






引言
1、数据
样本:
每个数据集由一个个样本(example, sample)组成, 样本有时也叫做数据点(data point)或者数据实例(data instance)
样本属性:
通常每个样本由一组称为特征(features,或协变量(covariates))的属性组成
标签:
要预测的属性
数据维度:
当每个样本的特征类别数量都是相同的时候,其特征向量是固定长度的,这个长度被称为数据的维数(dimensionality)。 固定长度的特征向量是一个方便的属性,它可以用来量化学习大量样本。
训练数据集:
该数据集由一些为训练而收集的样本组成,训练数据集用于拟合模型参数
测试数据集:
新的数据集,测试数据集用于评估拟合的模型
- 当一个模型在训练集上表现良好,但不能推广到测试集时,这个模型被称为过拟合*(overfitting)的*
2、模型
3、目标函数
定义模型的优劣程度的度量,这个度量在大多数情况是“可优化”的,这被称之为目标函数(objective function)。 我们通常定义一个目标函数,并希望优化它到最低点。
常用目标函数:
预测数值:平方误差(squared error)—即预测值与实际值之差的平方
解决分类问题:最小化错误率—预测与实际情况不符的样本比例
4、优化算法
能够搜索出最佳参数,以最小化损失函数的一种算法, 深度学习中,大多流行的优化算法通常基于一种基本方法–梯度下降(gradient descent)—在每个步骤中,梯度下降法都会检查每个参数,看看如果仅对该参数进行少量变动,训练集损失会朝哪个方向移动。 然后,它在可以减少损失的方向上优化参数
5、监督学习
监督学习(supervised learning)擅长在“给定输入特征”的情况下预测标签。
每个“特征-标签”对都称为一个样本(example)。
有时,即使标签是未知的,样本也可以指代输入特征。 我们的目标是生成一个模型,能够将任何输入特征映射到标签(即预测)。
例:输入特征----生命体征,如心率、舒张压和收缩压
样本标签----''心脏病发作”或“心脏病没有发作”
步骤:
- 从已知大量数据样本中随机选取一个子集,为每个样本获取真实标签。有时,这些样本已有标签(例如,患者是否在下一年内康复?);有时,这些样本可能需要被人工标记(例如,图像分类)。这些输入和相应的标签一起构成了训练数据集;
- 选择有监督的学习算法,它将训练数据集作为输入,并输出一个“已完成学习的模型”;
- 将之前没有见过的样本特征放到这个“已完成学习的模型”中,使用模型的输出作为相应标签的预测。

①回归
标签取任意数值时,我们称之为回归问题,任何有关“有多少”的问题很可能就是回归问题
- 这个手术需要多少小时;
- 在未来6小时,这个镇会有多少降雨量。
②分类
预测样本属于哪个类别(category,正式称为类(class)),“哪一个”的问题叫做分类(classification)问题
- 从图像中看到的文本,并将手写字符映射到对应的已知字符之上
- 数据集可能由动物图像组成,标签可能是猫狗{猫,狗}两类
决策结果:类别、将“预期风险”作为损失函数,即需要将结果的概率乘以与之相关的收益(或伤害)
回归是训练一个回归函数来输出一个数值; 分类是训练一个分类器来输出预测的类别
③标记问题
学习预测不相互排斥的类别的问题称为多标签分类(multi-label classification)
④搜索
信息检索领域,我们希望对一组项目进行排序,对每个关键字进行权重赋值
⑤推荐系统
向特定用户进行“个性化”推荐
缺陷:1)我们的数据只包含“审查后的反馈”:用户更倾向于给他们感觉强烈的事物打分。 例如,在五分制电影评分中,会有许多五星级和一星级评分,但三星级却明显很少。
2)此外,推荐系统有可能形成反馈循环:推荐系统首先会优先推送一个购买量较大(可能被认为更好)的商品,然而目前用户的购买习惯往往是遵循推荐算法,但学习算法并不总是考虑到这一细节,进而更频繁地被推荐。
⑥序列学习
输入的数据之间环环相扣有关联,序列学习需要摄取输入序列或预测输出序列,或两者兼而有之
-
处理视频片段—通过前一帧的图像,我们可能对后一帧中发生的事情更有把握
-
想知道哪些是名词—鉴于有些词可能可以当动词也可以当名词,所以需要根据语境,及输入单词顺序来判断
Tom has dinner in Washington with Sally Ent - - - Ent - Et -
语音识别—输入序列是说话人的录音,输出序列是说话人所说内容的文本记录,数千个样本音频帧可能对应于一个单独的单词
6、无监督学习
不给标签的学习
7、与环境的互动

上面的模型,机器学习与环境是分开的,后期的环境变化不会影响前期的初始输入数据,我们想要解决这个问题,实现在学习过程也可以与环境互动,有以下几个问题
- 环境还记得我们以前做过什么吗?
- 环境是否有助于我们建模?例如,用户将文本读入语音识别器。
- 环境是否想要打败模型?例如,一个对抗性的设置,如垃圾邮件过滤或玩游戏?
- 环境是否重要?
- 环境是否变化?例如,未来的数据是否总是与过去相似,还是随着时间的推移会发生变化?是自然变化还是响应我们的自动化工具而发生变化?
8、强化学习
-
深度Q网络(Q-network)在雅达利游戏中仅使用视觉输入就击败了人类
-
AlphaGo 程序在棋盘游戏围棋中击败了世界冠军

特点:
1)任何监督学习问题可以转化为强化学习问题
创建一个强化学习智能体,每个分类对应一个“动作”。 然后,我们可以创建一个环境,该环境给予智能体的奖励(损失函数)
2)奖励信号可以对动作进行修正
3)处理部分可观测性问题
对当前动作的判断也取决于对之前动作的判断结果
4)不断更新最好策略
马尔可夫决策过程(markov decision process):环境可被完全观察到
上下文赌博机(contextual bandit problem):状态不依赖于之前的操作
多臂赌博机(multi-armed bandit problem):没有状态,只有一组最初未知回报的可用动作
预备知识
数据操作
入门
PyTorch 常用方法总结2:常用Tensor运算(均值、方差、极值、线性插值……) - 知乎 (zhihu.com)
张量表示一个由数值组成的数组,这个数组可能有多个维度。 具有一个轴的张量对应数学上的向量(vector); 具有两个轴的张量对应数学上的矩阵(matrix); 具有两个轴以上的张量没有特殊的数学名称。
[ ] import torch
[ ] x = torch.arange(12)// 创建一个行向量 x。这个行向量包含以0开始的前12个整数
//张量 x 中有 12 个元素。除非额外指定,新的张量将存储在内存中,并采用基于CPU的计算
[ ] x.shape//访问张量(沿每个轴的长度)的形状,输出:torch.Size([12])
x.numel()//输出:12
[ ] X = x.reshape(3,4)
X
//输出:tensor([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
//x.reshape(-1,4)
//x.reshape(3,-1),以上等同于 x.reshape(3,4),调用-1自动计算维度功能
//初始化矩阵
torch.zeros((2, 3, 4))
//输出:tensor([[[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.]],
[[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.]]])
torch.ones((2, 3, 4))
//输出:tensor([[[1., 1., 1., 1.],
[1., 1., 1., 1.],
[1., 1., 1., 1.]],
[[1., 1., 1., 1.],
[1., 1., 1., 1.],
[1., 1., 1., 1.]]])
//创建一个形状为(3,4)的张量。 其中的每个元素都从均值为0、标准差为1的标准高斯分布(正态分布)中随机采样
torch.randn(3, 4)
//输出:
tensor([[-0.3963, -1.1555, -0.4551, 0.7621],
[-0.9574, -0.6591, -0.9231, -0.9076],
[ 0.9436, -1.0515, 0.5868, 0.6835]])
torch.tensor([[2, 1, 4, 3], [1, 2, 3, 4], [4, 3, 2, 1]])//最外层的列表对应于轴0,内层的列表对应于轴1
//输出:
tensor([[2, 1, 4, 3],
[1, 2, 3, 4],
[4, 3, 2, 1]])
运算符
几个符号:
import torch
x = torch.tensor([1.0,2,4,8])
y = torch.tensor([2,2,2,2])
print(x+y)
print(x-y)
x*y
x/y
x**y

两个函数:
import torch
x = torch.tensor([1.0, 2, 4, 8])
print(torch.exp(x))

X.sum()//求所有元素和
拼接方式:
X = torch.arange(12, dtype=torch.float32).reshape((3,4))
Y = torch.tensor([[2.0, 1, 4, 3], [1, 2, 3, 4], [4, 3, 2, 1]])
torch.cat((X, Y), dim=0), torch.cat((X, Y), dim=1)

第一个按0轴拼接,第二个按1轴
逻辑运算符构建二元张量:
X ==Y

对应位置X,Y相等,则新张量中相应项的值为true

同X >Y
广播机制
对形状不同的矩阵进行两者运算操作,在大多数情况下,我们将沿着数组中长度为1的轴进行广播
import torch
X = torch.arange(3).reshape((3,1))
Y = torch.arange(2).reshape((1,2))
print(X)
print(Y)
print(X+Y)

矩阵a将复制列, 矩阵b将复制行,然后再按元素相加
索引和切片
切片:
X[-1], X[1:3]//用[-1]选择最后一个元素,可以用[1:3]选择第二个和第三个元素[ ]要前不要后
修改单个元素值:
import torch
X = torch.tensor([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
print(X)
X[1, 1] = 222222222
print(X)

利用索引修改张量中特定位置的元素值:
import torch
# 创建需要修改的源张量
source_tensor = torch.tensor([1, 2, 3, 4, 5])
# 创建索引张量
index_tensor = torch.tensor([0, 2, 4])
# 设置新的数值
new_value = 0
# 使用索引修改源张量中特定位置的数值
source_tensor.index_fill_(0, index_tensor, new_value)
print(source_tensor) # 输出修改后的源张量

利用索引修改张量中集体元素值:
X[0:2, :] = 12//:放前面代表所有0轴,放后面代表所有1轴

节省内存

张量改变后会分配新的内存,不可取!浪费空间
用切片表示法执行原地操作来减少操作的内存开销:

//适用于后续不再使用原来的那个X
before = id(X)
X += Y//等价于:X[:] = X + Y,原地操作
id(X) == before
转换为其他Python对象

numpy,torch张量互相转化
a = torch.tensor([3.5])
a, a.item(), float(a), int(a)

数据预处理
读取数据集
import torch
import os
import pandas as pd
os.makedirs(os.path.join('..', 'data'), exist_ok=True)//exist_ok为True,则在目标目录已存在的情况下不会触发FileExistsError异常
data_file = os.path.join('..', 'data', 'house_tiny.csv')
with open(data_file, 'w') as f:
f.write('NumRooms,Alley,Price\n') # 列名
f.write('NA,Pave,127500\n') # 每行表示一个数据样本
f.write('2,NA,106000\n')
f.write('4,NA,178100\n')
f.write('NA,NA,140000\n')
data = pd.read_csv(data_file)
print(data)

Python中的相对路径/ ./ …/详细解析_python 写入文件相对路径-优快云博客
处理缺失值
1、插值法:用一个替代值弥补缺失值
import os
import pandas as pd
data_file = os.path.join('..', 'data', 'house_tiny.csv')
data = pd.read_csv(data_file)
inputs, outputs = data.iloc[:, 0:2], data.iloc[:, 2] # data的前两列,data的最后一列
inputs = inputs.fillna("NaNN") # 用NaNN填充缺失值
print(inputs)

inputs = pd.get_dummies(inputs, dummy_na=True) # 转化为逻辑符号,总共有多少情况设为行标
print(inputs)

inputs = pd.get_dummies(inputs,dummy_na=True,dtype = int)#用dtype=int将boolean改为int
print(inputs)

2、删除法:直接忽略缺失值
转化为张量格式
import torch
X = torch.tensor(inputs.to_numpy(dtype=float))
y = torch.tensor(outputs.to_numpy(dtype=float))
X, y

线性代数
标量:
只有一个元素的张量
import torch
x = torch.tensor(3.0)
y = torch.tensor(2.0)
print(x + y, x * y, x / y, x**y)

向量
标量值组成的列表,标量值被称为向量的元素(element)或分量
x = torch.arange(4)//通过张量的索引来访问任一元素
x



矩阵转置:
A.T # 对称矩阵(symmetric matrix)等于其转置

张量:
张量是描述具有任意数量轴的n维数组的通用方法
- 向量是一阶张量
- 矩阵是二阶张量
X = torch.arange(24).reshape(2, 3, 4)
张量(近似理解为矩阵)的常用算法:
1)降维:
B = A.clone() # 通过分配新内存,将A的一个副本分配给B
A * B # 对应元素相乘,得到新矩阵
a = 2,a + X # 每个元素分别加a
a * X # 每个元素分别加a,张量形状不变
X.sum() # 计算所有元素和
A = torch.arange(20).reshape(4, 5)
print(A)
A_sum_axis0 = A.sum(axis=0)
print(A_sum_axis0)
print(A_sum_axis0.shape) #求轴0的和

