






1.innodb和myisam区别
1、innodb支持事务,而myisam不支持事务。
2、innodb支持外键,而myisam不支持外键。
3、innodb默认表锁,使用索引检索条件时是行锁,而myisam是表锁(每次更新增加删除都会锁住表)。
4、innodb和myisam的索引都是基于b+树,但他们具体实现不一样,innodb的b+树的叶子节点是存放数据的,myisam的b+树的叶子节点是存放指针的。
5、innodb是聚簇索引,必须要有主键,一定会基于主键查询,但是辅助索引就会查询两次,myisam是非聚簇索引,索引和数据是分离的,索引里保存的是数据地址的指针,主键索引和辅助索引是分开的。
6、innodb不存储表的行数,所以select count( * )的时候会全表查询,而myisam会存放表的行数,select count(*)的时候会查的很快。
总结:mysql默认使用innodb,如果要用事务和外键就使用innodb,如果这张表只用来查询,可以用myisam。如果更新删除增加频繁就使用innodb。
2.快排过程,时间复杂度,最好最坏情况
分治 找中点 O(nlogn)~O(n2) 最好 每次都取一半 最坏 中点每次都取到最大或者最小值
空间O(nlogn)
3.归排过程,时间复杂度
O(nlogn),空间O(1)
4.top k
堆/快排一半(减治)
5.索引结构,为什么检索快
B+tree上层节点保存索引,叶子节点保存data,查询自顶向下;如果没有索引就要遍历链表
6.笔试时候的算法题和选择题过一遍
环形链表
dp股票最大最小 lc122
循环链表
最大连续乘积
子网掩码算广播地址:
先把IP地址转换成二进制,然后与二进制的子网掩码进行与运算,得到的就是网络地址。
网络地址末尾0串改1串是广播地址;

平衡二叉查找树:
sql修改表结构:ALTER TABLE
二叉树前中后序遍历
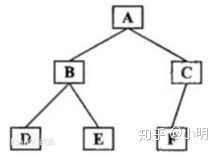
前序遍历结果:ABDECF
注意:已知后序遍历和中序遍历,就能确定前序遍历。
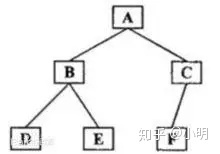
中序遍历结果:DBEAFC
注:二叉搜索树题目一般和中序遍历相关。
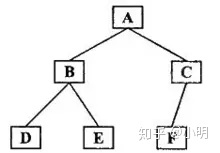
后序遍历结果:DEBFCA
已知前序遍历和中序遍历,就能确定后序遍历。
进程间通信方式
管道pipe:管道是一种半双工的通信方式,数据只能单向流动,而且只能在具有亲缘关系的进程间使用。进程的亲缘关系通常是指父子进程关系。
命名管道FIFO:有名管道也是半双工的通信方式,但是它允许无亲缘关系进程间的通信。
消息队列MessageQueue:消息队列是由消息的链表,存放在内核中并由消息队列标识符标识。消息队列克服了信号传递信息少、管道只能承载无格式字节流以及缓冲区大小受限等缺点。
共享内存SharedMemory:共享内存就是拿出一块虚拟地址空间,映射到相同的物理内存中,这段共享内存由一个进程创建,但多个进程都可以访问。共享内存是最快的进程间通信方式,它是针对其他进程间通信方式运行效率低而专门设计的。它往往与其他通信机制,如信号量,配合使用,来实现进程间的同步和通信。
信号量Semaphore:信号量是一个计数器,用于实现进程间的互斥与同步,可以用来控制多个进程对共享资源的访问。它常作为一种锁机制,防止某进程正在访问共享资源时,其他进程也访问该资源。因此,主要作为进程间以及同一进程内不同线程之间的同步手段。有两种操作:P(信号量-1)和V(信号量+1)
信号 ( sinal ) : 对于异常情况下的工作模式,需要信号来通知进程。硬件来源:如键盘ctrl c;软件来源:如 kill命令。
套接字Socket:套解口也是一种进程间通信机制,与其他通信机制不同的是,它可用于跨网络不同主机间的进程通信。
死锁产生原因与解决办法
所谓死锁,是指多个进程在运行过程中因争夺资源而造成的一种僵局,当进程处于这种僵持状态时,若无外力作用,它们都将无法再向前推进。
产生死锁的必要条件:
互斥条件:进程要求对所分配的资源进行排它性控制,即在一段时间内某资源仅为一进程所占用。
占有且等待条件:当进程因请求资源而阻塞时,对已获得的资源保持不放。
