







数据库相关概念
数据库(DB)
数据库是指存放在计算机存储器中,按照一定格式编成的相互关联的各种数据的集合,供用户迅速有效地进行数据处理。它是存储数据的容器,也被称为数据存储库(Data Store),能够存储大量结构化和非结构化的数据,包括文本、数字、图像、音频等各种类型的数据。
数据库管理系统(DBMS)
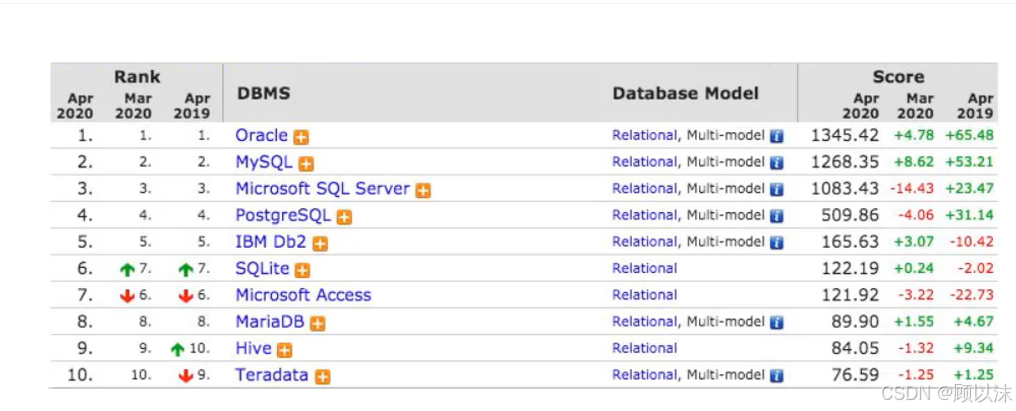
常见的数据库管理系统
SQL(结构化查询语言)
SQL(Structured Query Language,结构化查询语言)是用于管理和操作关系型数据库的标准编程语言。它允许用户以声明性的方式定义、操作和控制数据。
MySQL数据库(MySQL数据库管理系统)
MySQL的数据模型
SQL
-
语句结构:SQL语句可以单行或多行书写,以分号(;)结尾。
-
可读性:SQL语句可以使用空格或缩进来增强可读性。
-
大小写:MySQL数据库的SQL语句不区分大小写,但关键字通常建议使用大写,以提高可读性。
-
注释:
- 单行注释:使用双连字符(--)或井号(#,MySQL特有)后跟注释内容。
- 多行注释:使用/* */包围注释内容。
SQL语句分类
SQL语句主要分为以下几类:
-
DDL(Data Definition Language,数据定义语言):用于定义数据库对象,如表、索引、视图等。
- CREATE:创建数据库或数据库对象。
- ALTER:修改数据库对象。
- DROP:删除数据库对象。
- TRUNCATE:删除表中的所有数据,但保留表结构。
- COMMENT:添加注释。
- RENAME:重命名数据库对象。
-
DML(Data Manipulation Language,数据操作语言):用于对数据库中的数据进行增删改操作。
- SELECT:查询数据。
- INSERT:插入数据。
- UPDATE:更新数据。
- DELETE:删除数据。
- LOCK:控制表并发情况。
- CALL:调用PL/SQL或JAVA子程序。
-
DQL(Data Query Language,数据查询语言):主要用于查询数据库中的数据,实际上是DML的一个子集,但通常单独列出以强调其重要性。
- 基本查询:使用SELECT语句从表中检索数据。
- 条件查询:使用WHERE子句对查询结果进行过滤。
- 聚合查询:使用聚合函数(如SUM、AVG、MAX、MIN、COUNT)对查询结果进行汇总。
- 分组查询:使用GROUP BY子句对查询结果进行分组。
- 排序查询:使用ORDER BY子句对查询结果进行排序。
- 分页查询:使用LIMIT子句对查询结果进行分页。
-
DCL(Data Control Language,数据控制语言):用于设置或更改数据库用户或角色的访问权限。
- GRANT:授予用户访问数据库的权限。
- REVOKE:撤销用户访问数据库的权限。
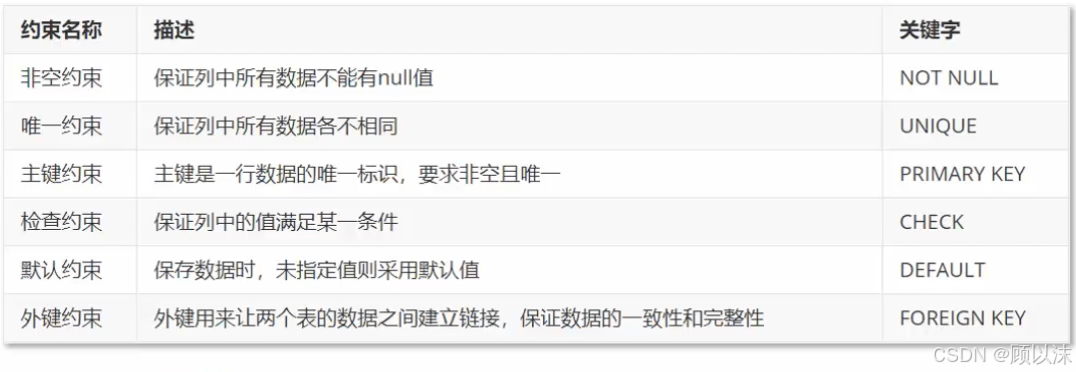
约束
概念和分类