A.sum(axis=[0, 1]) # 沿着行和列对矩阵求和 结果和A.sum()相同
A.mean(), A.sum() / A.numel() #计算任意形状张量的平均值
A.mean(axis=0), A.sum(axis=0) / A.shape[0] #求0轴平均值
2)非降维:
sum_A = A.sum(axis=1, keepdims=True) # A的维度不变,还是2维

A / sum_A # sum_A在对每行进行求和后仍保持两个轴,我们可以通过广播将A除以sum_A,可以理解为比例
A.cumsum(axis=0) # 沿0轴计算,新的数是前面行对应位置累加得到
点积:
相同位置的按元素乘积的和
torch.dot(x,y) # 必须维度相同 等价于torch.sum(x * y)
向量积:
x = torch.arange(4, dtype=torch.float32)
A = torch.arange(20, dtype=torch.float32).reshape(5, 4)
print(x)
print(A)
print(torch.mv(A,x)) # A的列维数(沿轴1的长度)必须与x的维数(其长度)相同

矩阵乘法:
B = torch.ones(4, 3)
torch.mm(A, B)
范数:

u = torch.tensor([3.0, -4.0])
torch.norm(u)


torch.abs(u).sum() # ads() 绝对值函数

torch.norm(torch.ones((4, 9)))
目标:
解决优化问题所希望获得的值,即范数
- 最大化分配给观测数据的概率
- 最小化预测和真实观测之间的距离
微积分
[基于Python的深度学习理论与实现(P6——导数、偏导数与梯度)_python算法中计算偏导是不是计算梯度-优快云博客](https://blog.youkuaiyun.com/p_zzzzzz/article/details/102631145?ops_request_misc=&request_id=&biz_id=102&utm_term=如何在一张图上画原函数和某一点的导数 深度学习&utm_medium=distribute.pc_search_result.none-task-blog-2allsobaiduweb~default-5-102631145.142v96pc_search_result_base7&spm=1018.2226.3001.4187)
导数:
import numpy as np
import torch
def f(x):
return 3*x**2 - 4*x
def numerical_lim(f,x,h):
return (f(x+h) - f(x))/h
h = 0.1
for i in range(5):
print(f'h={h:.5f},numerical limit = {numerical_lim(f,1,h):.5f}')//h={h:.5f}将变量 h 格式化为一个浮点数,保留小数点后五位
h *= 0.1
//通过不断减小 h 值,用数值方法逼近导数的过程。由于 h 在每次迭代中变小十分之一,你将会看到 h 值不断减小,而数值极限值将逐渐接近函数在 x = 1 处的导数值
// f-string用大括{ }表示被替换字段,其中直接填入替换内容即可,格式化输出

在一张图上画出原函数和某一点的导数
import numpy as np
import matplotlib.pyplot as plt
def numerical_diff(f,x):
h=1e-10
return (f(x+h)-f(x-h))/(2*h)
def f(x):
return x**2 + 2*x + 5
def tangent_line(f, x):
# numerical_diff 是一个用于计算函数在某点导数的函数
d = numerical_diff(f, x)
# 打印导数值
print(d)
# 计算切线的截距
y = f(x) - d * x
# 返回一个匿名函数,表示切线的方程
return lambda t: d * t + y
x = np.arange(0.0,20.0,0.1)
y = f(x)
plt.xlabel("x")
plt.ylabel("f(x)")
plt.plot(x,y)
tf = tangent_line(f, 5)
y2 = tf(x)
plt.plot(x, y2)
plt.show()
偏导数
函数定义:
def f_2d(x):
return x[0]**2 + x[1]**2
#或者根据numpy库的广播性质,直接写成np.sum(x**2)
求偏导:
import numpy as np
def function_2(x):
return x[0] ** 2 +x[1] ** 2 # 表示一个二元函数
def function_tmp0(x0): # x0是变量,另一个不重要的变量已经固定好了
return x0** 2 +4 ** 2
def function_tmp1(x1): # x1是变量,另一个不重要的变量已经固定好了
return 3 ** 2 + x1 ** 2
def numerical_diff(f,x): #微分函数
h = 1e-4
return (f(x + h) - f(x - h))/2 * h
x = np.array([3, 2])
result0=numerical_diff(function_tmp0,x[0])
result1=numerical_diff(function_tmp1,x[1])
print(result0,'\n',result1)

梯度
我们可以连结⼀个多元函数对其所有变量的偏导数,以得到该函数的梯度(gradient)向量。具体⽽⾔,设 函数f : R**n→ R的输⼊是⼀个n维向量x = [x1, x2, . . . , xn] T,并且输出是⼀个标量。函数f(x)相对于x的梯度 是⼀个包含n个偏导数的向量:

链式法则:

自动微分
[动手学深度学习笔记4——微积分&自动微分_微积分 深度学习-优快云博客](https://blog.youkuaiyun.com/weixin_66472769/article/details/129962722?ops_request_misc=&request_id=&biz_id=102&utm_term=深度学习 自动微分&utm_medium=distribute.pc_search_result.none-task-blog-2allsobaiduweb~default-0-129962722.142v96pc_search_result_base7&spm=1018.2226.3001.4187)
概率
基本概率统计
投掷一枚骰子,投一次的分布
import torch
from torch.distributions import multinomial
fair_probs = torch.ones([6]) / 6 # 样本容量为6
p1 = multinomial.Multinomial(1, fair_probs).sample() # 1代表实验进行1次
print(p1)

说明投中了“5”,这个数是随机的
p10=multinomial.Multinomial(10, fair_probs).sample() # 投10次

# 将结果存储为32位浮点数以进行除法
counts = multinomial.Multinomial(1000, fair_probs).sample() # 投1000次,用频率估计概率
counts / 1000 # 相对频率作为概率计值
import torch
from torch.distributions import multinomial
from d2l import torch as d2l
fair_probs = torch.ones([6]) / 6
counts = multinomial.Multinomial(10, fair_probs).sample((500,))
cum_counts = counts.cumsum(dim=0)
estimates = cum_counts / cum_counts.sum(dim=1, keepdims=True)
d2l.set_figsize((6, 4.5)) # 设置图形的大小
for i in range(6):
d2l.plt.plot(estimates[:, i].numpy(),
label=("P(die=" + str(i + 1) + ")")) # 标签
d2l.plt.axhline(y=0.167, color='black', linestyle='dashed') # 0.167是上面1000组数据得出的每个结果的真实的概率,在此处画一条黑线
d2l.plt.gca().set_xlabel('Groups of experiments')
d2l.plt.gca().set_ylabel('Estimated probability')
d2l.plt.legend();
d2l.plt.show()

查阅文档
查询模块所有属性
import torch
print(dir(torch.distributions)) # 查询随机数生成模块中的所有属性:dir
查找特定函数和类的用法
help(torch.ones) # 查找torch.ones()的用法
线性神经网络
线性回归基本元素:
训练数据集(training data set)或训练集(training set):
想要开发一个具有一定功能的模型,必须要有大量的相关事例作为数据集,这些事例就是训练集。有了这一些事例,就可以根据自变量和因变量之间的关系来作为模型预测的依据。
样本(sample):
每组数据就是样本,也可以称为数据点(data point)或数据样本(data instance)。
标签(label)或目标(target):试图预测的目标。
特征(feature)或协变量(covariate):预测所依据的自变量。
线性回归模型

b称为偏置(bias)、偏移量(offset)或截距(intercept) 不可缺少的
w称为权重(weight)
数据集的意义是帮我们找到相对合适的b和w
即使确信特征与标签的潜在关系是线性的, 我们也会加入一个噪声项来考虑观测误差带来的影响。
损失函数


解析解


随机梯度下降
在我们无法得到解析解的情况下,我们仍然可以有效地训练模型
深度学习数学基础(二)~随机梯度下降(Stochastic Gradient Descent, SGD)-优快云博客
矢量化加速:
调用库函数比自己写for循环节约时间
- 2个1000维向量相加
- (for循环对a[i]+b[i] / a+b 后面更快)
正态分布与平方损失:
正态分布也称为高斯分布,正态分布的概率密度函数是:

def normal(x,mu,sigma):
p = 1 / math.sqrt(2 * math.pi * sigma **2)
return p * np.exp(-0.5 / sigma**2 * (x - mu)**2)
x = np.arange(-7,7,0.01)
params = [(0,1),(0,2),(3,1)]
d2l.plot(x, [normal(x, mu, sigma) for mu, sigma in params], xlabel='x',
ylabel='p(x)', figsize=(4.5, 2.5),
legend=[f'mean {mu}, std {sigma}' for mu, sigma in params])

我们假设观测中包含噪声,噪声服从于正态分布

写出w,b的极大似然估计函数:

从线性回归到深度网络
线性回归其实是一个单层的神经网络

上图中,输入是x1,x2,xd,因此输入层中的输入数是d。网格的输出为o1,输出层的输出数是1。图中的神经网络的层数是1,我们将线性回归模型是为仅有单个人工神经元组成的神经网络,或者称为单层神经网络。
对于线性回归,每一个输入与输出相连,这种变换称为全连接层。
线性回归的从零开始实现
1、生成数据集
import random
import torch
from d2l import torch as d2l
def synthetic_data(w, b, num_example):
X = torch.normal(0, 1, (num_example, len(w)))
# torch.normal 函数生成一个形状为 (num_example, len(w)) 的表示特征的随机张量 X
Y = torch.matmul(X, w) + b
# 一个线性回归模型的基本公式:Y = Xw + b,其中 X 是特征,w 是权重,b 是偏置
Y += torch.normal(0, 0.01, Y.shape)
# 向标签 Y 添加了服从正态分布的噪声,模拟了实际数据中的随机噪声
return X, Y.reshape((-1, 1))
true_w = torch.tensor([2, -3.4])
# 定义了真实的权重向量 true_w
true_b = 4.2
# 真实的偏置 true_b
features, labels = synthetic_data(true_w, true_b, 1000)
# 调用 synthetic_data 函数生成包含 1000 个样本的合成数据,其中 features 是特征,labels 是相应的标签
print('features:', features[0], '\nlabel:', labels[0])
# 打印第一个样本的特征和标签
d2l.set_figsize()
# 设置图表大小的函数
d2l.plt.scatter(features[:, (1)].detach().numpy(), labels.detach().numpy(), 1)
# 使用 matplotlib 绘制散点图,显示 features 中的第二个特征与 labels 之间的关系
# features[:, (1)],在 features 中选择所有行的第二列
# .detach().numpy(): 这部分是将 PyTorch 张量转换为 NumPy 数组。.detach() 方法用于创建张量的副本,这是因为 PyTorch 张量和 NumPy 数组有一些不同的性质,而 .numpy() 方法将张量转换为 NumPy 数组
# 1: 这是指定散点的大小。在这里,散点的大小被设置为 1
# d2l.plt.scatter: 这是 d2l 模块中的一个函数,用于创建散点图
d2l.plt.show()
# 展示图表

