






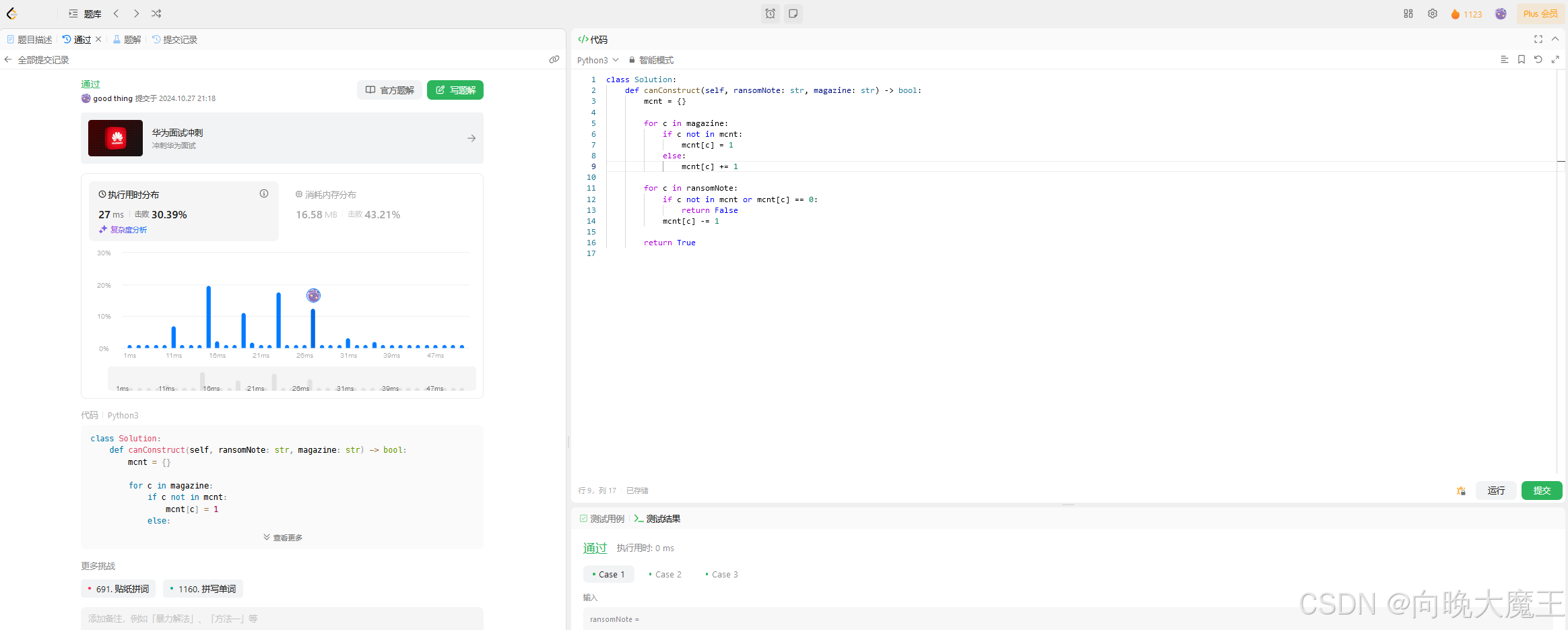
任务一
完成Leetcode 383, 笔记中提交代码与leetcode提交通过截图
任务二
下面是一段调用书生浦语API实现将非结构化文本转化成结构化json的例子,其中有一个小bug会导致报错。请大家自行通过debug功能定位到报错原因。
from openai import OpenAI
import json
def internlm_gen(prompt,client):
'''
LLM生成函数
Param prompt: prompt string
Param client: OpenAI client
'''
response = client.chat.completions.create(
model="internlm2.5-latest",
messages=[
{"role": "user", "content": prompt},
],
stream=False
)
return response.choices[0].message.content
api_key = ''
client = OpenAI(base_url="https://internlm-chat.intern-ai.org.cn/puyu/api/v1/",api_key=api_key)
content = """
书生浦语InternLM2.5是上海人工智能实验室于2024年7月推出的新一代大语言模型,提供1.8B、7B和20B三种参数版本,以适应不同需求。
该模型在复杂场景下的推理能力得到全面增强,支持1M超长上下文,能自主进行互联网搜索并整合信息。
