






需求
表: Employees
±------------±--------+
| Column Name | Type |
±------------±--------+
| employee_id | int |
| name | varchar |
| salary | int |
±------------±--------+
employee_id 是这个表的主键.
这个表格的每一行包含雇员ID(employee_id), 雇员姓名(name)和雇员工资(salary)信息.
这家公司想要将工资相同的雇员划分到同一个队伍中。每个队伍需要满足如下要求:
每个队伍需要由至少两个雇员组成。
同一个队伍中的所有雇员的工资相同。
工资相同的所有雇员必须被分到同一个队伍中。
如果某位雇员的工资是独一无二的,那么它不被分配到任何一个队伍中。
队伍ID的设定基于这支队伍的工资相对于其他队伍的工资的排名,即工资最低的队伍满足 team_id = 1 。注意,排名时不需要考虑没有队伍的雇员的工资。
编写一个 SQL 查询来获取每一个被分配到队伍中的雇员的 team_id 。
返回的结果表按照 team_id 升序排列。如果相同,则按照 employee_id 升序排列。
查询结果格式如下例。
示例 1:
输入:
Employees 表:
±------------±--------±-------+
| employee_id | name | salary |
±------------±--------±-------+
| 2 | Meir | 3000 |
| 3 | Michael | 3000 |
| 7 | Addilyn | 7400 |
| 8 | Juan | 6100 |
| 9 | Kannon | 7400 |
±------------±--------±-------+
输出:
±------------±--------±-------±--------+
| employee_id | name | salary | team_id |
±------------±--------±-------±--------+
| 2 | Meir | 3000 | 1 |
| 3 | Michael | 3000 | 1 |
| 7 | Addilyn | 7400 | 2 |
| 9 | Kannon | 7400 | 2 |
±------------±--------±-------±--------+
解释:
Meir (employee_id=2) 和 Michael (employee_id=3) 在同一个队伍中,因为他们的工资都是3000。
Addilyn (employee_id=7) 和 Kannon (employee_id=9) 在同一个队伍中,因为他们的工资都是7400。
Juan (employee_id=8) 不在任何一个队伍中,因为他的工资为6100,是独一无二的(即:没有人和他的工资相同)。
队伍ID按照如下方式分配(基于工资排名,较低的排在前面):
- team_id=1: Meir 和 Michael, 工资是3000
- team_id=2: Addilyn 和 Kannon, 工资是7400
Juan的工资(6100)没有被计算在排名中,因为他不属于任何一个队伍。
输入
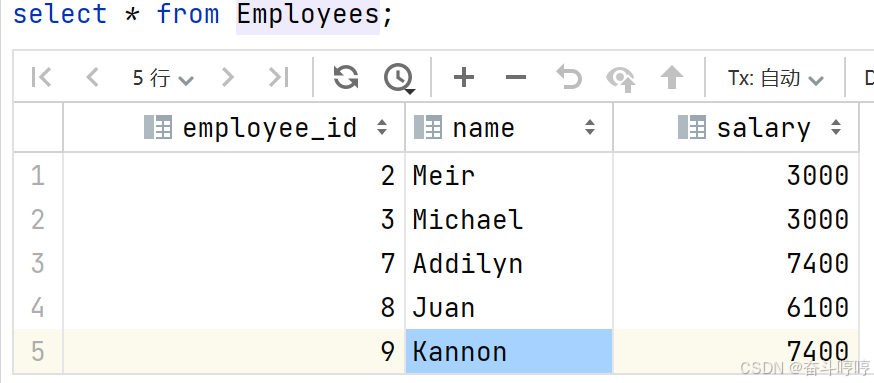
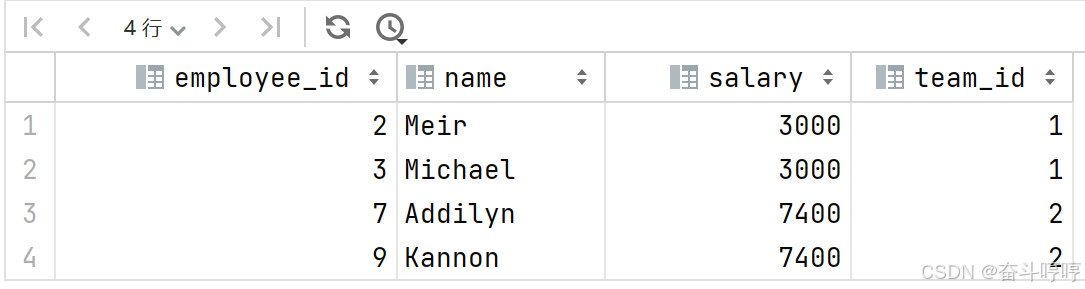
输出
with t1 as (
select *,count(1) over (partition by salary) as cnt
from Employees
),t2 as (
select *,dense_rank() over(order by salary) as dr
from t1
where cnt>1
)
select employee_id,name,salary,dr as team_id
from t2
order by dr,employee_id
;


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