2、读取数据集
import torch
import random
# 定义数据迭代器函数,用于随机读取小批量样本
def data_iter(batch_size, features, labels):
num_examples = len(features)
indices = list(range(num_examples))
# 将列表 indices 中的元素随机打乱顺序,这些样本是随机读取的,没有特定的顺序
random.shuffle(indices)
for i in range(0, num_examples, batch_size): #遍历整个数据集,每次迭代取一个小批量的样本,range 函数中的参数表示每次迭代增加的步长,即小批量的大小 batch_size
# 选取当前小批量的样本索引
# 使用 min(i + batch_size, num_examples) 是为了确保切片不会越界,即使在数据集样本数不能整除 batch_size 的情况下也能正确处理
# indices[i: min(i + batch_size, num_examples)] 表示从 indices 中切片出当前小批量的索引
batch_indices = torch.tensor(
indices[i: min(i + batch_size, num_examples)])
# 返回当前小批量的特征和标签
# yield 关键字用于将当前小批量的特征和标签生成为一个迭代器对象
# 当调用这个数据迭代器的时候,每次会得到一个包含当前小批量特征和标签的元组
yield features[batch_indices], labels[batch_indices]
# 定义生成合成数据的函数,其中包含噪声
def synthetic_data(w, b, num_examples):
"""生成 y = Xw + b + 噪声"""
X = torch.normal(0, 1, (num_examples, len(w)))
y = torch.matmul(X, w) + b
y += torch.normal(0, 0.01, y.shape)
return X, y.reshape((-1, 1))
# 设定真实的权重和偏置
true_w = torch.tensor([2, -3.4])
true_b = 4.2
# 生成包含噪声的合成数据集
features, labels = synthetic_data(true_w, true_b, 1000)
# 设定每个小批量的样本数
batch_size = 10
# 使用数据迭代器打印第一个小批量的样本
for X, y in data_iter(batch_size, features, labels):
print(X, '\n', y)
break
3、初始化模型参数
在使用随机梯度下降优化我们的模型参数之前,我们需要有一些参数。我们通过从均值为0、标准差为0.01的正态分布中采样随机数来初始化权重,将偏置b初始化0
w = torch.normal(0,0.01,size=(2,1),requires_grad = True)
b = torch.zeros(1,requires_grad=True)
初始化参数之后,我们需要计算损失函数关于模型参数的梯度,然后向着减小损失的方向更新每一个参数。使用自动微分计算梯度。
4、定义模型
我们只需要计算输入特征X和模型权重w的矩阵,然后再加上b,Xw是一个向量(列向量),使用广播机制,标量b会被加到向量的每一个分量上。
def linreg(X,w,b):
"""线性回归模型"""
return torch.matmul(X,w) + b
5、定义损失函数
使用平方损失函数:这里需要注意,我们预测出的y是一个1000 x 1 的列向量,所以需要将真实的y形状转换一下:y.reshape(y_hat.shape)
def squared_loss(y_hat,y):
"""均方损失"""
return (y_hat - y.reshape(y_hat.shape)) **2 / 2
# 将张量 y 重新调整为与 y_hat 具有相同形状的新张量
# 在深度学习中,形状调整经常用于确保模型输出和标签的形状匹配,从而能够正确计算损失
6、定义优化算法
小批量随机梯度下降
该函数接受模型参数集合、学习速率和批量大小作为输入。每 一步更新的大小由学习速率决定
def sgd(params, lr, batch_size): #@save
"""小批量随机梯度下降"""
with torch.no_grad():
for param in params:
param -= lr * param.grad / batch_size
param.grad.zero_()
7、训练
lr = 0.03 # 超参数 学习率 学习率是一个超参数,用于控制每次参数更新的步长
num_epochs = 3 # 超参数 迭代周期 迭代周期是指整个训练数据集被模型使用的次数
net = linreg # net是一个线性回归模型
loss = squared_loss # loss是损失函数,用于衡量模型预测与实际标签之间的差距。这里使用的是均方误差损失函数(squared_loss)
for epoch in range(num_epochs):
for X, y in data_iter(batch_size, features, labels):
# data_iter函数产生小批量的训练数据
l = loss(net(X, w, b), y)
# X和y的小批量损失,net(X, w, b)计算模型的预测值,然后与实际标签y计算损失
l.sum().backward()
# 对损失进行反向传播,计算梯度
sgd([w, b], lr, batch_size)
# 使用随机梯度下降(SGD)更新模型参数w和b
with torch.no_grad():
# 在每个迭代周期结束后,计算整个训练集上的损失,并打印出来
train_l = loss(net(features, w, b), labels)
print(f'epoch {epoch + 1}, loss {float(train_l.mean()):f}')
print(f'w的估计误差: {true_w - w.reshape(true_w.shape)}')
print(f'b的估计误差: {true_b - b}')
# 计算它们与训练后的参数之间的差距来评估拟合效果

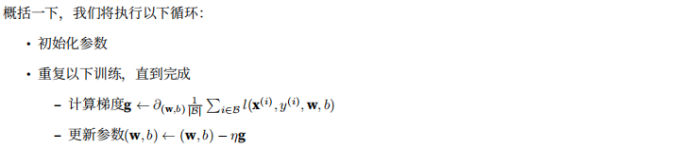
线性回归的简洁实现
1、生成数据集
import numpy as np
import torch
from torch.utils import data
from d2l import torch as d2l
true_w = torch.tensor([2, -3.4])
true_b = 4.2
features, labels = d2l.synthetic_data(true_w, true_b, 1000)
2、读取数据集
def load_array(data_arrays, batch_size, is_train=True): #@save
"""构造一个PyTorch数据迭代器"""
dataset = data.TensorDataset(*data_arrays)
return data.DataLoader(dataset, batch_size, shuffle=is_train)
batch_size = 10
data_iter = load_array((features, labels), batch_size)
3、初始化模型参数
net[0].weight.data.normal_(0, 0.01)
# 对模型的权重进行初始化,采用正态分布(mean=0, std=0.01)
net[0].bias.data.fill_(0)
# 对模型的偏置进行初始化,将偏置设为0
4、定义模型
# nn是神经网络的缩写
from torch import nn
net = nn.Sequential(nn.Linear(2, 1))
# 使用nn.Sequential封装了一个线性层(nn.Linear)
# 这个线性层将输入维度为2(nn.Linear(2, 1)),输出维度为1。这里是一个单层的线性回归模型
先 4 再 3
5、定义损失函数
loss = nn.MSELoss()
6、定义优化算法
trainer = paddle.optimizer.SGD(learning_rate=0.03,
parameters=net.parameters())
# 随机梯度下降(SGD)优化器来配置一个训练器(trainer)
# parameters=net.parameters(): 这里将模型(net)的参数传递给优化器。net.parameters()返回模型中所有需要训练的参数。优化器将使用这些参数来更新模型的权重和偏置
#通过在每个训练迭代中重复调用trainer.step(),可以逐渐调整模型参数以最小化损失函数,实现模型的训练
7、训练
num_epochs = 3
# 设置训练的迭代周期数为3
for epoch in range(num_epochs):
for i,(X, y) in enumerate (data_iter()): # 使用data_iter()函数产生小批量的训练数据,enumerate用于同时获取索引和数据
l = loss(net(X) ,y)
trainer.clear_grad() # 清除之前的梯度信息,防止梯度累积
l.backward() # 对损失进行反向传播,计算梯度
trainer.step()3 # 通过调用trainer.step()来执行一步优化,使用之前计算的梯度更新模型的参数
l = loss(net(features), labels)
print(f'epoch {epoch + 1},'f'loss {l}')
# 在每个迭代周期结束后,计算整个训练集上的损失,并打印出来。这样可以观察损失在训练过程中的变化
w = net[0].weight
print('w的估计误差:', true_w - w.reshape(true_w.shape))
b = net[0].bias
print('b的估计误差:', true_b - b)
softmax回归
回归是问“多少”,可以用来预测多少,如预测房屋价格。
分类是问“哪一个”,如某个电子邮件是否是垃圾邮件,某个图像描绘的是猫还是狗。
这里引入“硬性”类别和“软性”类别的概念:
- “硬性”类别:属于哪个类别
- “软性”类别:属于每个类别的概率
我们关心硬类别,但仍然使用软类别的模型。
softmax:最大概率的标签,能够将未规范化的预测变换为非负数,并且总和为1,同时能够让模型保持可导
1、分类问题
我们从一个图像分类问题开始。 假设每次输入是一个的灰度图像。 我们可以用一个标量表示每个像素值,每个图像对应四个特征。 此外,假设每个图像属于类别"猫""鸡"和"狗"中的一个
独热编码(one-hot encoding)。独热编码是一个向量,它的分量和类别一样多。 类别对应的分量设置为1,其他所有分量设置为0。 在我们的例子中,标签将是一个三维向量, 其中对应于“猫”、对应于“鸡”、对应于“狗”:

2、网络架构
为了估计所有可能类别的条件概率,我们需要一个有多个输出的模型,每个类别对应一个输出。
在上述例子(猫,鸡,狗)中,由于有4个特征和3个可能的输出类别,我们将需要12个标量来表示权重(带下标的w),3个标量来表示偏置(带下标的b)。下面是为每个输入计算三个未规范化的预测(logit):o1、o2和o3

用神经网络来描述这个计算过程,与线性回归一样,softmax回归也是一个单层神经网络。由于计算每个输出o1、o2和o3取决于所有输入x1,x2,x3和x4,所以softmax回归的输出层也是全连接层。

3、全连接层的参数开销
全连接层是“完全”连接的,对于任何具有d个输入和q个输出的全连接层,参数开销为O(dq)。
若将d个输入转换为q个输出的成本可以减少到O(dq/n),其中超参数n可以由我们灵活指定。
4、 softmax运算
我们希望模型输出y(j)可以视为属于类j的概率,然后选择具有最大输出值的类别argmaxy(j)作为我们的预测。例如:y1、y2和y3分别为0.1、0.8和0.1,那我们预测的类别为2,在我们的例子中代表“鸡”。
问题:但我们不能将未规范化的预测o直接作为输出,因为将线性层的输出直接视为概率时会存在一些问题:
- 我们没有限制这些数字的总和为1
- 根据输入的不同,它们可以为负值
要将输出视为概率,我们必须保证在任何数据上的输出都是非负的且总和为1。
校准:此外,我们需要一个训练的目标函数,来激励模型精准地估计概率。例如。在分类器输出0.5的所有样本中,我们希望这些样本是刚好有一半实际上属于预测的类别。 这个属性叫做(calibration)。
softmax函数: softmax函数能够将未规范化的预测变换为非负数并且总和为1,同时让模型保持可导的性质(可以理解为先求绝对值再除总和来计算占比)

尽管softmax是一个非线性函数,但softmax回归的输出仍然由输入特征的仿射变换决定。因此,softmax回归是一个线性模型
5、 小批量样本的矢量化
为了提高计算效率并且充分利用GPU,我们通常会对小批量样本的数据执行矢量计算。
假设我们读取了一个批量的样本X,其中特征维度(输入数量)为d,批量大小为n。此外,假设我们在输出中有q个类别。那么小批量样本各参数的矢量为:

softmax回归的矢量计算表达式为:

相对于一次处理一个样本, 小批量样本的矢量化加快了X和W的矩阵-向量乘法。 由于X中的每一行代表一个数据样本, 那么softmax运算可以按行(rowwise)执行:对于O的每一行,我们先对所有项进行幂运算,然后通过求和对它们进行标准化。
6、损失函数
采用最大似然估计来度量预测的效果,同前面的方法
6.1 对数似然
结合概率论理解,简化计算
softmax函数给出了一个向量y, 我们可以将其视为“对给定任意输入x的每个类的条件概率”。例如,y=P(y = 猫|x)。假设整个数据集{X,Y}具有n个样本,其中索引i的样本由特征向量x和独热标签向量y组成。我们可以将估计值与实际值进行比较:

根据最大似然估计,我们最大化P(Y|X),相当于最小化负对数似然:

6.2 softmax及其导数
利用softmax的定义,我们得到:

考虑相对于任何未规范化的预测o的导数,我们得到:

导数是softmax模型分配的概率与实际发生的情况(由独热标签向量表示)之间的差异。
6.3 交叉熵损失
对于标签y,我们可以使用与以前相同的表示形式。 唯一的区别是,我们现在用一个概率向量表示,如(0.1,0.2,0.7),而不是包含二元项的向量(0,0,1)。
对于任何标签y和模型预测y^,损失函数为(通常被称为交叉熵函数,它是所有标签分布的预期损失值):

7、信息论基础
7.1 熵
通常,一个信源发送出什么符号是不确定的,衡量它可以根据其出现的概率来度量。概率大,出现机会多,不确定性小;反之不确定性就大。

7.2 信息量
应用概率来描述不确定性。信息是用不确定性的量度定义的。一个消息的可能性愈小,其信息愈多;而消息的可能性愈大,则其信息愈少。事件出现的概率小,不确定性越多,信息量就大,反之则少。
如果我们不能完全预测每一个事件,那么我们有时可能会感到”惊异”。 克劳德·香农决定用信息量