"""
prompt = f"""
请帮我由以下``内的这段模型介绍文字中提取关于该模型的信息,要求包含模型名字、开发机构、提供参数版本、上下文长度四个内容,以json格式返回。
`{content}`
"""
res = internlm_gen(prompt,client)
res_json = json.loads(res)
print(res_json)
launch.json配置内容:
{
"version": "0.2.0",
"configurations": [
{
"name": "Python: Current File",
"type": "debugpy",
"request": "launch",
"program": "${file}",
"console": "integratedTerminal",
"justMyCode": false
},
]
}
在VSCode中启动调试
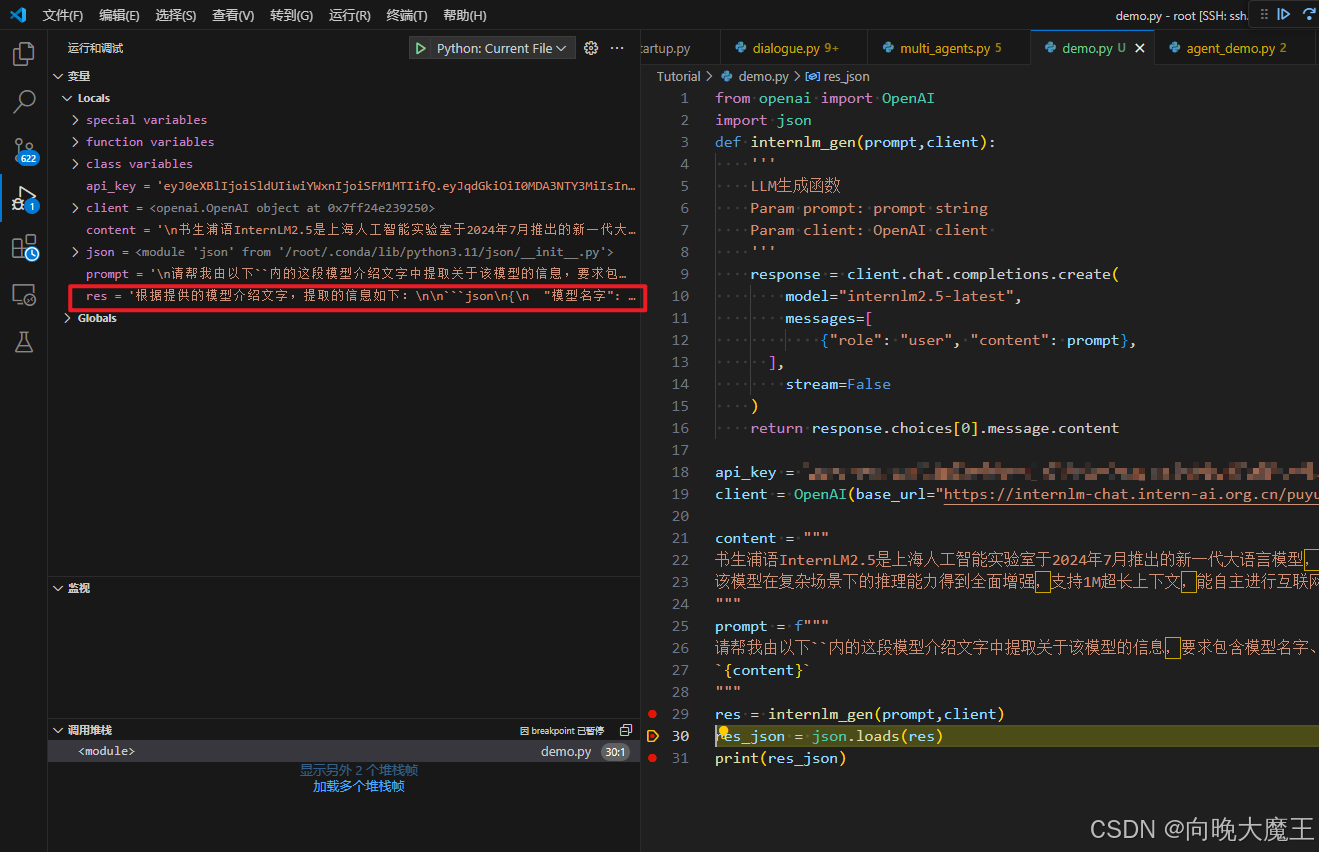 可以看到res的值为:
可以看到res的值为:'根据提供的模型介绍文字,提取的信息如下:\n\n```json\n{\n "模型名字": "书生浦语InternLM2.5",\n "开发机构": "上海人工智能实验室",\n "提供参数版本": ["1.8B", "7B", "20B"],\n "上下文长度": "1M"\n}\n```'
接下来的步骤会报错:
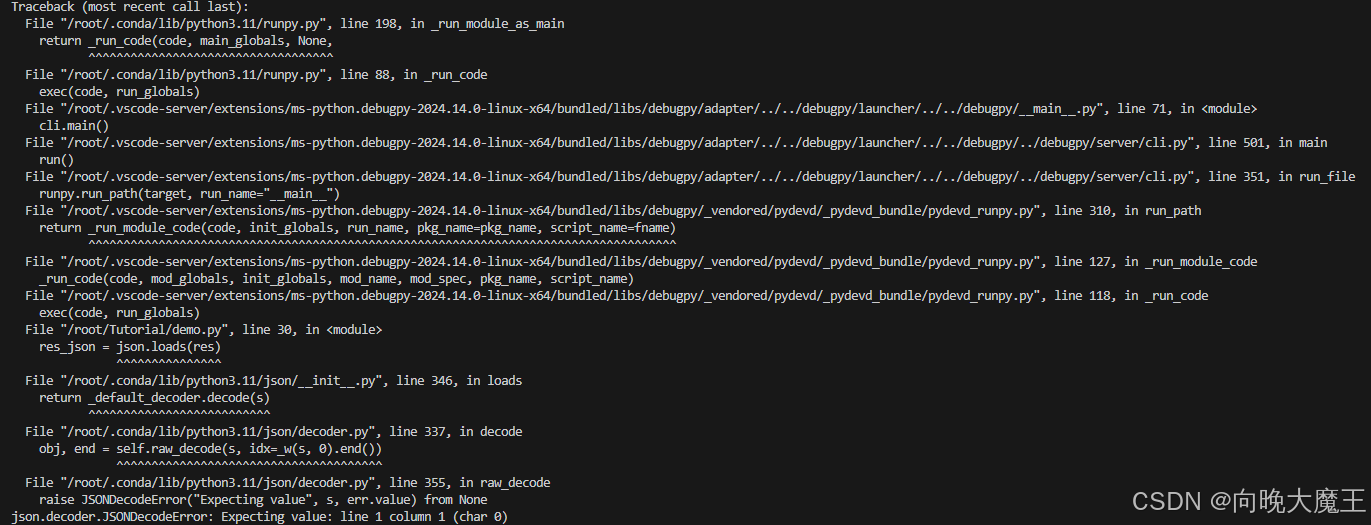