不可剥夺条件:进程已获得的资源在未使用完之前,不能剥夺,只能在使用完时由自己释放。
环路等待条件:在发生死锁时,必然存在一个进程--资源的环形链。
当发现有进程死锁后,便应立即把它从死锁状态中解脱出来,常采用的方法有:
剥夺资源:从其它进程剥夺足够数量的资源给死锁进程,以解除死锁状态;
撤消进程:可以直接撤消死锁进程或撤消代价最小的进程,直至有足够的资源可用,死锁状态消除为止;所谓代价是指优先级、运行代价、进程的重要性和价值等。
7.二十个球一个较轻用天平至少称3次能保证找出这个较轻的球。
分成三组,7,7,6,称7和7找到最轻的一个,如果相等,那么轻的在6;
如果在7中,分成2,2,3,秤2和2,找轻的;或秤3时:1,1,1,秤1和1找最轻的
如果在6中,分成2,2,2,秤2和2,最多秤两次,最少秤一次,就找了在哪个2中,然后秤1和1,找到。
8.进程线程区别
地址空间:
线程共享本进程的地址空间,而进程之间是独立的地址空间。
资源:
线程共享本进程的资源如内存、I/O、cpu等,不利于资源的管理和保护,而进程之间的资源是独立的,能很好的进行资源管理和保护。
健壮性:
多进程要比多线程健壮,一个进程崩溃后,在保护模式下不会对其他进程产生影响,但是一个线程崩溃整个进程都死掉。
执行过程:
每个独立的进程有一个程序运行的入口、顺序执行序列和程序入口,执行开销大。
但是线程不能独立执行,必须依存在应用程序中,由应用程序提供多个线程执行控制,执行开销小。
可并发性:
两者均可并发执行。
切换时:
进程切换时,消耗的资源大,效率高。所以涉及到频繁的切换时,使用线程要好于进程。同样如果要求同时进行并且又要共享某些变量的并发操作,只能用线程不能用进程。
其他:
线程是处理器调度的基本单位,但是进程不是。
10.TCP三次握手
第一次握手:建立连接时,客户端发送syn包(syn=x)到服务器,并进入SYN_SENT状态,等待服务器确认;SYN:同步序列编号(Synchronize Sequence Numbers)。
第二次握手:服务器收到syn包,必须确认客户的SYN(ack=x+1),同时自己也发送一个SYN包(syn=y),即SYN+ACK包,此时服务器进入SYN_RECV状态;
第三次握手:客户端收到服务器的SYN+ACK包,向服务器发送确认包ACK(ack=y+1),此包发送完毕,客户端和服务器进入ESTABLISHED(TCP连接成功)状态,完成三次握手。
四次挥手
1)客户端进程发出连接释放报文,并且停止发送数据。释放数据报文首部,FIN=1,其序列号为seq=u(等于前面已经传送过来的数据的最后一个字节的序号加1),此时,客户端进入FIN-WAIT-1(终止等待1)状态。 TCP规定,FIN报文段即使不携带数据,也要消耗一个序号。
2)服务器收到连接释放报文,发出确认报文,ACK=1,ack=u+1,并且带上自己的序列号seq=v,此时,服务端就进入了CLOSE-WAIT(关闭等待)状态。TCP服务器通知高层的应用进程,客户端向服务器的方向就释放了,这时候处于半关闭状态,即客户端已经没有数据要发送了,但是服务器若发送数据,客户端依然要接受。这个状态还要持续一段时间,也就是整个CLOSE-WAIT状态持续的时间。
3)客户端收到服务器的确认请求后,此时,客户端就进入FIN-WAIT-2(终止等待2)状态,等待服务器发送连接释放报文(在这之前还需要接受服务器发送的最后的数据)。
4)服务器将最后的数据发送完毕后,就向客户端发送连接释放报文,FIN=1,ack=u+1,由于在半关闭状态,服务器很可能又发送了一些数据,假定此时的序列号为seq=w,此时,服务器就进入了LAST-ACK(最后确认)状态,等待客户端的确认。
5)客户端收到服务器的连接释放报文后,必须发出确认,ACK=1,ack=w+1,而自己的序列号是seq=u+1,此时,客户端就进入了TIME-WAIT(时间等待)状态。注意此时TCP连接还没有释放,必须经过2∗MSL(最长报文段寿命)的时间后,才进入CLOSED状态。
6)服务器只要收到了客户端发出的确认,立即进入CLOSED状态。同样,撤销TCB后,就结束了这次的TCP连接。可以看到,服务器结束TCP连接的时间要比客户端早一些。
11.140g盐,一天平,7g 、2g砝码各一个,如何只利用这些东西3次把盐分成50g和90g?