来量化这种惊异程度。 在观察一个事件j时,并赋予它(主观)概率P(j)。 当我们赋予一个事件较低的概率时,我们的惊异会更大,该事件的信息量也就更大。
7.3 重新审视交叉熵
交叉熵从P到Q,记为H(P,Q)。我们可以把交叉熵想象为“主观概率为Q的观察者在看到根据概率P生成的数据时的预期惊异”。
当P=Q时,交叉熵达到最低。 在这种情况下,从P到Q的交叉熵是H(P,P)=H(P )。
我们从两方面考虑交叉熵分类目标:
- 最大化观测数据的似然
- 最小化传达标签所需的惊异
8、 模型预测与评估
在训练softmax回归模型后,给出任何样本特征,我们可以预测每个输出类别的概率。 通常我们使用预测概率最高的类别作为输出类别。 如果预测与实际类别(标签)一致,则预测是正确的。
图像分类数据集
| torchvision:torch类型的可视化包,一般计算机视觉和数据可视化需要使用 |
| from torchvision import transforms:该组件经常用于图片的修改(一般数据集中的图片都是 PIL格式,使用的时候需要转化为tenser,而在加入函数时常需要转化为nadarry(numpy中的 ndarray为多维数组)) |
| d2l.use_svg_display():使用什么模式展示图片 |
import torch
import torchvision #pytorch用于计算机视觉的一个库
from torch.utils import data
from torchvision import transforms #导入对数据操作的模具
from d2l import torch as d2l
d2l.use_svg_display() #使用svg展示图片
1、读取数据集
通过框架中的内置函数将Fashion-MNIST数据集下载并读取到内存中
| torchvision.datasets:一般用于图像数据集的下载和获取 eg: torchvision.datasets.FashionMNIST( root=, train=True, transform=, download=True): |
| train:是否为训练集 |
| transform:使用什么格式转换(可以从transforms组件中选择) |
| dowload:是否下载对应数据集 |
| .FashionMNIST可以更换为其他数据源 |
# 通过ToTensor实例将图像数据从PIL类型变换成32位浮点数格式,
# 并除以255使得所有像素的数值均在0~1之间
trans = transforms.ToTensor() #对图片进行预处理,转换为tensor格式
# 下载训练集和测试集,并保存
mnist_train = torchvision.datasets.FashionMNIST(
root="../data", train=True, transform=trans,download=True)
mnist_test = torchvision.datasets.FashionMNIST(
root="../data", train=False, transform=trans,download=True)
# 输出训练集和测试集的大小
len(mnist_train), len(mnist_test)

每个输入图像的高度和宽度均为28像素。 数据集由灰度图像组成,其通道数为1(彩色图像通道数为3)。
# 索引到第一张图片
mnist_train[0][0].shape # 输入图像的通道数、高度和宽度

Fashion-MNIST中包含的10个类别,分别为t-shirt(T恤)、trouser(裤子)、pullover(套衫)、dress(连衣裙)、coat(外套)、sandal(凉鞋)、shirt(衬衫)、sneaker(运动鞋)、bag(包)和ankle boot(短靴)。以下函数用于在数字标签索引及其文本名称之间进行转换。
# 获取数据集的标签
def get_fashion_mnist_labels(labels): #@save
"""返回Fashion-MNIST数据集的文本标签"""
text_labels = ['t-shirt', 'trouser', 'pullover', 'dress', 'coat','sandal', 'shirt', 'sneaker', 'bag', 'ankle boot']
return [text_labels[int(i)] for i in labels]
创建一个函数来可视化这些样本。
| plt.subplots()是一个返回包含图形和轴对象的元组的函数。因此,在使用时fig, ax = plt.subplots(),将此元组解压缩到变量fig和ax。 |
| enumerate()函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中,生成可以遍历的每个元素有对应序号(0, 1, 2, 3…)的enumerate对象。 |
| zip()函数用于将多个可迭代对象作为参数,依次将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的对象,里面的每个元素大概为i,(ax,img)的形式。 |
| imshow()可以接收二维,三维甚至多维数组。二维默认为一通道即灰度图像,三维需要在第三个维度指定图像通道数(必须是第三维) |
def show_images(imgs, num_rows, num_cols, titles=None, scale=1.5): #@save
"""绘制图像列表"""
figsize = (num_cols * scale, num_rows * scale)
# 第1个参数是个图,一般不用;第2个axer类似于图片的索引矩阵(行,列)
_, axes = d2l.plt.subplots(num_rows, num_cols, figsize=figsize) # axes:轴
axes = axes.flatten()
# 遍历生成形如i, (ax, img)形式的enumerate对象
for i, (ax, img) in enumerate(zip(axes, imgs)):
if torch.is_tensor(img):
# 图片张量
ax.imshow(img.numpy())
else:
# PIL图片
ax.imshow(img)
ax.axes.get_xaxis().set_visible(False) #x轴隐藏
ax.axes.get_yaxis().set_visible(False) #y轴隐藏
if titles:
ax.set_title(titles[i]) #显示标题
return axes
以下是训练数据集中前几个样本的图像及其相应的标签。
| next() 返回迭代器的下一个项目。 |
| next() 函数要和生成迭代器的iter() 函数一起使用。 |
| 我们可以通过iter()函数获取这些可迭代对象的迭代器。然后,我们可以对获取到的迭代器不断使⽤next()函数来获取下⼀条数据。 |
注:当我们已经迭代完最后⼀个数据之后,再次调⽤next()函数会抛出 StopIteration的异常 ,来告诉我们所有数据都已迭代完成,不⽤再执⾏ next()函数了。
# 使用next()函数获取批量大小为18的训练集的图像和标签
X, y = next(iter(data.DataLoader(mnist_train, batch_size=18)))
#显示18张图片,宽度为28,长度为28,总共为2行9列
# 绘制两行图片,每一行有9张图片,并获取标签
show_images(X.reshape(18, 28, 28), 2, 9, titles=get_fashion_mnist_labels(y));
# 显示18张图片,宽度为28,长度为28,总共为2行9列
# 绘制两行图片,每一行有9张图片,并获取标签
fig, axs = plt.subplots(2, 9, figsize=(9, 2))
axs = axs.flatten()
for img, label, ax in zip(X, y, axs):
ax.imshow(img.reshape(28, 28), cmap='gray')
ax.set_title(get_fashion_mnist_labels([label])[0])
ax.axis('off')
plt.show()

暂时还不太清楚为啥一下显示俩
2、读取小批量
为了使我们在读取训练集和测试集时更容易,我们使用内置的数据迭代器,而不是从零开始创建。 回顾一下,在每次迭代中,数据加载器每次都会读取一小批量数据,大小为batch_size。 通过内置数据迭代器,我们可以随机打乱了所有样本,从而无偏见地读取小批量。
batch_size = 256
def get_dataloader_workers(): #@save
"""使用4个进程来读取数据"""
return 4
# 训练集需要设置shuffle=True打乱顺序
train_iter = data.DataLoader(mnist_train, batch_size, shuffle=True,
num_workers=get_dataloader_workers())
读取训练数据所需的时间:
timer = d2l.Timer() #调用Timer函数,测试速度
for X, y in train_iter:
continue
print(f'{timer.stop():.2f}sec' ) #输出读取数据所用的秒数,精度为2位小数

3、整合所有组件
定义load_data_fashion_mnist函数,用于获取和读取Fashion-MNIST数据集。这个函数返回训练集和验证集的数据迭代器。 此外,这个函数还接受一个可选参数resize,用来将图像大小调整为另一种形状。
| torchvision.transforms是pytorch中的图像预处理包,一般用Compose把多个步骤整合到一起。 |
| insert函数是一种用于列表的内置函数。这个函数的作用是在一个列表中的指定位置,插入一个元素。 |

def load_data_fashion_mnist(batch_size, resize=None): #@save
"""下载Fashion-MNIST数据集,然后将其加载到内存中"""
# 转换为tensor
trans = [transforms.ToTensor()]
if resize:
trans.insert(0, transforms.Resize(resize))
# compose整合步骤
trans = transforms.Compose(trans)
# 下载训练集和测试集,并返回到train_iter中,用于之后的训练
mnist_train = torchvision.datasets.FashionMNIST(
root="../data", train=True, transform=trans, download=True)
mnist_test = torchvision.datasets.FashionMNIST(
root="../data", train=False, transform=trans, download=True)
return (data.DataLoader(mnist_train, batch_size, shuffle=True,
num_workers=get_dataloader_workers()),
data.DataLoader(mnist_test, batch_size, shuffle=False,
num_workers=get_dataloader_workers()))
下面,我们通过指定resize参数来测试load_data_fashion_mnist函数的图像大小调整功能:
train_iter, test_iter = load_data_fashion_mnist(32, resize=64)
for X, y in train_iter:
print(X.shape, X.dtype, y.shape, y.dtype)
break

softmax回归的从开始实现
softmax回归原理
softmax回归是一个分类问题。
回归和分类的区别:回归估计一个连续值,分类预测一个离散类别。

softmax思想:希望正确的类执行度远远大于其他类(关心相对值)


softmax保证输出是概率

衡量的损失函数:交叉熵损失


应用场景例如:
(1)数字识别

(2)图像分类
(3)判断软件类型
(4)对文字分类,评论情感类别
等等
1、导包:
import torch
from IPython import display
from d2l import torch as d2l
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
2、初始化参数模型
我们的数据集有10个类别,所以网络输出维度为10。 因此,权重将构成一个(784 \times 10)的矩阵, 偏置将构成一个(1 \times 10)的行向量。 与线性回归一样,我们将使用正态分布初始化我们的权重W,偏置初始化为0
num_inputs = 784 # 输入图像的像素数
num_outputs = 10
W = torch.normal(0, 0.01, size=(num_inputs, num_outputs), requires_grad=True)
# requires_grad=True 表示这个变量需要梯度,因为它将用于反向传播和梯度下降优化
# 前两个参数代表值,从(0,1)正态分布中随机抽取
# 第二个参数为矩阵大小
b = torch.zeros(num_outputs, requires_grad=True)
3、定义softmax操作
实现softmax由三个步骤组成:
- 对每个项求幂(使用
exp)(即e的x次方,目的变成非负数) - 对每一行求和(小批量中每个样本是一行),得到每个样本的规范化常数(将每一个1中求得的值加和)
- 将每一行除以其规范化常数,确保结果的和为1。
def softmax(X):
X_exp = torch.exp(X)
partition = X_exp.sum(1, keepdim=True) # keepdim=True 保持维度的数量不变
return X_exp / partition # 这里应用了广播机制
代码定义了输入如何通过网络映射到输出。 注意,将数据传递到模型之前,我们使用reshape函数将每张原始图像展平为向量
打开神经网络的黑箱(一) 全连接模型的空间划分与编码逻辑_单层全连接网络-优快云博客
| X.reshape((-1, W.shape[0])): 这一部分对输入张量 X 进行形状变换,将其变为一个二维张量,其中的列数(-1 表示自动推断)与权重矩阵 W 的行数相同。这通常是为了确保输入与权重矩阵的乘法能够正确执行 |
| torch.matmul(..., W) + b: 这一部分执行了矩阵乘法操作,将变形后的输入 X 与权重矩阵 W 相乘,然后加上偏置项 b |
| 函数的实质是一个单层的全连接神经网络 |
def net(X):
return softmax(torch.matmul(X.reshape((-1, W.shape[0])), W) + b)
5、定义损失函数
目前分类问题的数量远远超过回归问题的数量,这里采用交叉熵损失函数,交叉熵采用真实标签的预测概率的负对数似然
- 创建数据样本y_hat,包括2个样本在3个类别的概率,以及对应的标签y。
- 通过y知道第一个样本中第一类是正确的预测,第二个样本中第三类是正确的预测。
- 将y作为y_hat的索引,选择第一个样本第一类的概率和第二个样本第三类的概率。

实现交叉熵损失函数
len(x):获取x的长度range(x):生成从0开始,小于参数x的整数序列- torch.log(y_hat[range(len(y_hat)), y]): 在这个函数内部,它首先利用y中的真实标签作为索引来获取y_hat中对应标签的预测概率,并对这些概率取对数,然后取相反数。这是交叉熵损失函数的数学表达式,用于衡量两个概率分布之间的差异,从而评估模型输出与真实标签之间的误差
# 定义交叉熵损失函数
def cross_entropy(y_hat, y):
return - torch.log(y_hat[range(len(y_hat)), y])
cross_entropy(y_hat, y)
6、分类精度
给定预测概率分布y_hat,当我们必须输出硬预测(hard prediction)时, 我们通常选择预测概率最高的类。
- 当预测与标签分类y一致时,即是正确的。
- 分类精度即正确预测数量与总预测数量之比。
- y_hat是矩阵,假定第二个维度存储每个类的预测分数。
- 使用argmax获得每行中最大元素的索引来获得预测类别。
- 将预测类别与真实y元素进行比较。
- 通过"=="比较,结果为包含0(错)和1(对)的张量,求和得到正确预测的数量。
| argmax():返回的是最大数的索引.argmax有一个参数axis,默认是0,表示第几维的最大值 |
def accuracy(y_hat, y): #@save
"""计算预测正确的数量"""
# len是查看矩阵的行数
# y_hat.shape[1]就是去列数
if len(y_hat.shape) > 1 and y_hat.shape[1] > 1:
# 第2个维度为预测标签,取最大元素
y_hat = y_hat.argmax(axis=1)
# #将y_hat转换为y的数据类型然后作比较,cmp函数存储bool类型
cmp = y_hat.type(y.dtype) == y
return float(cmp.type(y.dtype).sum()) #将正确预测的数量相加
y_hat和y分别作为预测的概率分布和标签。- 第一个样本的预测类别是2(该行的最大元素为0.6,索引为2),这与实际标签0不一致。第二个样本的预测类别是2(该行的最大元素为0.5,索引为2),这与实际标签2一致。 因此,这两个样本的分类精度率为0.5。

