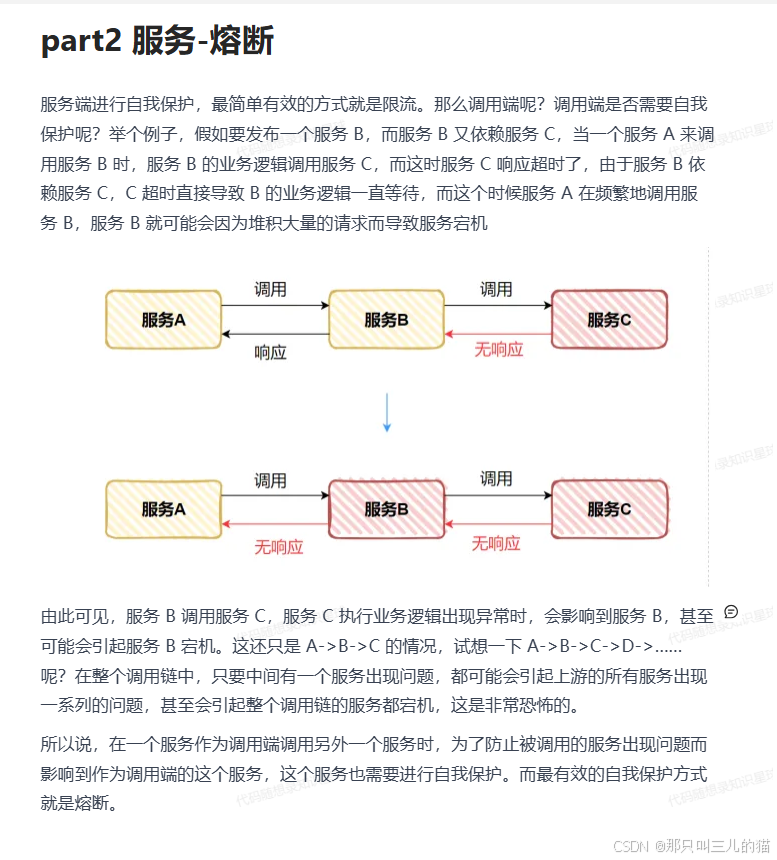
从上面两个进行回答
8.Channel复用如何实现?如何管理Channel生命周期?
答:
-
复用机制:客户端通过维护一个Channel池(如ConcurrentHashMap),对同一服务提供者复用已建立的Channel,避免每次调用创建新连接。
-
生命周期管理:通过心跳机制(IdleStateHandler)检测Channel活性,定期清理无效连接。当Zookeeper服务节点变更时,关闭对应Channel并重建。
9.如何实现白名单这个功能?
// 创建Retryer实例,配置超时、重试次数、退避策略
Retryer<Boolean> retryer = RetryerBuilder.<Boolean>newBuilder()
.retryIfExceptionOfType(TimeoutException.class) // 仅重试超时异常
.withStopStrategy(StopStrategies.stopAfterAttempt(3)) // 最大重试3次(含首次调用)
.withWaitStrategy(WaitStrategies.exponentialWait(100, 5 * 1000, TimeUnit.MILLISECONDS)) // 指数退避
.withRetryListener(new RetryListener() { // 监听重试事件
@Override
public <V> void onRetry(Attempt<V> attempt) {
log.warn("Retry attempt {}, delay={}ms",
attempt.getAttemptNumber(),
attempt.getDelaySinceFirstAttempt());
}
})
.build();
根据路径不同在注册时候会标记retry节点


















 3682
3682

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