(1)用7g+2g的砝码称出9g盐,140g-9g=131g
(2)用7g+2g砝码把131g盐分成两部分61g,70g (61+2+7=70)
(3)用2g砝码和9g盐把61g盐分成50g和11g两部分(61-9-2=11,11+50=61).11g+9g+70g=90g
12.登陆方式加密方法:密码 hash加密
13.tcp udp 区别
TCP:面向连接,一对一,可靠交付,拥塞控制,流量控制,首部开销大,字节流传输,没有边界,保证顺序和可靠,大于MSS在传输层分片
UDP:即时传输,一对多,多对多,尽最大努力交付,首部固定8字节,按包发送,可能丢包活乱序,大于MTU在IP层分片
14.http tcp在哪一层(应用层,传输层)
15.session token cookie
session 即会话,是一种持久网络协议,起到了在用户端和服务器端创建关联,从而交换数据包的作用。
cookie 是“小型文本文件”,是某些网站为了辨别用户身份,进行 session 跟踪而储存在用户本地终端上的数据(通常经过加密),由用户客户端计算机暂时或永久保存的信息。
token 在计算机身份认证中是令牌(临时)的意思,在词法分析中是标记的意思。一般作为邀请、登录系统使用。
16.事务四大特性ACID
ACID
ACID,指数据库事务正确执行的四个基本要素的缩写。包含:原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability)。一个支持事务(Transaction)的数据库,必须要具有这四种特性,否则在事务过程(Transaction processing)当中无法保证数据的正确性,交易过程极可能达不到交易方的要求。
原子性(Atomicity)
原子性是指事务是一个不可分割的工作单位,事务中的操作要么都发生,要么都不发生。 通过undo log回滚日志保证
一致性(Consistency)
事务前后数据的完整性必须保持一致。通过原子 隔离和持久保证。
隔离性(Isolation)
事务的隔离性是多个用户并发访问数据库时,数据库为每一个用户开启的事务,不能被其他事务的操作数据所干扰,多个并发事务之间要相互隔离。 通过MVCC多版本并发控制或者锁机制来保证
持久性(Durability)
持久性是指一个事务一旦被提交,它对数据库中数据的改变就是永久性的,接下来即使数据库发生故障也不应该对其有任何影响。 靠innodb的redo log file重做日志文件实现
具有ACID的特性的数据库支持强一致性,强一致性代表数据库本身不会出现不一致,每个事务是原子的,或者成功或者失败,事物间是隔离的,互相完全不影响,而且最终状态是持久落盘的,因此,数据库会从一个明确的状态到另外一个明确的状态,中间的临时状态是不会出现的,如果出现也会及时的自动的修复,因此是强一致的。
17.http https区别
HTTP 是超⽂本传输协议,信息是明⽂传输,存在安全⻛险的问题。HTTPS 则解决 HTTP 不安全的缺陷,在TCP 和 HTTP ⽹络层之间加⼊了 SSL/TLS 安全协议,使得报⽂能够加密传输。
HTTP 连接建⽴相对简单, TCP 三次握⼿之后便可进⾏ HTTP 的报⽂传输。⽽ HTTPS 在 TCP 三次握⼿之后,还需进⾏ SSL/TLS 的握⼿过程,才可进⼊加密报⽂传输。
HTTP 的端⼝号是 80,HTTPS 的端⼝号是 443。
HTTPS 协议需要向 CA(证书权威机构)申请数字证书,来保证服务器的身份是可信的。
HTTP 由于是明⽂传输,所以安全上存在以下三个⻛险:
窃听⻛险,⽐如通信链路上可以获取通信内容,⽤户号容易没。 篡改⻛险,⽐如强制植⼊垃圾⼴告,视觉污染,⽤户眼容易瞎。 冒充⻛险,⽐如冒充淘宝⽹站,⽤户钱容易没。
HTTPS 在 HTTP 与 TCP 层之间加⼊了 SSL/TLS 协议,可以很好的解决了上述的⻛险:
信息加密:交互信息⽆法被窃取,但你的号会因为「⾃身忘记」账号⽽没。 校验机制:⽆法篡改通信内容,篡改了就不能正常显示,但百度「竞价排名」依然可以搜索垃圾⼴告。 身份证书:证明淘宝是真的淘宝⽹,但你的钱还是会因为「剁⼿」⽽没。
混合加密的⽅式实现信息的机密性,解决了窃听的⻛险。 摘要算法的⽅式来实现完整性,它能够为数据⽣成独⼀⽆⼆的「指纹」,指纹⽤于校验数据的完整性,解决了 篡改的⻛险。 将服务器公钥放⼊到数字证书中,解决了冒充的⻛险。
18.https通信过程
19.tcp滑动窗口 收缩扩大
20.键入网址到浏览器显示全过程
- DNS 解析:将域名解析成 IP 地址
- TCP 连接:TCP 三次握手
- 发送 HTTP 请求
- 服务器处理请求并返回 HTTP 报文
- 浏览器解析渲染页面
- 断开连接:TCP 四次挥手