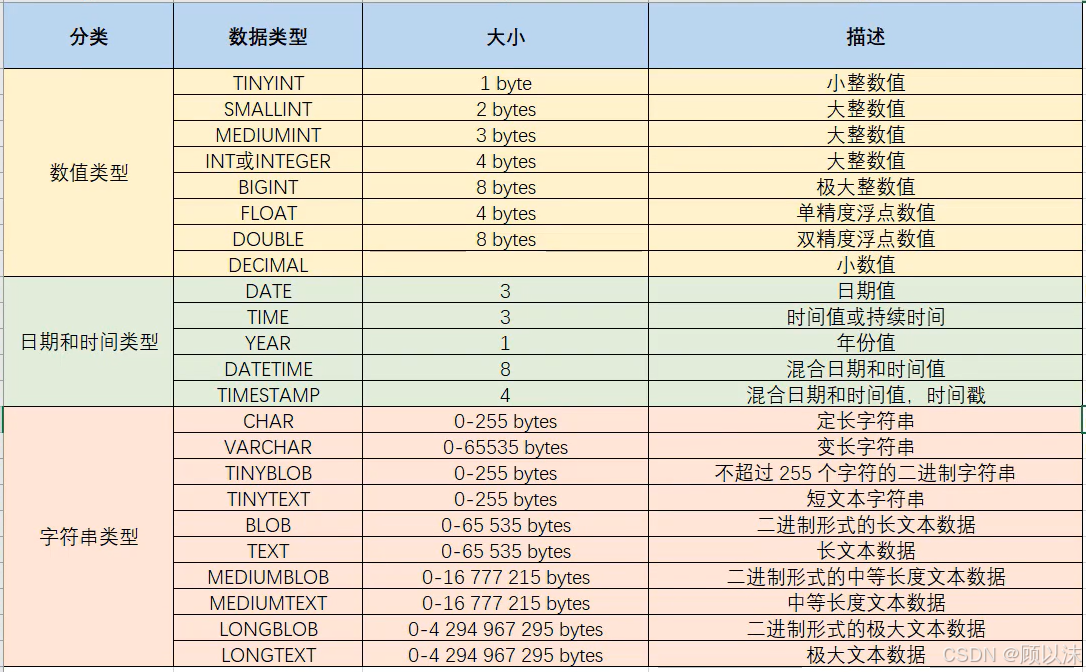
数据库约束(Constraints)是数据库管理系统(DBMS)用来限制存储在表中的数据类型的规则。它们确保了数据的准确性和一致性,防止无效数据被插入到表中。
1. 主键约束(Primary Key Constraint)
- 概念:主键约束唯一标识表中的每一行。主键列的值必须是唯一的且不能包含NULL值。
- 分类:单一主键和复合主键(由多列组成的主键)。
- 用途:确保表中每行数据的唯一性。
2. 外键约束(Foreign Key Constraint)
- 概念:外键约束用于在两个表之间建立连接,确保一个表中的值在另一个表中存在(即引用完整性)。
- 分类:简单外键和复合外键(由多列组成的外键)。
- 用途:维护表之间的引用完整性,防止孤立记录。
3. 唯一约束(Unique Constraint)
- 概念:唯一约束确保一列中的所有值都是唯一的。与主键约束不同,唯一约束允许NULL值(但多个NULL值不被视为重复)。
- 分类:单一唯一约束和复合唯一约束(由多列组成的唯一约束)。
- 用途:确保特定列(或列组合)中的值唯一,但不要求该列作为主键。
4. 检查约束(Check Constraint)
- 概念:检查约束用于确保列中的数据满足特定条件(例如,年龄必须在0到120之间)。
- 分类:基于表达式的约束。
- 用途:确保数据符合特定的业务规则或条件。
5. 非空约束(Not Null Constraint)
- 概念:非空约束确保列中不能存储NULL值。
- 分类:列级约束。
- 用途:确保某些关键信息必须被提供,防止数据缺失。
6. 默认约束(Default Constraint)
- 概念:默认约束为列提供默认值,如果在插入数据时未提供该列的值,则使用默认值。
- 分类:列级约束。
- 用途:为某些列提供合理的默认值,简化数据插入过程。
7. 自动递增约束(Auto Increment Constraint)
- 概念:自动递增约束用于生成唯一的数值,通常用于主键列。每次插入新行时,该列的值会自动增加。
- 分类:列级约束(特定于某些数据库系统,如MySQL)。
- 用途:自动生成唯一标识符,简化主键管理。
8. 触发器约束(Triggers, 虽然不是严格的约束,但具有类似功能)
- 概念:触发器是数据库中的特定事件(如INSERT、UPDATE、DELETE)发生时自动执行的代码块。
- 分类:INSERT触发器、UPDATE触发器、DELETE触发器。
- 用途:强制复杂的业务规则,维护数据一致性,记录数据变更历史等。
MySQL不支持检查约束 !
数据库设计
多表查询
多表查询,也称为关联查询,是指两个或更多个表一起完成查询操作。多表查询指的是同时从多张数据表中取出数据并且显示的一种操作。这种查询方式通常用于获取跨表的数据信息,例如,查询员工信息时需要同时获取员工所属的部门信息,这时就需要对员工表和部门表进行多表查询。
多表查询的类型
-
内连接(INNER JOIN):
