






看了网上相关的ChatTTS用固定音色生成语音,基本都没跑通。
跑去官网看了一下,有参考案例:
import torch
import torchaudio
import os
from uvicorn import run
import time
from fastapi import FastAPI, HTTPException, Response, File, UploadFile
from pydantic import BaseModel
from fastapi.responses import StreamingResponse
import requests
import ChatTTS
from urllib.parse import quote
chat = ChatTTS.Chat()
chat.load(source='local',
custom_path='/your_model_path/2Noise/ChatTTS/',
device='cuda',
compile=False)
# 检查音色文件是否存在,存在,直接加载保存的音色文件,不存在就随机选一个保存(多试几次,选个喜欢的)
file_path = '/your_path_to_save/speaker/girl4.pth'
if not os.path.exists(file_path):
rand_spk = chat.sample_random_speaker()
# torch.save(rand_spk, '/your_path_to_save/speaker/girl4.pth')
# rand_spk = torch.load('/your_path_to_save/speaker/girl4.pth')
torch.save(rand_spk, '/your_path_to_save/speaker/girl4.pth')
else:
rand_spk = torch.load(file_path)
print(rand_spk) # save it for later timbre recovery
params_infer_code = ChatTTS.Chat.InferCodeParams(
spk_emb = rand_spk,
temperature = .3,
top_P = 0.7,
top_K = 20,
)
params_refine_text = ChatTTS.Chat.RefineTextParams(
prompt='[oral_2][laugh_0][break_6]',
)
text = '这是一个推理示例,生成一个语音'
wavs = chat.infer(text,
skip_refine_text=True,
params_refine_text=params_refine_text,
params_infer_code=params_infer_code)
try:
torchaudio.save("word_level_output.wav", torch.from_numpy(wavs[0]).unsqueeze(0), 24000)
except:
torchaudio.save("word_level_output.wav", torch.from_numpy(wavs[0]), 24000)注意:我按照官网这个用下来,声音还是有变化的呀????声音还是没有固定
在ChatTTS的官网上看到有个类似的issue,作者的回复是这样的,看来是模型本身的问题,只能等官网后续优化了: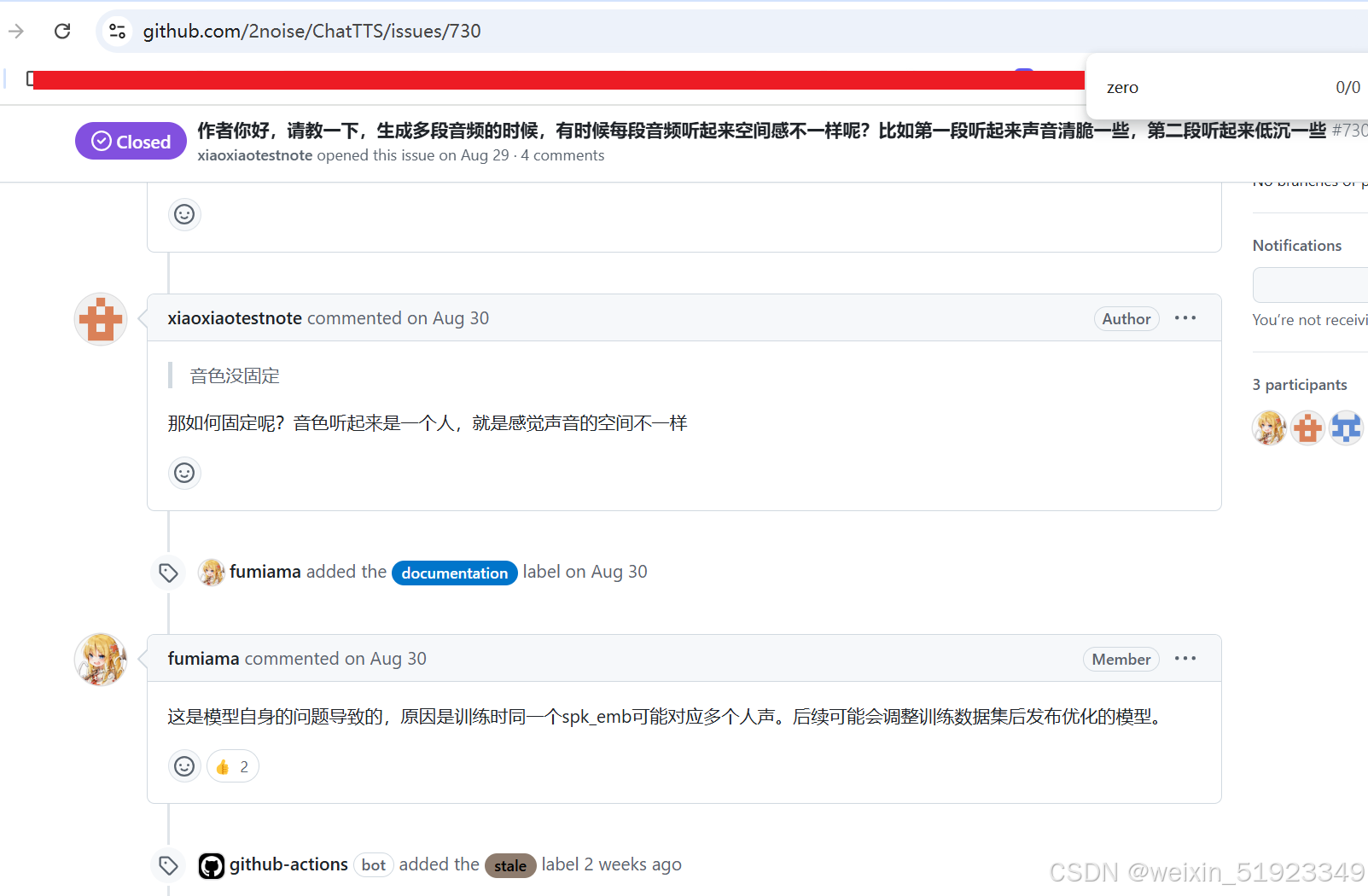
参考
模型权重文件 来自:https://huggingface.co/2Noise/ChatTTS
chatTTS官网:https://github.com/2noise/ChatTTS

















 2679
2679

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









