







 本文提出了一种名为HybridMIM的新型自监督学习框架,用于3D医学图像分割。该框架结合了像素级、区域级和样本级的语义信息学习,通过分层掩模策略和混合掩模图像建模,提高了模型的预训练效率和泛化能力。实验结果显示,HybridMIM在多个公共医学图像分割数据集上优于现有方法,包括基于CNN和Transformer的模型。HybridMIM通过局部区域预测、补丁掩蔽感知和基于dropout的对比学习,减少了预训练时间和手动标注的需求。
本文提出了一种名为HybridMIM的新型自监督学习框架,用于3D医学图像分割。该框架结合了像素级、区域级和样本级的语义信息学习,通过分层掩模策略和混合掩模图像建模,提高了模型的预训练效率和泛化能力。实验结果显示,HybridMIM在多个公共医学图像分割数据集上优于现有方法,包括基于CNN和Transformer的模型。HybridMIM通过局部区域预测、补丁掩蔽感知和基于dropout的对比学习,减少了预训练时间和手动标注的需求。
摘要:基于变主干的掩膜图像建模(MIM)作为一种强大的自监督预训练技术,近年来得到了广泛的应用。现有的MIM方法采用的策略是对图像的随机斑块进行掩码,重建缺失的像素点,只考虑较低层次的语义信息,预训练时间较长。提出了一种基于掩模图像建模的混合自监督学习方HybridMIM,用于医学三维图像分割。具体来说,我们设计了一个两级屏蔽层次结构来指定子卷中哪些补丁被屏蔽以及如何被屏蔽,有效地提供了更高级别语义信息的约束。然后,我们从三个层面学习医学图像的语义信息,包括:1)局部区域预测重建三维图像的关键内容,大大减少了预训练的时间负担(像素级);2)斑块掩蔽感知,学习各子卷(区域级)斑块之间的空间关系。3)基于drop-out的mini-batch内样本间的对比学习,进一步提高了框架的泛化能力(样本级)。所提出的框架是通用的,既支持CNN和变压器作为编码器骨干,也能够预训练解码器进行图像分割。
我们在BraTS2020、BTCV、MSD肝脏和MSD脾脏四种广泛使用的公共医学图像分割数据集上进行了综合实验。实验结果表明,在定量指标、时序性能和定性观察方面,HybridMIM明显优于竞争性的监督方法、掩模预训练方法和其他自监督方法。HybridMIM的代码可在https://github.com/ge-xing/HybridMIM上获得。
I. INTRODUCTION 介绍
在医学图像分析领域[1]-[3]中,医学图像的自动分割一直是一个热点,以方便病灶的诊断和量化,以及治疗计划和评估。近几十年来,人们开发了许多基于深度学习的医学图像分割算法,以获得更好的分割性能。值得注意的是,训练基于深度学习的算法通常需要大量手动标记的数据。然而,在医学图像分析领域,与自然图像相比,标记的3D医疗数据的数量往往较少,因为标记3D医疗数据不仅繁琐且耗时,而且需要医生的大量参与,以提供相当多的领域专业知识[4]。
为了缓解标记数据不足的问题,人们开发了自监督学习(self - supervised learning, SSL)方案[5]-[8]来学习未标记数据的通用表示,当对下游任务进行微调时,获得的模型可以具有更快的收敛速度和更高的精度。典型的自监督学习方案包括使用定制代理任务[9]、[10]、自监督对比学习[11]和掩膜图像建模[12]。前者设计特定的借口任务,如修补、随机旋转、扭曲等,用于图像恢复。对比学习通过构建正、负样本对来学习不同样本之间的关系特征。掩膜图像建模是一项新兴的技术,它通过预测输入数据的掩膜部分应该是什么来学习隐藏的上下文特征,显示出良好的潜力。
