







文章目录
-
数据集:2 维数据集—Countries,可以用平面图清晰的展示聚类效果。该数据集含有 68 个国家和地区的出生率(%)与死亡率(%)。
-
实验目的:通过对该数据集进行分析,发现不同国家与地区的出生率与死亡率,并根据比较进行公共卫生的预测与防御。
-
本实验利用密度聚类、层次聚类和期望最大化聚类对上述数据集进行聚类分析,并将三种聚类方法进行简单的比较。
1.对数据集进行加载、预处理集可视化
1.1 加载数据集
setwd("存放数据集的路径")
countries<-read.csv("countries.csv") #读取数据集
1.2 数据预处理
dim(countries)
head(countries)
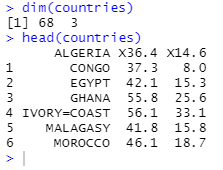
从 head()结果图中可以发现该数据集没有列名,且行所对应的是数字,不是相应国家。
下面我们要对行列名进行修改:
names(countries)<-c("country","birth","death") #设置三个变量名字
var<-countries$country #取变量 country 的值赋值给 var
var<-as.character(var) #将赋值的变为字符型
head(var)
for(i in 1:68) row.names(countries)[i]=var[i]#将数据集 countries 的行名命名为响应国家名
head(countries)
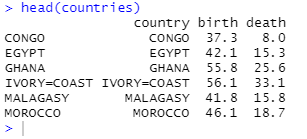
1.3 将样本点进行可视化
plot(countries$birth,countries$death) #画出所有 68 个样本点
c<-which(countries$country=="聚类点1")
d<-which(countries$country=="聚类点2")
e<-which(countries$country=="聚类点3")
f<-which(countries$country=="聚类点4")
g<-which(countries$country=="聚类点5")
h<-which(countries$country=="聚类点6")
m<-which.max(countries$birth) #获取出生率最高的点在数据集中的位置
points(countries[c(c,d,e,f,g,h,m),-1],pch=16)#以实心圆点标出如上样本点
legend(countries$birth[c],countries$death[c],"天狼星区",bty="n",xjust=0.5,cex=0.8)
#标出天狼星区样本点的图例
legend(countries$birth[d],countries$death[d],"参宿七星区",bty="n",xjust=0.5,cex=0.8)
legend(countries$birth[e],countries$death[e],"蓝移星区" 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