这是因为返回的res值有根据提供的模型介绍文字等无关内容,并且以代码块格式返回,无法解析为纯json格式
对程序进行适当修改,提示词修改为:
prompt = f"""
请帮我由以下``内的这段模型介绍文字中提取关于该模型的信息,要求包含模型名字、开发机构、提供参数版本、上下文长度四个内容,以标准json格式返回,不要包括无关信息。
`{content}`
"""
并且添加对输出预处理的语句:
clean_response = re.sub(r'```json\n|\n```', '', res)
再次运行:
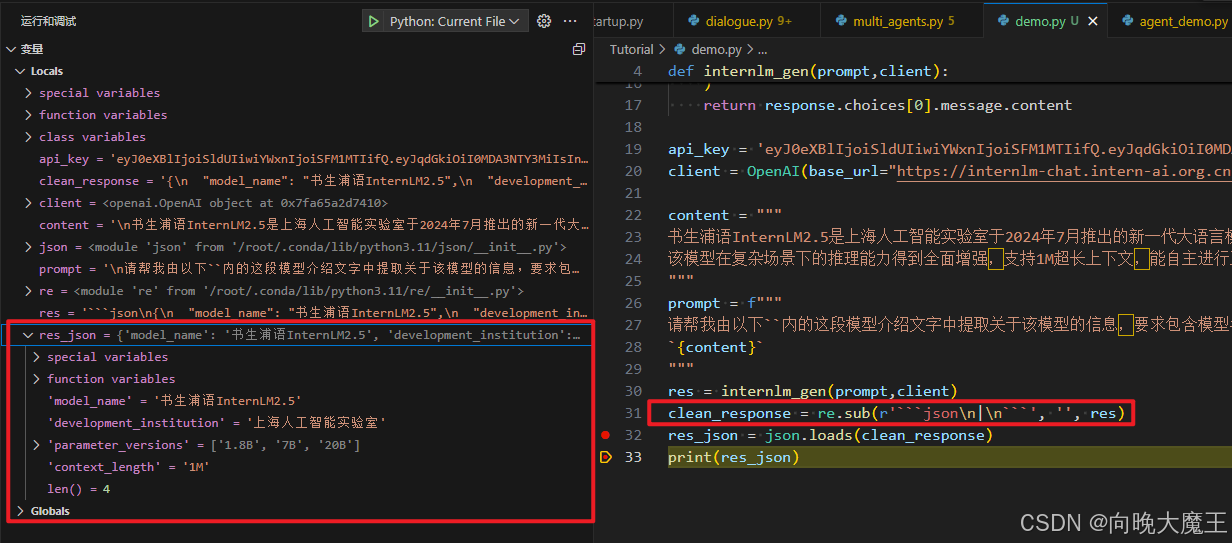 可以看到这次得到了正确的json返回值
可以看到这次得到了正确的json返回值
任务三
使用VScode连接开发机后使用pip install -t命令安装一个numpy到开发机/root/myenvs目录下,并成功在一个新建的python文件中引用
执行命令:
pip install -t /root/myenvs numpy

可以看到/root/myenvs目录下存在numpy相关包:
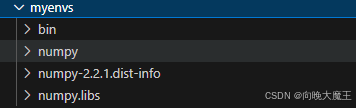
在一个新建的python文件中引用:
import sys
sys.path.append('/root/myenvs')
import numpy as np
data=np.array([[1,2,3,4],[4,5,6,7]])
print(data)
运行结果:



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