值得注意的是,大多数自监督学习方法都是针对自然图像开发的,可能无法很好地迁移到医学图像域[13],因为三维医学图像数据具有更高的维度,可以包含多种模态。有几种方法可以探索如何将自监督学习应用于3D医学图像。例如,视觉词学习[14]使用自编码器主动发现语义视觉词,并将其作为自监督学习标签,使模型能够学习到丰富的语义信息。但其预训练需要构建自监督学习标签,预训练负担较大。UNetFormer[15]采用了3D Swin Transformer编码器,通过预测随机被屏蔽的体积令牌直接应用掩码图像建模。就像目前的MAE[12]和SimMIM[16]方法一样,它从较低的语义层面恢复缺失的像素。此外,重建整个图像耗时,导致预训练性能较慢。
在本文中,我们提出了一种新的基于分层掩模图像建模的混合自监督学习框架(HybridMIM),用于三维医学图像分割。我们的框架在像素/区域/样本三个层次学习三维未标记医学图像的综合语义表示,如图1所示,我们设计了一个两层的掩蔽层次来支持随机掩蔽子区域或补丁,并提出了一个联合自监督学习来考虑不同层次的语义信息。在像素级,我们采用局部区域预测方案来重建3D图像的关键部分,而不是像MAE那样预测所有被掩盖的patch[12],这可以大大加快预训练的速度。掩蔽状态反映了掩蔽子区域的位置和数量,可以帮助模型在区域水平上表征解剖信息。最后,我们在样本水平上使用基于辍学的对比学习策略,以提高模型区分不同样本的能力。
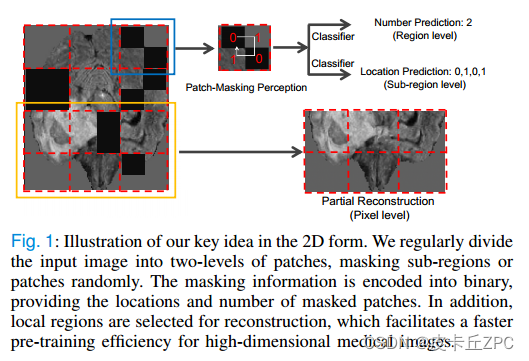
图1:以2D形式展示我们的核心理念。我们将输入图像有规律地划分为两级小块,随机屏蔽子区域或小块。掩蔽信息被编码成二进制,提供掩蔽补丁的位置和数量。此外,选取局部区域进行重建,提高了高维医学图像的预训练效率。
我们提出的HybridMIM兼容不同的网络架构,我们采用UNet和SwinUNETR作为底层架构。在BraTS2020[17]、[18]、BTCV[19]、msd -脾脏和msd -肝脏[20]等4个下游分割任务上,通过使用相同数据或不同数据的预训练和微调两种评估模式验证了我们方法的有效性,这些任务涵盖了不同的器官、不同的对象数量和多模态。综合实验结果表明,我们的HybridMIM在下游分割任务的准确率和训练效率方面都优于现有的最先进的自监督方法。
综上所述,我们的HybridMIM自监督学习方法具有以下主要特点:我们的方法可以作为一个通用的预训练框架,我们证明了它支持多尺度卷积神经网络和变压器网络架构。
•全面性。我们的方法旨在从像素级、区域级到样本级学习数据中的语义信息。
•鲁棒性。在多个广泛使用的公共分割数据集上,我们的方法在准确率和训练效率上都优于SOTA方法。
II. RELATED WORK 相关工作
A. SSL via Tailored Proxy Tasks 通过定制代理任务实现SSL
这类方法通常通过设计借口任务来构建自监督学习标签。自然图像处理中有几种常用的借口任务。
Image inpainting是通过对原始图像区域的预测来学习视觉表征[21]。拼图游戏[22]通过随机打乱图像补丁并恢复它们来学习图像的结构信息。此外,随机旋转估计[9]通过随机旋转图像并使用网络预测旋转角度来增强对图像的理解。
在医学成像中使用定制代理任务的一个典型工作是Models Genesis[10]。它使用多种方法,如扭曲或基于绘画的方法,破坏原始图像中的像素[9],[21],[23],然后利用编码器-解码器结构网络进行恢复。该方法主要关注局部信息的预测。
TransVW[14]将不同的图像区域分类为语义视觉词,在预测区域类别的同时重构随机屏蔽的视觉词区域。该方法在下游任务上取得了较好的性能,但需要先寻找语义视觉词,预训练负担较大。汤玉成等[13]通过绘制、旋转和对比学习三个代理任务对游泳变压器进行预训练。该方法基于掩模图像建模策略,构建了三个不同层次的代理任务,分别
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