对于任意数据迭代器data_iter可访问的数据集, 我们可以评估在任意模型net的精度
with torch.no_grad():不使用时,此时有grad_fn=属性,表示计算的结果在一计算图当中,可以进行梯度反传等操作。使用时,表明当前计算不需要反向传播,使用之后,强制后边的内容不进行计算图的构建。
|
返回值:如果对象的类型与参数二(classinfo)的类型相同返回true,否则false。
|
| torch.nn.Module():它是所有的神经网络的根父类, 神经网络必然要继承。 |
| net.eval():pytorch中用来将神经网络设置为评估模型的方法。 评估模式下,网络的参数不会被更新,dropout和batch normalization层的行为也会有所不同,以便模型更好地进行预测。 评估模式下计算图不会被跟踪,这样可以节省内存使用,提升性能。 |
| y.numel():Python中的张量计算方法,用于存储新的张量并存储在内存中。可以通过指定形状的shape属性来访问张量的形状 |
def evaluate_accuracy(net, data_iter): #@save
"""计算在指定数据集上模型的精度"""
# 判断模型是否为深度学习模型
if isinstance(net, torch.nn.Module):
net.eval() # 将模型设置为评估模式
metric = Accumulator(2) # metric:度量,累加正确预测数、预测总数
# 梯度不需要反向传播
with torch.no_grad():
# 每次从迭代器中拿出一个X和y
for X, y in data_iter:
# metric[0, 1]分别为网络预测正确的数量和总预测的数量
# nex(X):X放在net模型中进行softmax操作
# numel()函数:返回数组中元素的个数,在此可以求得样本数
metric.add(accuracy(net(X), y), y.numel())
# # metric[0, 1]分别为网络预测正确数量和总预测数量
return metric[0] / metric[1]
定义一个实用程序类Accumulator,用于对多个变量进行累加,Accumulator实例中创建了2个变量, 分别用于存储正确预测的数量和预测的总数量(主要目的是提供一个简单的方式来对一组变量进行累加,并且可以方便地重置和获取累加的结果)
| __init__():创建一个类,初始化类实例时就会自动执行__init__()方法。该方法的第一个参数为self,表示的就是类的实例。self后面跟随的其他参数就是创建类实例时要传入的参数 |
| reset();重新设置空间大小并初始化 |
| __getitem__():接收一个idx参数,这个参数就是自己给的索引值,返回self.data[idx],实现类似数组的取操作 |
class Accumulator: #@save
"""在n个变量上累加"""
# 初始化根据传进来n的大小来创建n个空间,全部初始化为0.0
def __init__(self, n):
self.data = [0.0] * n
# 把原来类中对应位置的data和新传入的args做a + float(b)加法操作然后重新赋给该位置的data,从而达到累加器的累加效果
def add(self, *args): #将传递的参数与累加器中相应位置的数据相加。使用了可变参数*args,因此可以接受任意数量的参数
self.data = [a + float(b) for a, b in zip(self.data, args)]
# 重新设置空间大小并初始化。
def reset(self):# 这个方法重新设置累加器的数据,将所有的数据重新初始化为0.0
self.data = [0.0] * len(self.data) # 将data重新赋值为包含相同数量0.0的列表
# 实现类似数组的取操作
def __getitem__(self, idx): # 通过索引idx可以获取累加器中相应位置的数据
return self.data[idx]
由于我们使用随机权重初始化net模型, 因此该模型的精度应接近于随机猜测。 例如在有10个类别情况下的精度为0.1

7、训练
1、一个函数来训练一个迭代周期。
2、dater是更新模型参数的常用函数,它接受批量大小作为参数。 它可以是d2l.sgd函数,也可以是框架的内置优化函数。
def train_epoch_ch3(net, train_iter, loss, updater): #@save
"""训练模型一个迭代周期(定义见第3章)"""
# 判断net模型是否为深度学习类型,将模型设置为训练模式
if isinstance(net, torch.nn.Module):
net.train() # 要计算梯度
# Accumulator(3)创建3个变量:训练损失总和、训练准确度总和、样本数
metric = Accumulator(3)
for X, y in train_iter:
# 计算梯度并更新参数
y_hat = net(X)
l = loss(y_hat, y)
# 判断updater是否为优化器
if isinstance(updater, torch.optim.Optimizer):
# 使用PyTorch内置的优化器和损失函数
updater.zero_grad() #把梯度设置为0
l.mean().backward() #计算梯度
updater.step() #自更新
else:
# 使用定制的优化器和损失函数
# 自我实现的话,l出来是向量,先求和再求梯度
l.sum().backward()
updater(X.shape[0])
metric.add(float(l.sum()), accuracy(y_hat, y), y.numel())
# 返回训练损失和训练精度,metric的值由Accumulator得到
return metric[0] / metric[2], metric[1] / metric[2]
定义一个在动画中绘制数据的实用程序类Animator
class Animator: #@save
"""在动画中绘制数据"""
def __init__(self, xlabel=None, ylabel=None, legend=None, xlim=None,
ylim=None, xscale='linear', yscale='linear',
fmts=('-', 'm--', 'g-.', 'r:'), nrows=1, ncols=1,
figsize=(3.5, 2.5)):
# 增量地绘制多条线
if legend is None:
legend = []
d2l.use_svg_display()
self.fig, self.axes = d2l.plt.subplots(nrows, ncols, figsize=figsize)
if nrows * ncols == 1:
self.axes = [self.axes, ]
# 使用lambda函数捕获参数
self.config_axes = lambda: d2l.set_axes(
self.axes[0], xlabel, ylabel, xlim, ylim, xscale, yscale, legend)
self.X, self.Y, self.fmts = None, None, fmts
def add(self, x, y):
# 向图表中添加多个数据点
if not hasattr(y, "__len__"):
y = [y]
n = len(y)
if not hasattr(x, "__len__"):
x = [x] * n
if not self.X:
self.X = [[] for _ in range(n)]
if not self.Y:
self.Y = [[] for _ in range(n)]
for i, (a, b) in enumerate(zip(x, y)):
if a is not None and b is not None:
self.X[i].append(a)
self.Y[i].append(b)
self.axes[0].cla()
for x, y, fmt in zip(self.X, self.Y, self.fmts):
self.axes[0].plot(x, y, fmt)
self.config_axes()
display.display(self.fig)
display.clear_output(wait=True)
3、一个训练函数,它会在train_iter访问到的训练数据集上训练一个模型net。
4、练函数将会运行多个迭代周期(由num_epochs指定)
| assert():断言函数,当表达式为真时,程序继续往下执行,只是判断,不做任何处理;当表达式为假时,抛出AssertionError错误,并将 [参数] 输出 |
def train_ch3(net, train_iter, test_iter, loss, num_epochs, updater): #@save
"""训练模型(定义见第3章)"""
animator = Animator(xlabel='epoch', xlim=[1, num_epochs], ylim=[0.3, 0.9],
legend=['train loss', 'train acc', 'test acc'])
# num_epochs:训练次数
for epoch in range(num_epochs):
# train_epoch_ch3:训练模型,返回准确率和错误度
train_metrics = train_epoch_ch3(net, train_iter, loss, updater)
# 在测试数据集上评估精度
test_acc = evaluate_accuracy(net, test_iter)
animator.add(epoch + 1, train_metrics + (test_acc,))
train_loss, train_acc = train_metrics
assert train_loss < 0.5, train_loss
assert train_acc <= 1 and train_acc > 0.7, train_acc
assert test_acc <= 1 and test_acc > 0.7, test_acc
5、小批量随机梯度下降来优化模型的损失函数,设置学习率为0.1
lr = 0.1
def updater(batch_size):
return d2l.sgd([W, b], lr, batch_size)
6、型10个迭代周期,其中迭代周期(num_epochs)和学习率(lr)都是可调节的超参数
num_epochs = 10
train_ch3(net, train_iter, test_iter, cross_entropy, num_epochs, updater)

8、预测
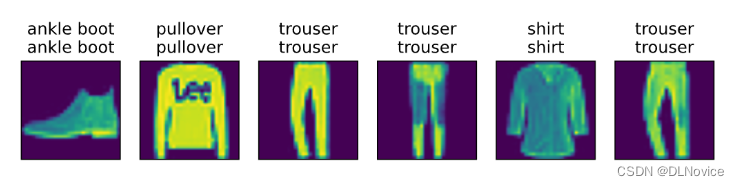
训练已完成的模型可以来对准备好图像进行分类预测,给定一系列图像,我们将比较它们的实际标签(文本输出的第一行)和模型预测(文本输出的第二行)
def predict_ch3(net, test_iter, n=6): #@save
"""预测标签(定义见第3章)"""
for X, y in test_iter:
break
trues = d2l.get_fashion_mnist_labels(y) # 实际标签
preds = d2l.get_fashion_mnist_labels(net(X).argmax(axis=1)) 预测标签,取最大化概率
titles = [true +'\n' + pred for true, pred in zip(trues, preds)]
d2l.show_images(
X[0:n].reshape((n, 28, 28)), 1, n, titles=titles[0:n])
predict_ch3(net, test_iter)

9、总结
softmax回归循环模型与训练线性回归模型非常相似:先读取数据,再定义模型和损失函数,然后使用优化算法训练模型。大多数常见的深度学习模型都有类似的训练过程
softmax简洁实现
1、导包
import torch
from torch import nn
from d2l import torch as d2l
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
2、初始化参数模型
# PyTorch不会隐式地调整输入的形状。因此,
# 我们在线性层前定义了展平层(flatten),来调整网络输入的形状
net = nn.Sequential(nn.Flatten(), nn.Linear(784, 10))
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, std=0.01)
net.apply(init_weights);
| ~ nn.Flatten() flatten是会把任意维度的Tensor变为一个2D的tensor,把第0维度保留,剩下的维度全部展成一个向量,对应前一个手动实现的reshape |
| ~Sequential: 是一个有序的容器,神经网络模块将按照在传入构造器的顺序依次被添加到计算图中执行,同时以神经网络模块为元素的有序字典也可以作为传入参数 |
| ~nn.init.normal_(m.weight,std=0.01) 把weight init 为均值为0(默认),方差为0.01的随机值 |
| ~net.apply(init_weights) 每一层apply一下init_weight的函数 |
3、重新审视Softmax的实现

如果Ok ,可能大于数据类型容许的最大数字(即上溢(overflow))。这将使分母或分子变为inf(无穷大),我们最后遇到的是0、inf或nan(不是数字)的y,不能得到一个明确定义的交叉熵的返回值
解决方法:我们没有将softmax概率传递到损失函数中,而是在交叉熵损失函数中传递未归一化的预测,并同时计算softmax及其对数
loss = nn.CrossEntropyLoss()
在这里,我们使用学习率为0.1的小批量随机梯度下降作为优化算法。 这与我们在线性回归例子中的相同,这说明了优化器的普适性
trainer = torch.optim.SGD(net.parameters(), lr=0.1)
| SGD:Stochastic Gradient Descent,随机梯度下降,是通过不断沿着反梯度方向更新参数求解,可以随机采样b个样本近似损失,每次随机选择一个mini-batch去计算梯度,在minibatch-loss上的梯度显然是original-loss上的梯度的无偏估计,因此利用minibatch-loss上的梯度可以近似original-loss上的梯度,并且每走一步只需要遍历一个minibatch(一~几百)的数据。 |
多层感知机
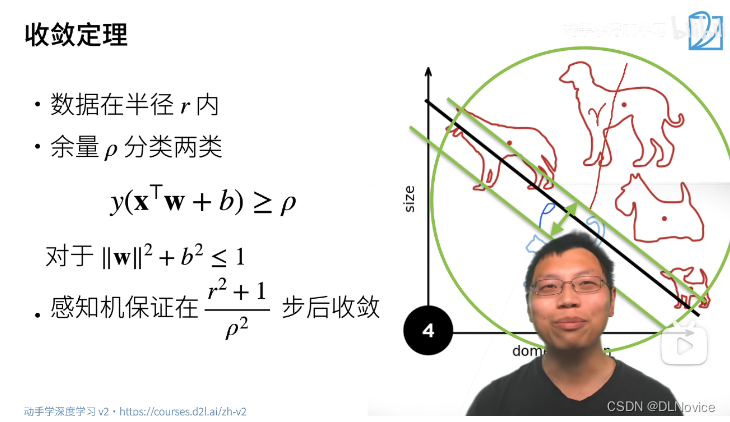
感知机
单层感知机:softmax,线性模型
多层感知机:非线性模型
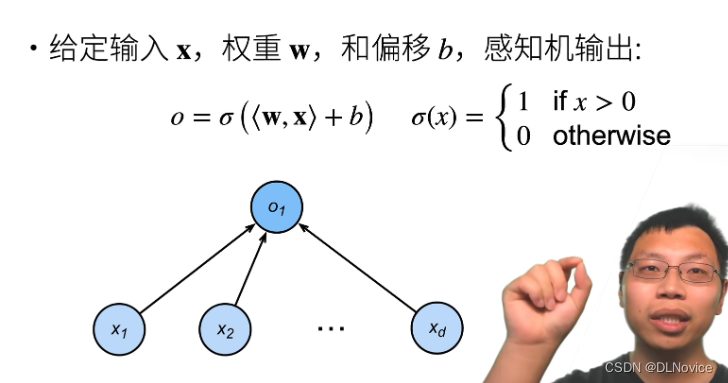
感知机就是二分类问题,上图所示函数中,输出也可以改为+1、-1

