







Hadoop简介
Hadoop是一个由Apache基金会所开发的大数据开发框架,是一个允许使用简单编程模型跨计算机集群分布式处理大型数据集的系统。基于Java语言开发的,具有很好的跨平台特性。Hadoop可以部署在廉价的计算机集群中。每台机器都提供本地计算和存储,本身不是依靠硬件来提供高可靠性,它的可靠是建立在应用层而不是依靠高性能的硬件设备。使用Hadoop可以方便地管理地分布式集群,将海量数据分布式地存储在集群中,并使用分布式并行程序来处理这些数据。它被设计成从单个服务器扩展到数前台计算机,每台计算机都提供本地计算和存储。基于Java语言开发的,具有很好的跨平台特性。
简单概括来说,Hadoop是一个为了开发可靠、可扩展、分布式计算的开源软件。
Hadoop的特性
1.高可靠性:Hadoop底层维护多个数据副本,所以即使Hadoop某个计算元素或存储出现故障,也不会导致数据的丢失。即使一个副本发生故障,其他副本也可以保证正确对外提供服务。
2.高扩展性:Hadoop的设计目标是可以高效稳定地运行在廉价的计算机集群上,可以扩展到数以千计的计算机节点上。
3.高效性:作为并行分布式计算平台,Hadoop采用分布式存储和分布式处理两大核心技术,能够高效地处理PB级数据。
4.高容错性:采用冗余数据存储方式,自动保存数据的多个副本,并且能够自动将失败的任务重新分配。
5.成本低:Hadoop采用廉价的计算机集群,成本比较低,普通用户也很容易用自己 PC搭建Hadoop运行环境。
6.运行在Linux操作系统上:Hadoop是基于JAVA开发的,可以较好地运行在Linux操作系统上。
7.支持多种编程语言:Hadoop上的应用程序也可以使用其他语言编写,如C++。
Hadoop架构

Hadoop1.0的主要核心组成是Mapreduce和HDFS。Mapreduce不仅负责数据的计算,而且负责集群作业调度和资源(内存、CPU)管理。HDFS负责数据的存储
Hadoop2.0在原来的基础上引入了新的框架YARN。YARN负责集群资源管理和统一调度,而Mapreduce功能变得单一,运行于YARN之上,只负责进行数据的计算。由于YARN具有通用性,因此YARN也可以作为其他计算框架(如:Spark,Storm等)的资源管理系统,不仅限于Mapreduce。
Hadoop3.0在组成上没有变化。
Hadoop 运行模式
Hadoop 运行模式包括:本地模式、伪分布式模式以及完全分布式模式。
本地模式:也叫单机模式,单机运行。没有分布式文件系统,直接在本地操作系统的文件系统读/写,不需要加载任何Hadoop的守护进程。用于本地 MapReduce 程序的调试。
伪分布式模式:也是单机运行,但是具备 Hadoop 集群的所有功能,一台服务器模拟一个分布式的环境。
完全分布式模式:多台服务器组成分布式环境。生产环境使用。
Hadoop生态圈
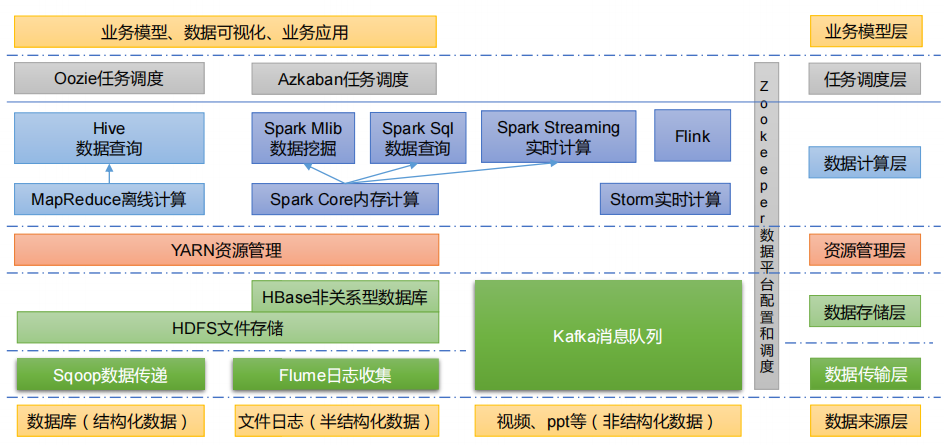
1.Sqoop:Sqoop 是一款开源的工具,主要用于在 Hadoop、Hive 与传统的数据库(MySQL)
间进行数据的传递,可以将一个关系型数据库(例如 :MySQL,Oracle 等)中的数据导进
到 Hadoop 的 HDFS 中,也可以将 HDFS 的数据导进到关系型数据库中。
2.Flume:Flume 是一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,
Flume 支持在日志系统中定制各类数据发送方,用于收集数据。
3.Kafka:Kafka 是一种高吞吐量的分布式发布订阅消息系统。
4.Spark:Spark 是当前最流行的开源大数据内存计算框架。可以基于 Hadoop 上存储的大数据进行计算。
5.Flink:Flink 是当前最流行的开源大数据内存计算框架。用于实时计算的场景较多。
6.Oozie:Oozie 是一个管理 Hadoop 作业(job)的工作流程调度管理系统。
7.Hbase:HBase 是一个分布式的、面向列的开源数据库。HBase 不同于一般的关系数据库,
它是一个适合于非结构化数据存储的数据库。
8.Hive:Hive 是基于 Hadoop 的一个数据仓库工具,可以将结构化的数据文件映射为一张
数据库表,并提供简单的 SQL 查询功能,可以将 SQL 语句转换为 MapReduce 任务进行运行。其优点是学习成本低,可以通过类 SQL 语句快速实现简单的 MapReduce 统计,不必开发专门的 MapReduce 应用,十分适合数据仓库的统计分析。
9.ZooKeeper:它是一个针对大型分布式系统的可靠协调系统,提供的功能包括:配置维护、
名字服务、分布式同步、组服务等。

















 931
931

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