- 内连接返回两个表中满足关联条件的数据。
- 如果两个表中没有满足条件的数据,则不会出现在结果集中。
-
左连接(LEFT JOIN 或 LEFT OUTER JOIN):
- 左连接返回左表中的所有数据以及右表中满足关联条件的数据。
- 如果右表中没有满足条件的数据,则结果集中的对应字段为NULL。
-
右连接(RIGHT JOIN 或 RIGHT OUTER JOIN):
- 右连接返回右表中的所有数据以及左表中满足关联条件的数据。
- 如果左表中没有满足条件的数据,则结果集中的对应字段为NULL。
-
满外连接(FULL OUTER JOIN):
- 满外连接返回两个表中所有的数据,以及满足关联条件的数据。
- 如果两个表中没有满足条件的数据,则结果集中的对应字段为NULL。
- 需要注意的是,MySQL不支持FULL JOIN,但可以使用LEFT JOIN UNION RIGHT JOIN代替。
-
交叉连接(CROSS JOIN):
- 交叉连接返回两个表的笛卡尔积,即两个表的记录数相乘的结果。
- 交叉连接通常不使用WHERE子句进行过滤,因为它会返回所有可能的组合。
-
自然连接(NATURAL JOIN):
- 自然连接是SQL99提供的一种特殊语法,用于表示两个表中所有相同的字段进行等值连接。
- 它会自动查找两个连接表中所有相同的字段,并进行等值连接。
-
使用USING的连接:
- SQL99还支持使用USING指定数据表里的同名字段进行等值连接。但是只能配合JOIN一起使用。
多表查询的示例
假设有两个表:员工表(emp)和部门表(dept)。员工表包含员工的编号、姓名、职位、基本工资和部门编号等信息;部门表包含部门编号、部门名称和部门位置等信息。
- 查询每个雇员的编号、姓名、职位、基本工资、部门名称、部门位置:
SELECT e.empno, e.ename, e.job, e.sal, d.deptno, d.dname, d.loc
FROM emp e
INNER JOIN dept d ON e.deptno = d.deptno;- 查询每个雇员的编号、姓名、职位、基本工资、工资等级:
SELECT e.empno, e.ename, e.job, e.sal, s.grade
FROM emp e
INNER JOIN salgrade s ON e.sal BETWEEN s.losal AND s.hisal;- 查询每个雇员的编号、姓名、职位、领导姓名、领导职位(自连接):
SELECT e1.empno, e1.ename, e1.job, e2.ename AS mgr_name, e2.job AS mgr_job
FROM emp e1
LEFT JOIN emp e2 ON e1.mgr = e2.empno;- 左连接查询(查询所有雇员信息及其对应的部门信息,如果没有对应部门信息则显示为NULL):
SELECT e.empno, e.ename, d.dname
FROM emp e