线性可分过程: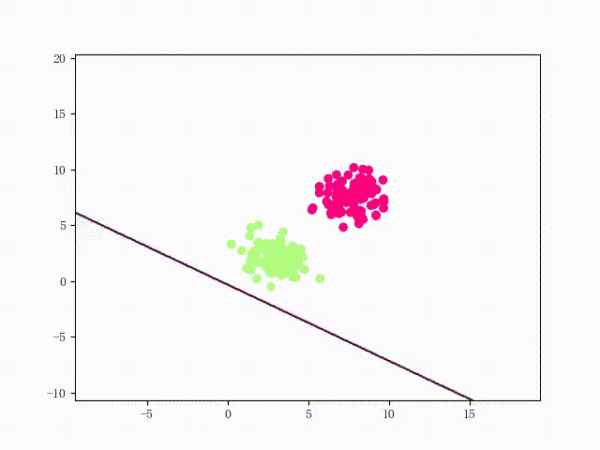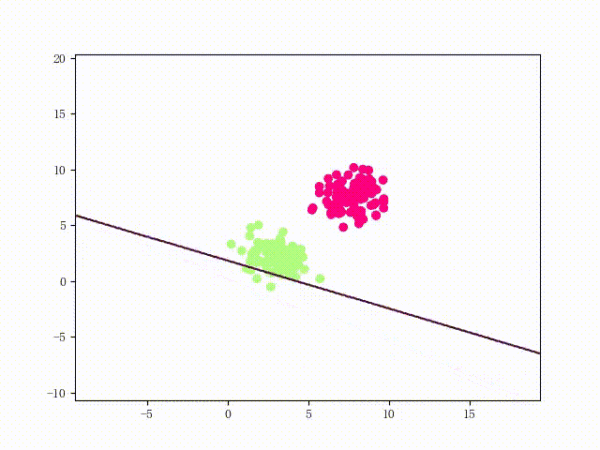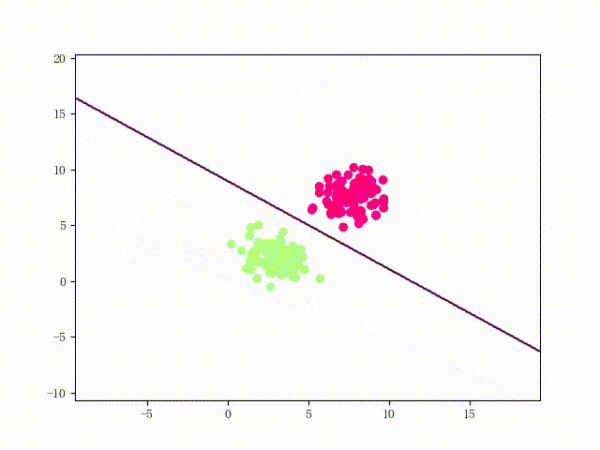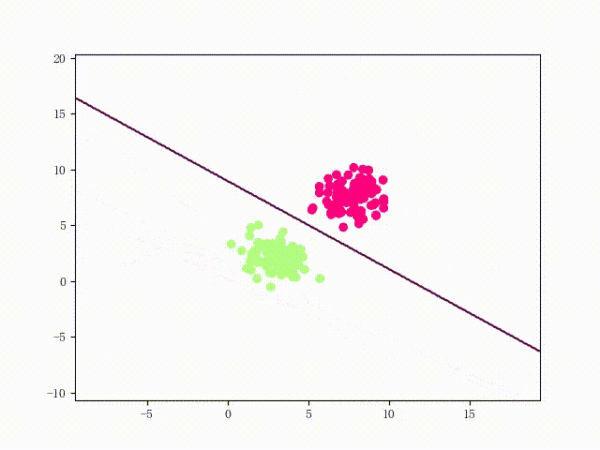
线性不可分的过程:
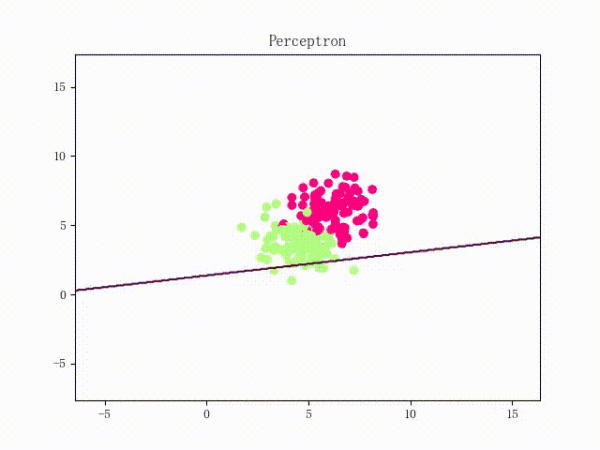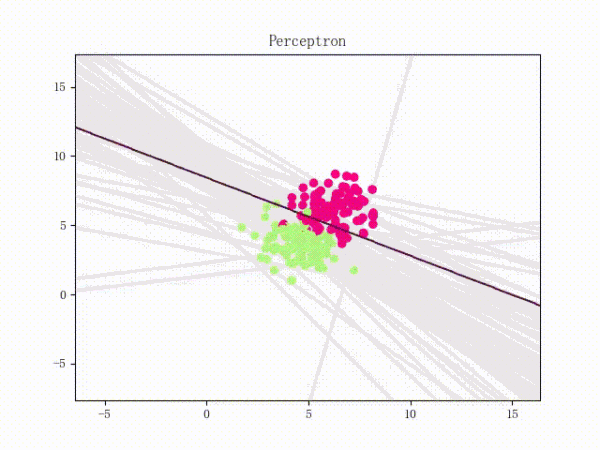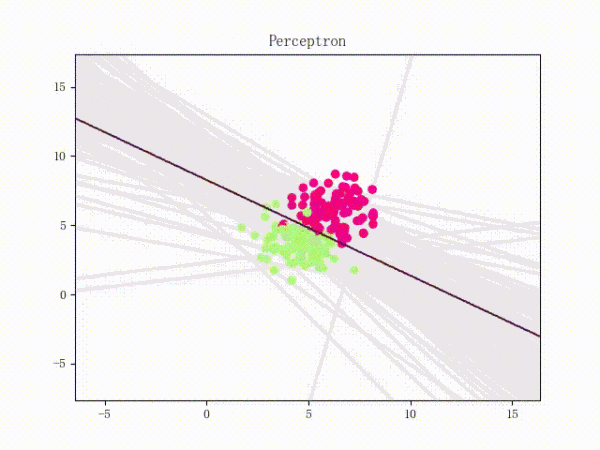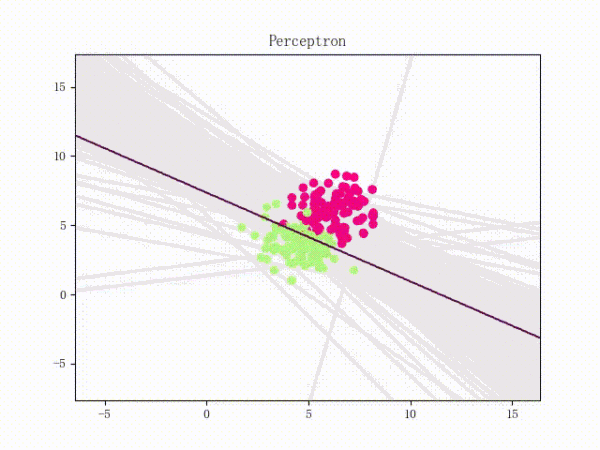
总结
- 感知机是一个二分类模型,是最早的AI模型之一
- 它的求解算法等价于使用批量大小为1的梯度下降
- 它不能拟合XOR函数,导致第一次AI寒冬
多层感知机
XOR(异或问题)
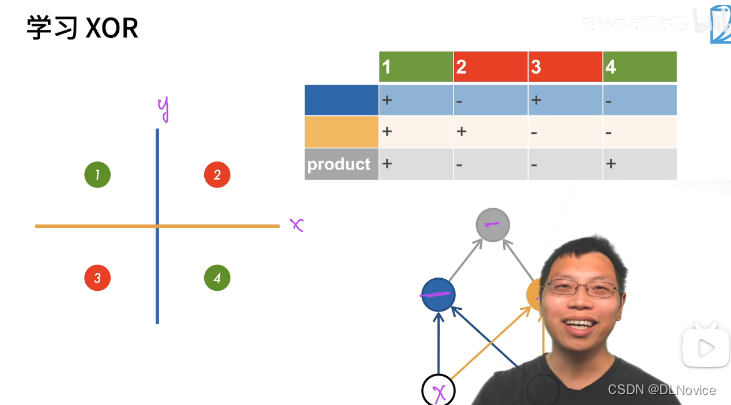
对于单层感知机,它只能表示由一条直线分割的空间,无法表示异或门
但我们可以用双层感知机来实现,单层感知机无法表示的东西,通过增加层数来实现。
反过来讲,通过叠加层,感知机能够表达更多更有意义的事情,例如:加法运算,进制转换,…。
隐藏层
对不完全线性问题还使用线性模式的一种补救措施
MLP(多层感知机)架构:
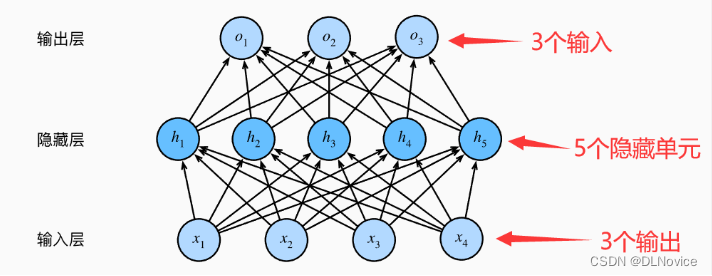
这是一个单隐藏层的多层感知机, 其中输入层不涉及任何计算,因此使用此网络产生输出只需要实现隐藏层和输出层的计算,因此我们说多层感知机的层数时,忽略输入层,如上图层数为2。注意,这两个层都是全连接的
激活函数
在神经元中,输入的 inputs 通过加权,求和后,还被作用了一个函数,这个函数就是激活函数。引入激活函数是为了增加神经网络模型的非线性。如果不用激活函数,每一层输出都是上层输入的线性函数,无论神经网络有多少层,输出都是输入的线性组合,这种情况就是最原始的感知机(Perceptron)。激活函数给神经元引入了非线性因素,使得神经网络可以任意逼近任何非线性函数,这样神经网络就可以应用到众多的非线性模型中。
激活函数(activation function)通过计算加权和并加上偏置来确定神经元是否应该被激活, 它们将输入信号转换为输出的可微运算。 大多数激活函数都是非线性的
常见的激活函数:
- ReLU:

import torch
from d2l import torch as d2l
import matplotlib.pyplot as plt
x= torch.arange(-8.0,8.0,0.1,requires_grad=True)
y= torch.relu(x)
plt.figure(figsize=(5, 2.5))
plt.plot(x.detach(), y.detach(), 'x')
plt.xlabel('x')
plt.ylabel('relu(x)')
plt.show()