21.说一下static关键字的作用
全局静态变量
在全局变量前加上关键字 static,全局变量就定义成一个全局静态变量静态存储区,在整个程序运行期间一直初始化:未经初始化的全局静态变量会被自动初始化为0(自动对象的值是任意的,除非他被显式初始化)
作用域:全局静态变量在声明他的文件之外是不可见的,准确地说是从定义之处开始,到文件结尾static修饰的变量是可以被修改的,static const修饰的变量是不可以被修改的
局部静态变量
在局部变量之前加上关键字 static,局部变量就成为一个局部静态变量。
内存中的位置:静态存储区初始化:末经初始化的全局静态变量会被自动初始化为0(自动对象的值是任意的,除非他被显式初始化)
作用域:作用域仍为局部作用域,当定义它的函数或者语句块结束的时候,作用域结束。但是当局部静态变量离开作用域后,并没有销毁,而是仍然驻留在内存当中,只不过我们不能再对它进行访问,直到该函数再次被调用,并且值不变;
静态函数
在函数返回类型前加 static,函数就定义为静态函数。函数的定义和声明在默认情况下都是 extern的,但静态函数只是在声明他的文件当中可见,不能被其他文件所用。
函数的实现使用 static修饰,那么这个函数只可在本pp内使用,不会同其他Cpp中的同名函数引起冲突Warning:不要再头文件中声明 astatic的全局函数,不要在Cpp内声明非 Estatic的全局函数,如果你要在多个cpp中复用该函数,就把它的声明提到头文件里去,否则pp内部声明需加上 - static修饰
类的静态成员
在类中,静态成员可以实现多个对象之间的数据共享,并且使用静态数据成员还不会破坏隐藏的原则,即保证了安全性。因此,静态成员是类的所有对象中共享的成员,而不是某个对象的成员。对多个对象来说,静态数据成员只存储一处,供所有对象共用
类的静态函数
静态成员函数和静态数据成员一样,它们都属于类的静态成员,它们都不是对象成员。因此,对静态成员的引用不需要用对象名。
在静态成员函数的实现中不能直接引用类中说明的非静态成员,可以引用类中说明的静态成员(这点非常重要)。如果静态成员函数中要引用非静态成员时,可通过对象来引用。从中可看出,调用静态成员函数使用如下格式:<类名>∷<静态成员函数名>(<参数表>)
22.b+树比b树优点
mysql为什么使用B+树而不是B树作为索引?
由于mysql通常将数据存放在磁盘中,读取数据就会产生磁盘IO消耗。而B+树的非叶子节点中不保存数据,B树中非叶子节点会保存数据,通常一个节点大小会设置为磁盘页大小,这样B+树每个节点可放更多的key,B树则更少。这样就造成了,B树的高度会比B+树更高,从而会产生更多的磁盘IO消耗。
B+树叶子节点构成链表,更利用范围查找和排序。而B树进行范围查找和排序则要对树进行递归遍历
B树与B+树比较
B+树层级更少,查找更快
B+树查询速度稳定:由于B+树所有数据都存储在叶子节点,所以查询任意数据的次数都是树的高度h
B+树有利于范围查找
B+树全节点遍历更快:所有叶子节点构成链表,全节点扫描,只需遍历这个链表即可
B树优点:如果在B树中查找的数据离根节点近,由于B树节点中保存有数据,那么这时查询速度比B+树快。
23.堆和栈区别
数据结构:
栈先进后出
堆就是用数组实现的二叉树,所有它没有使用父指针或者子指针。堆根据“堆属性”来排序,“堆属性”决定了树中节点的位置
内存中的:
栈中分配局部变量、临时变量的内存空间,内存中的栈区处于相对较高的地址以地址的增长方向为上,栈的内存相对较少,所以开辟太多的,可能会导致栈溢出(例如使用递归的时候,递归层数太深或是没有递归终止的条件都可能导致栈溢出)。 效率比堆高
堆区是向上增长的用于分配程序员申请的内存空间,如malloc和new出来的空间都是放在堆区,这些堆区的变量的特点就是手动开辟和手动释放,没能及时释放可能会导致内存泄漏的问题。
24.虚函数,构造函数和析构函数可以是虚函数吗?
答案是构造函数不能是虚函数,析构函数可以是虚函数且推荐最好设置为虚函数。
25.TCP保证可靠传输
26.
-
多态
基类指针可以按照基类的方式来做事,也可以按照派生类的方式来做事,它有多种形态,或者说有多种表现方式,我们将这种现象称为多态(Polymorphism)。——换句话说, 利用虚函数,借助虚函数表,基类指针指向基类对象时就使用基类的成员(包括成员函数和成员变量),指向派生类对象时就使用派生类的成员。
-
虚函数,虚函数表
当一个类里存在虚函数时,编译器会为类创建一个虚函数表, 虚函数表 是一个 数组 ,数组的元素存放的是类中 虚函数的地址 。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









