







 本文记录了在虚拟机中安装Hadoop集群时遇到的两个主要问题:1) 运行Hadoop命令时的路径与环境变量错误;2) 启动Hadoop集群过程中namenode、datanode等组件的问题。解决方案包括正确配置环境变量,理解mkdir命令的-p选项,以及检查和关闭datanode的安全模式。
本文记录了在虚拟机中安装Hadoop集群时遇到的两个主要问题:1) 运行Hadoop命令时的路径与环境变量错误;2) 启动Hadoop集群过程中namenode、datanode等组件的问题。解决方案包括正确配置环境变量,理解mkdir命令的-p选项,以及检查和关闭datanode的安全模式。
使用虚拟机时遇到的问题
1)

bash: cd: /etc/hadoop/: 没有那个文件或目录
这是我在运行hadoop伪分布式实例时遇到的一个问题,当时是想进入 /etc/hadoop/这个目录下,可是出错了,但是其实是有这个文件目录的。
其实这个错误很简单,是因为 cd后加个/ 相当于在根目录下查找,这时候得输入完整路径cd /usr/local/hadoop/etc/hadoop,或者在**/usr/local/hadoop/**的目录下输入 cd etc/hadoop也可以。

2)
最开始开启hadoop时不知道一定要在前面加./sbin/ 所以在运行start-all.sh时总是会出错,后来知道了要进入**/usr/local/hadoop/sbin/hadoop**这个目录下才可以。
而开启hadoop时总是要运行./sbin/start-all.sh才可以执行,./sbin/实际上等同于运进入了**/usr/local/hadoop/sbin/hadoop**这个目录,如果要想直接运行start-all.sh来开启hadoop的话就需要变更PATH 这个环境变量,设置hadoop环境变量加入:export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin。就可以。
3)
没有Hadoop命令
当时在运行hadoop或者hdfs命令时会出现没有Hadoop命令的错误,这个老师上课讲了很多次,也是环境变量的问题。
执行:
vim ~/.bashrc
在里面加入这些就可以,这样就可以执行hadoop命令了。


4)
创建新文件夹失败:No such file or directory或File exits
- 前面那个错误老师上课也提到过,就是创建多级目录的问题,mkdir创建多层目录时需要在后面加一个 -p 选项。
- 后面那个错误是很简单但很常见的错误,就是已经存在目标的文件或者文件夹,路径出现冲突,解决问题的方法也很简单,就是更换一下名字,或者删除原文件。
安装hadoop集群时所遇到的问题
1)
当我执行下面代码时发现,只有namenode和secondarynamenode启动起来了,说明出现错误,于是改用另一个启动hadoop的代码start-all.sh,发现成功了,resourcemanager启动。最后单独执行mr-jobhistory-daemon.sh start historyserver,终于四个都启动起来。但是发生这个错误的原因始终不太明白。
执行:
start-dfs.sh
start-yarn.sh
mr-jobhistory-daemon.sh start historyserver
结果:

执行:
start-all.sh
结果:

执行:
mr-jobhistory-daemon.sh start historyserver
结果:

2)
还有一个错误是当时验证datanode是否正常启动时出现的,当时出现的错误是都为0,也就是无有效的datanode节点。
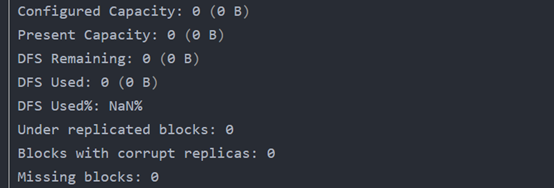
在网上查了很多方法,大部分都是说可能是datanode的安全模式没有关闭,可能是因为datanode开启了安全模式导致的。但是当时没有先试这个,而是做了以下几个。
- 1.检查所有自己已经配置的文件信息,(4个主要)以及Slaves文件。还有就是hosts中ip和主机名的对应关系。我检查了所有配置文件后发现没有出错的地方,于是把hdfs-site.xml中的dfs.replicatio设为了2,因为教程里他说一般设为3,我刚开始就设成了3。后来发现没有用。
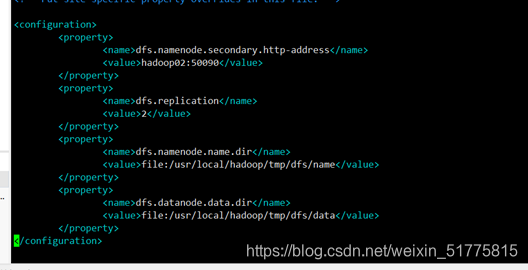
-
2.由于格式化次数太多,产生的结点的nm-local-dir中的id冲突,这个报错可以通过看产生的logs得出。这个方法我也觉得非常有可能,因为前期出错的时候我格式化了很多次,于是去查看logs,但是无果。
-
3.最后尝试查看datanode的安全模式是否关闭,所以使用命令
hdfsdfsadmin-safemode get查看发现真的没有关闭,于是使用以下命令关闭。hadoop dfsadmin -safemode leave。如下,关闭后执行发现已经正确。

以上是我在搭建集群时遇到的两个比较大的错误,其他的一些小错误大都为少打了或打错了或目录进错了,我想值得说的错误就这些。

















 5412
5412

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