ReLU的导数:
import torch
from d2l import torch as d2l
import matplotlib.pyplot as plt
x = torch.arange(-8.0, 8.0, 0.1, requires_grad=True)
y = torch.relu(x)
y.backward(torch.ones_like(x), retain_graph=True)
d2l.plot(x.detach(), x.grad, 'x', 'grad of relu', figsize=(5, 2.5))
plt.show()

ReLU的变体:pReLU

优缺点:
优:
-
ReLu的收敛速度比 sigmoid 和 tanh 快;
-
函数在x>0区域上,梯度不会饱和,解决了梯度消失问题;
-
计算复杂度低,不需要进行指数运算,只要一个阈值就可以得到激活值;
-
适合用于后向传播。
缺: -
ReLU的输出不是zero-centered(0均值);
-
Dead ReLU Problem(神经元坏死现象):在x<0时,梯度为0。这个神经元及之后的神经元梯度永远为0,不再对任何数据有所响应,导致相应参数永远不会被更新。。
-
产生这种现象的两个原因:1、参数初始化问题;2、learning rate太高导致在训练过程中参数更新太大。
-
解决方法:采用Xavier初始化方法,以及避免将learning rate设置太大或使用adagrad等自动调节learning rate的算法。
-
-
ReLU不会对数据做幅度压缩,所以数据的幅度会随着模型层数的增加不断扩张。
2.sigmoid:

-
对于一个在R上的输入,sigmoid函数将其变换为在[0,1]的输出
-
可以将sigmoid视为softmax的特例
-
当输入接近0时,sigmoid接近线性变换
import torch
from d2l import torch as d2l
import matplotlib.pyplot as plt
x = torch.arange(-8.0, 8.0, 0.1, requires_grad=True)
y = torch.sigmoid(x)
d2l.plot(x.detach(), y.detach(), 'x', 'sigmoid(x)', figsize=(5, 2.5))
plt.show()

sigmoid导数:

import torch
from d2l import torch as d2l
import matplotlib.pyplot as plt
x = torch.arange(-8.0, 8.0, 0.1, requires_grad=True)
y = torch.sigmoid(x)
# 初始化梯度为零张量
x.grad = torch.zeros_like(x)
# 清除以前的梯度
x.grad.zero_()
# 计算梯度
y.backward(torch.ones_like(x), retain_graph=True)
# 绘制梯度
d2l.plot(x.detach(), x.grad, 'x', 'grad of sigmoid', figsize=(5, 2.5))
plt.show()

优缺点:
优:
- 连续函数,便于求导的平滑函数;
- 能压缩数据,保证数据幅度不会有问题;
- 适合用于前向传播。
缺:
-
容易出现**梯度消失(gradient vanishing)**的现象:当激活函数接近饱和区时,变化太缓慢,导数接近0,根据后向传递的数学依据是微积分求导的链式法则,当前导数需要之前各层导数的乘积,几个比较小的数相乘,导数结果很接近0,从而无法完成深层网络的训练。
-
在反向传播时,当梯度接近于0,权重基本不会更新,很容易就会出现梯度消失的情况,从而无法完成深层网络的训练。
-
在反向传播时,当梯度接近于0,权重基本不会更新,很容易就会出现梯度消失的情况,从而无法完成深层网络的训练。
-
Sigmoid的输出不是0均值(zero-centered)的:这会导致后层的神经元的输入是非0均值的信号,这会对梯度产生影响。以 f=sigmoid(wx+b)为例, 假设输入均为正数(或负数),那么对w的导数总是正数(或负数),这样在反向传播过程中要么都往正方向更新,要么都往负方向更新,导致有一种捆绑效果,使得收敛缓慢。
-
计算复杂度高,因为sigmoid函数是指数形式。幂运算相对耗时
3.tanh:

y = torch.tanh(x)

代码同sigmoid
以上图像均类似sigmoid
总结
- 多层感知机使用隐藏层和激活函数来得到非线性模型
- 常用激活函数是Sigmoid,Tanh,ReLU
- 使用Softmax来处理多类分类
- 超参数为隐藏层数,和各个隐藏层大小
多层感知机的从0开始实现
import torch
from torch import nn
from d2l import torch as d2l
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
1、初始化模型参数
"""
参数含义:
1、每个图像视为具有784个输入特征;
2、10个类别;
3、我们将实现一个具有单隐藏层的多层感知机, 它包含256个隐藏单元。
"""
num_inputs, num_outputs, num_hiddens = 784, 10, 256
"""
对于每一层我们都要记录一个权重矩阵和一个偏置向量.
"""
W1 = nn.Parameter(torch.randn(
num_inputs, num_hiddens, requires_grad=True) * 0.01)
b1 = nn.Parameter(torch.zeros(num_hiddens, requires_grad=True))
W2 = nn.Parameter(torch.randn(
num_hiddens, num_outputs, requires_grad=True) * 0.01)
b2 = nn.Parameter(torch.zeros(num_outputs, requires_grad=True))
params = [W1, b1, W2, b2]
2、激活函数
def relu(X):
a = torch.zeros_like(X)
return torch.max(X, a)
3、模型
# 由于我们忽略了图像的空间结构,所以我们使用reshape将每个二维图像转换为一个长度为num_inputs的向量。
def net(X):
X = X.reshape((-1, num_inputs))
H = relu(X@W1 + b1) # 这里“@”代表矩阵乘法
return (H@W2 + b2)
4、损失函数
loss = nn.CrossEntropyLoss(reduction='none')
5、训练
num_epochs, lr = 10, 0.1
updater = torch.optim.SGD(params, lr=lr)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, updater)
这里可以看到,相比之前基于softmax实现对Fashion-MNIST数据集的训练,loss下降了,但acc几乎一致
6、评估
d2l.predict_ch3(net, test_iter)
多层感知机简洁实现
import torch
from torch import nn
from d2l import torch as d2l
1、模型
与softmax回归的简洁实现不同,唯一的区别是我们添加了2个全连接层(之前我们只添加了1个全连接层)。
第一层是隐藏层
它包含256个隐藏单元,并使用了ReLU激活函数。
第二层是输出层
net = nn.Sequential(nn.Flatten(),
nn.Linear(784, 256),
nn.ReLU(),
nn.Linear(256, 10))
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, std=0.01)
net.apply(init_weights)
2、训练
batch_size, lr, num_epochs = 256, 0.1, 10
loss = nn.CrossEntropyLoss(reduction='none')
trainer = torch.optim.SGD(net.parameters(), lr=lr)
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)

模型选择、欠拟合和过拟合
训练误差、泛化误差
- 训练误差(training error):模型在训练数据集上计算得到的误差
- 泛化误差(generalization error):模型应用在同样从原始样本的分布中抽取的无限多数据样本时,模型误差的期望
实际上我们永远不能准确地计算出泛化误差,因为我们没有无限多的数据样本
VC维
VC维的用处:
- 提供为什么一个模型好的理论依据
- 它可以衡量训练误差和泛化误差之间的隔阂
- 但深度学习中很少用
- 衡量不是很准确
- 计算深度学习模型的VC维很困难
模型复杂性
- 当我们有简单的模型和大量的数据时,我们期望泛化误差与训练误差相近。
- 当我们有更复杂的模型和更少的样本时,我们预计训练误差会下降,但泛化误差会增大。
模型复杂性由什么构成是一个复杂的问题。 一个模型是否能很好地泛化取决于很多因素
估计模型容量大小的关键:
- 参数个数
- 参数值的选择范围
重点介绍几个倾向于影响模型泛化的因素:
- 可调整参数的数量。当可调整参数的数量(有时称为自由度)很大时,模型往往更容易过拟合。
- 参数采用的值。当权重的取值范围较大时,模型可能更容易过拟合。
- 训练样本的数量。即使你的模型很简单,也很容易过拟合只包含一两个样本的数据集。而过拟合一个有数百万个样本的数据集则需要一个极其灵活的模型。
模型的选择
在机器学习中,我们通常在评估几个候选模型后选择最终的模型, 这个过程叫做模型选择。
例如,训练多层感知机模型时,我们可能希望比较具有 不同数量的隐藏层、不同数量的隐藏单元以及不同的激活函数组合的模型。 为了确定候选模型中的最佳模型,我们通常会使用验证集。
验证集
如果我们过拟合了测试数据,我们又该怎么知道呢?
解决此问题的常见做法是将我们的数据分成三份:训练集、测试集、验证集(validation dataset)
-
K折交叉验证
当训练数据稀缺时,我们甚至可能无法提供足够的数据来构成一个合适的验证集。 这个问题的一个流行的解决方案是采用K折交叉验证。
- 原始训练数据被分成K个不重叠的子集
- 执行K次模型训练和验证,每次在K−1个子集上进行训练
- 在剩余的一个子集(在该轮中没有用于训练的子集)上进行验证
- 通过对K次实验的结果取平均来估计训练和验证误差
欠拟合、过拟合
- 训练误差和验证误差都很严重, 但它们之间仅有一点差距。
如果模型不能降低训练误差,这可能意味着模型过于简单(即表达能力不足), 无法捕获试图学习的模式。 此外,由于我们的训练和验证误差之间的泛化误差很小, 我们有理由相信可以用一个更复杂的模型降低训练误差。 这种现象被称为欠拟合(underfitting) - 训练误差明显低于验证误差时要小心, 这表明严重的过拟合(overfitting)
注意,过拟合并不总是一件坏事。
是否过拟合或欠拟合可能取决于模型复杂性和可用训练数据集的大小- 模型复杂性:训练集固定,越复杂(VC维越高)训练误差越低
- 训练数据集:训练数据集中的样本越少,我们就越有可能(且更严重地)过拟合。 随着训练数据量的增加,泛化误差通常会减小。
多项回归
import math
import numpy as np
import torch
from torch import nn
from d2l import torch as d2l
生成数据集
max_degree = 20 # 多项式的最大阶数
n_train, n_test = 100, 100 # 训练和测试数据集大小
true_w = np.zeros(max_degree) # 创建一个长度为 max_degree 的 NumPy 数组,所有元素初始化为 0,用于存储多项式的真实权重
true_w[0:4] = np.array([5, 1.2, -3.4, 5.6])#将前四个元素分别设置为 5、1.2、-3.4 和 5.6,这些是多项式的真实权重
features = np.random.normal(size=(n_train + n_test, 1))# 生成一个大小为 (n_train + n_test, 1) 的服从标准正态分布的随机数数组,用作特征
np.random.shuffle(features)#随机打乱特征数组,以确保样本的随机性
poly_features = np.power(features, np.arange(max_degree).reshape(1, -1))
for i in range(max_degree):
poly_features[:, i] /= math.gamma(i + 1) # 使用 math.gamma 函数对多项式特征进行归一化处理,防止高次幂造成的数值爆炸。gamma 函数的作用是计算阶乘的值,这里用于归一化,避免数值过大
labels = np.dot(poly_features, true_w)# 根据多项式特征和真实权重计算标签值。这里采用了矩阵乘法
labels += np.random.normal(scale=0.1, size=labels.shape)#给标签添加服从标准正态分布的随机噪声,以模拟真实世界中的数据
# NumPy ndarray 转换为 tensor
true_w, features, poly_features, labels = [torch.tensor(x, dtype=torch.float32) for x in [true_w, features, poly_features, labels]]
print(features[:2], poly_features[:2, :], labels[:2])# 打印出前两个样本的特征、多项式特征和标签,以便查看生成的数据

对模型进行训练和测试
- 定义一个函数评估模型在给定数据集上的损失
def evaluate_loss(net, data_iter, loss): #@save
"""评估给定数据集上模型的损失"""
metric = d2l.Accumulator(2) # 损失的总和,样本数量
for X, y in data_iter:
out = net(X)
y = y.reshape(out.shape)
l = loss(out, y)
metric.add(l.sum(), l.numel())
return metric[0] / metric[1]
- 定义训练函数
def train(train_features, test_features, train_labels, test_labels,
num_epochs=400):
loss = nn.MSELoss(reduction='none')
input_shape = train_features.shape[-1]
# 不设置偏置,因为我们已经在多项式中实现了它
net = nn.Sequential(nn.Linear(input_shape, 1, bias=False))
batch_size = min(10, train_labels.shape[0])
train_iter = d2l.load_array((train_features, train_labels.reshape(-1,1)),
batch_size)
test_iter = d2l.load_array((test_features, test_labels.reshape(-1,1)),
batch_size, is_train=False)
trainer = torch.optim.SGD(net.parameters(), lr=0.01)
animator = d2l.Animator(xlabel='epoch', ylabel='loss', yscale='log',
xlim=[1, num_epochs], ylim=[1e-3, 1e2],
legend=['train', 'test'])
for epoch in range(num_epochs):
d2l.train_epoch_ch3(net, train_iter, loss, trainer)
if epoch == 0 or (epoch + 1) % 20 == 0:
animator.add(epoch + 1, (evaluate_loss(net, train_iter, loss),
evaluate_loss(net, test_iter, loss)))
print('weight:', net[0].weight.data.numpy())
- 三阶多项式函数拟合(正常):我们将首先使用三阶多项式函数,它与数据生成函数的阶数相同。 结果表明,该模型能有效降低训练损失和测试损失。 学习到的模型参数也接近真实值w=[5,1.2,−3.4,5.6]。
# 从多项式特征中选择前4个维度,即1,x,x^2/2!,x^3/3!
train(poly_features[:n_train, :4], poly_features[n_train:, :4],
labels[:n_train], labels[n_train:])