LEFT JOIN dept d ON e.deptno = d.deptno;- 右连接查询(查询所有部门信息及其对应的雇员信息,如果没有对应雇员信息则显示为NULL):
SELECT e.empno, e.ename, d.dname
FROM emp e
RIGHT JOIN dept d ON e.deptno = d.deptno;- 满外连接查询(MySQL不支持FULL JOIN,使用LEFT JOIN UNION RIGHT JOIN代替):
SELECT e.empno, e.ename, d.dname
FROM emp e
LEFT JOIN dept d ON e.deptno = d.deptno
UNION
SELECT e.empno, e.ename, d.dname
FROM emp e
RIGHT JOIN dept d ON e.deptno = d.deptno;事务
数据库事务是数据库管理系统执行过程中的一个逻辑单位,它由一组有限的数据库操作序列构成,这些操作要么全部执行成功,要么全部不执行,以保证数据的一致性和完整性。
事务是数据库操作的最小工作单元,是作为单个逻辑工作单元执行的一系列操作。这些操作作为一个整体一起向系统提交,具有不可分割性。如果事务中的任何一个操作失败,那么整个事务将被回滚,即所有操作都会被撤销,数据库恢复到事务开始之前的状态。
事务具有四个基本特性,通常被称为ACID特性:
- 原子性(Atomicity):
- 事务是一个不可分割的工作单位,事务中的操作要么全部完成,要么全部不完成。
- 原子性是通过数据库的Undo和Redo机制来实现的。Undo是在事务执行过程中,如果出现错误或用户执行ROLLBACK语句时,系统可以回滚到事务开始前的状态。Redo是在事务提交后,系统出现故障时,可以根据日志文件重新执行这些事务。
- 一致性(Consistency):
- 事务必须将数据库从一种一致状态转换到另一种一致状态。
- 一致性包括数据库的内部一致性和应用层面的一致性。内部一致性要求数据库中的数据必须满足所有的完整性约束;应用层面的一致性要求事务的执行结果必须符合业务规则。
- 一致性是通过数据库的约束机制(如主键约束、外键约束等)以及应用程序的业务逻辑来实现的。
- 隔离性(Isolation):
- 并发执行的事务之间相互隔离,不允许一个事务的执行结果影响其他事务的执行。
- 隔离性是并发控制的核心,它避免了多个事务并发执行时可能出现的数据不一致问题。
- 数据库系统通常通过锁和其他并发控制技术来实现隔离性。
- 持久性(Durability):
- 一旦事务提交,它对数据库中数据的改变就是永久性的,即使在系统崩溃后,事务的修改结果也不会丢失。
- 持久性是通过数据库的Redo机制和日志管理系统来实现的。当事务提交后,系统将把事务的所有操作写入到日志文件中,以便在系统恢复后重新执行这些操作,保证数据的一致性。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