- 线性函数拟合(欠拟合):从下图可以看出减少该模型的训练损失相对困难。 在最后一个迭代周期完成后,训练损失仍然很高。 当用来拟合非线性模式(如这里的三阶多项式函数)时,线性模型容易欠拟合。
# 从多项式特征中选择前2个维度,即1和x
train(poly_features[:n_train, :2], poly_features[n_train:, :2],
labels[:n_train], labels[n_train:])

- 高阶多项式函数拟合(过拟合):结果表明,复杂模型对数据造成了过拟合
# 从多项式特征中选取所有维度
train(poly_features[:n_train, :], poly_features[n_train:, :],
labels[:n_train], labels[n_train:], num_epochs=1500)

权重衰减
均方范数

损失函数L(w,b):w权重,b偏置 限制

=0(无限趋近)可以控制w的大小
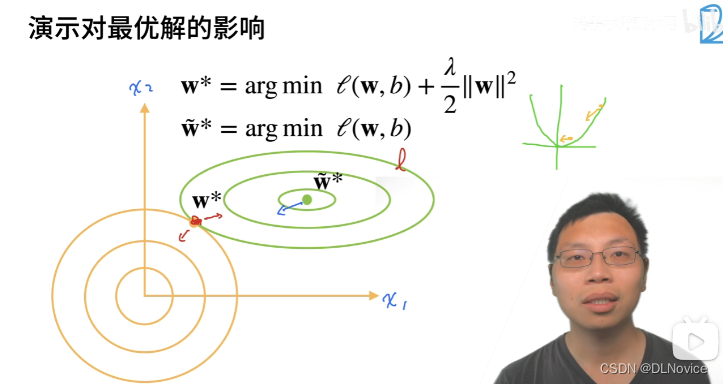
w*:平衡点损失函数L减小和增加刚好平衡,
:原始数据最优点(以二次项为例,在原点处坡度最缓,损失最小)
x1,x2:描述w的值,黄色圈圈代表(损失项)
参数更新法则

- 权重衰退通过L2正则项使得模型参数不会过大,从而控制模型复杂度
- 正则项权重是控制模型复杂度的超参数
代码实现
import matplotlib.pyplot as plt
import torch
from torch import nn#这行代码从PyTorch库中导入了nn模块,该模块包含了神经网络的各种组件,例如各种层和损失函数等
from d2l import torch as d2l

为了使过拟合效果更加明显,我们将问题的维度增加到d=200,并且使用一个只包含20个样本的小训练集
n_train, n_test, num_inputs, batch_size = 20, 100, 200, 5# n_train和n_test分别表示训练集和测试集的样本数量,num_inputs表示输入特征的数量,batch_size表示每个小批次中的样本数量
true_w, true_b = torch.ones((num_inputs, 1)) * 0.01, 0.05# 权重是一个形状为(num_inputs, 1)的张量,所有元素均为0.01,而偏置为0.05
train_data = d2l.synthetic_data(true_w, true_b, n_train)# synthetic_data函数生成了一个训练数据集
train_iter = d2l.load_array(train_data, batch_size)# 这行代码将训练数据集加载到一个名为train_iter的迭代器中,以便后续的训练过程中能够按批次迭代训练数据
test_data = d2l.synthetic_data(true_w, true_b, n_test)# 这行代码生成了一个测试数据集,与训练数据集的生成方式相同
test_iter = d2l.load_array(test_data, batch_size, is_train=False)
初始化模型参数
# 定义了一个名为init_params的函数,用于初始化模型参数。该函数返回一个包含权重和偏置的列表
def init_params():
w = torch.normal(0, 1, size=(num_inputs, 1), requires_grad=True)
b = torch.zeros(1, requires_grad=True)
return [w, b]
定义L2范数惩罚
实现这一惩罚最方便的方法是对所有项求平方后并将它们求和。
# 定义了一个名为l2_penalty的函数,用于计算L2范数正则化项
def l2_penalty(w):
return torch.sum(w.pow(2)) / 2
训练代码
# 定义了一个名为train的函数,用于执行模型的训练过程。它接受一个参数lambd,表示L2范数正则化的系数
def train(lambd):
w, b = init_params()
net, loss = lambda X: d2l.linreg(X, w, b), d2l.squared_loss # 这行代码定义了模型net和损失函数loss。net是一个使用线性回归函数d2l.linreg定义的lambda函数,而loss是一个平方损失函数d2l.squared_loss
num_epochs, lr = 100, 0.003# 这行代码定义了训练的轮数和学习率
animator = d2l.Animator(xlabel='epochs', ylabel='loss', yscale='log',
xlim=[5, num_epochs], legend=['train', 'test'])# 这行代码创建了一个动画实例,用于可视化训练过程中的损失值
for epoch in range(num_epochs):
for X, y in train_iter:# 遍历训练数据集中的小批量数据
# Add L2 norm penalty
# Broadcasting makes l2_penalty(w) a vector of length batch_size
l = loss(net(X), y) + lambd * l2_penalty(w) # 这行代码计算了模型预测值与真实标签的损失,并加上了L2范数正则化项
l.sum().backward() # 这行代码执行反向传播计算梯度
d2l.sgd([w, b], lr, batch_size) # 这行代码使用随机梯度下降算法更新模型参数
if (epoch + 1) % 5 == 0: #这行代码每隔5个epoch记录一次损失值
animator.add(epoch + 1, (d2l.evaluate_loss(net, train_iter, loss),
d2l.evaluate_loss(net, test_iter, loss)))
print('w的L2范数是:', torch.norm(w).item())
plt.show() # Show plot after adding data
# 用lambd = 0禁用权重衰减
train(lambd=0) # 这行代码调用了train函数,并传入了L2范数正则化的系数lambd为0,即不进行正则化 训练误差有了减少,但测试误差没有减少, 这意味着出现了严重的过拟合
train(lambd=3) # 我们使用权重衰减来运行代码。 注意,在这里训练误差增大,但测试误差减小。 这正是我们期望从正则化中得到的效果。
简洁代码实现
将上面训练代码更改如下:
def train_concise(wd):
net = nn.Sequential(nn.Linear(num_inputs, 1))
for param in net.parameters():
param.data.normal_()
loss = nn.MSELoss(reduction='none')
num_epochs, lr = 100, 0.003
# 偏置参数没有衰减
trainer = torch.optim.SGD([
{"params":net[0].weight,'weight_decay': wd},
{"params":net[0].bias}], lr=lr)
animator = d2l.Animator(xlabel='epochs', ylabel='loss', yscale='log',
xlim=[5, num_epochs], legend=['train', 'test'])
for epoch in range(num_epochs):
for X, y in train_iter:
trainer.zero_grad()
l = loss(net(X), y)
l.mean().backward()
trainer.step()
if (epoch + 1) % 5 == 0:
animator.add(epoch + 1,
(d2l.evaluate_loss(net, train_iter, loss),
d2l.evaluate_loss(net, test_iter, loss)))
print('w的L2范数:', net[0].weight.norm().item())
我们在实例化优化器时直接通过weight_decay指定weight decay超参数。 默认情况下,PyTorch同时衰减权重和偏移。 这里我们只为权重设置了weight_decay,所以偏置参数b不会衰减。
train_concise(0)
train_concise(3)
展示效果同上
小结
- 正则化是处理过拟合的常用方法:在训练集的损失函数中加入惩罚项,以降低学习到的模型的复杂度。
- 保持模型简单的一个特别的选择是使用L2惩罚的权重衰减。这会导致学习算法更新步骤中的权重衰减。
- 权重衰减功能在深度学习框架的优化器中提供。
- 在同一训练代码实现中,不同的参数集可以有不同的更新行为。
丢弃法




总结
- Dropout奖一些输出项随机置0来控制模型复杂度
- 常作用在多层感知机的隐藏层输出上
- 丢弃概率是控制模型复杂度的超参数
代码实现
要实现单层的暂退法函数, 我们从均匀分布U[0,1]中抽取样本,样本数与这层神经网络的维度一致。 然后我们保留那些对应样本大于p的节点,把剩下的丢弃。
在下面的代码中,我们实现 dropout_layer 函数, 该函数以dropout的概率丢弃张量输入X中的元素, 如上所述重新缩放剩余部分:将剩余部分除以1.0-dropout
import torch
from torch import nn
from d2l import torch as d2l
def dropout_layer(X, dropout):
assert 0 <= dropout <= 1
# 在本情况中,所有元素都被丢弃
if dropout == 1:
return torch.zeros_like(X)
# 在本情况中,所有元素都被保留
if dropout == 0:
return X
mask = (torch.rand(X.shape) > dropout).float()
return mask * X / (1.0 - dropout)
我们可以通过下面几个例子来测试dropout_layer函数。 我们将输入X通过暂退法操作,暂退概率分别为0、0.5和1
X= torch.arange(16, dtype = torch.float32).reshape((2, 8))
print(X)
print(dropout_layer(X, 0.))
print(dropout_layer(X, 0.5))
print(dropout_layer(X, 1.))
定义具有两个隐藏层的多层感知机,每个隐藏层包含256个单元
num_inputs, num_outputs, num_hiddens1, num_hiddens2 = 784, 10, 256, 256
我们可以将暂退法应用于每个隐藏层的输出(在激活函数之后), 并且可以为每一层分别设置暂退概率: 常见的技巧是在靠近输入层的地方设置较低的暂退概率。
- 下面的模型将第一个和第二个隐藏层的暂退概率分别设置为0.2和0.5, 并且暂退法只在训练期间有效。
dropout1, dropout2 = 0.2, 0.5
class Net(nn.Module):
def __init__(self, num_inputs, num_outputs, num_hiddens1, num_hiddens2,
is_training = True):
super(Net, self).__init__()
self.num_inputs = num_inputs
self.training = is_training
self.lin1 = nn.Linear(num_inputs, num_hiddens1)
self.lin2 = nn.Linear(num_hiddens1, num_hiddens2)
self.lin3 = nn.Linear(num_hiddens2, num_outputs)
self.relu = nn.ReLU()
def forward(self, X):
H1 = self.relu(self.lin1(X.reshape((-1, self.num_inputs))))
# 只有在训练模型时才使用dropout
if self.training == True:
# 在第一个全连接层之后添加一个dropout层
H1 = dropout_layer(H1, dropout1)
H2 = self.relu(self.lin2(H1))
if self.training == True:
# 在第二个全连接层之后添加一个dropout层
H2 = dropout_layer(H2, dropout2)
out = self.lin3(H2)
return out
net = Net(num_inputs, num_outputs, num_hiddens1, num_hiddens2)
训练和测试
num_epochs, lr, batch_size = 10, 0.5, 256
loss = nn.CrossEntropyLoss(reduction='none')
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
trainer = torch.optim.SGD(net.parameters(), lr=lr)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)

简洁实现
对于深度学习框架的高级API,我们只需在每个全连接层之后添加一个Dropout层, 将暂退概率作为唯一的参数传递给它的构造函数。
- 在训练时,
Dropout层将根据指定的暂退概率随机丢弃上一层的输出(相当于下一层的输入)。 - 在测试时,
Dropout层仅传递数据
net = nn.Sequential(nn.Flatten(),
nn.Linear(784, 256),
nn.ReLU(),
# 在第一个全连接层之后添加一个dropout层
nn.Dropout(dropout1),
nn.Linear(256, 256),
nn.ReLU(),
# 在第二个全连接层之后添加一个dropout层
nn.Dropout(dropout2),
nn.Linear(256, 10))
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, std=0.01)
net.apply(init_weights);
训练和测试
trainer = torch.optim.SGD(net.parameters(), lr=lr)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)
总结
- 暂退法在前向传播过程中,计算每一内部层的同时丢弃一些神经元。
- 暂退法可以避免过拟合,它通常与控制权重向量的维数和大小结合使用的。
- 暂退法将活性值h替换为具有期望值h的随机变量。
- 暂退法仅在训练期间使用

















 1694
1694

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









