







Redis实战
缓存穿透问题的解决思路
常见的结局方案有两种
- 缓存空对象
- 优点:实现简单,维护方便
- 缺点:额外的内存消耗,可能造成短期的不一致
- 布隆过滤
- 优点:内存占用啥哦,没有多余的key
- 缺点:实现复杂,可能存在误判
-
缓存空对象思路分析:当我们客户端访问不存在的数据时,会先请求redis,但是此时redis中也没有数据,就会直接访问数据库,但是数据库里也没有数据,那么这个数据就穿透了缓存,直击数据库。但是数据库能承载的并发不如redis这么高,所以如果大量的请求同时都来访问这个不存在的数据,那么这些请求就会访问到数据库,简单的解决方案就是哪怕这个数据在数据库里不存在,我们也把这个这个数据存在redis中去(这就是为啥说会有额外的内存消耗),这样下次用户过来访问这个不存在的数据时,redis缓存中也能找到这个数据,不用去查数据库。可能造成的短期不一致是指在空对象的存活期间,我们更新了数据库,把这个空对象变成了正常的可以访问的数据,但由于空对象的TTL还没过,所以当用户来查询的时候,查询到的还是空对象,等TTL过了之后,才能访问到正确的数据,不过这种情况很少见罢了
-
布隆过滤思路分析:布隆过滤器其实采用的是哈希思想来解决这个问题,通过一个庞大的二进制数组,根据哈希思想去判断当前这个要查询的数据是否存在,如果布隆过滤器判断存在,则放行,这个请求会去访问redis,哪怕此时redis中的数据过期了,但是数据库里一定会存在这个数据,从数据库中查询到数据之后,再将其放到redis中。如果布隆过滤器判断这个数据不存在,则直接返回。这种思想的优点在于节约内存空间,但存在误判,误判的原因在于:布隆过滤器使用的是哈希思想,只要是哈希思想,都可能存在哈希冲突
缓存穿透产生的原因是什么?
用户请求的数据在缓存中和在数据库中都不存在,不断发起这样的请求,会给数据库带来巨大压力。
缓存产投的解决方案有哪些?
- 缓存null值
- 布隆过滤
- 增强id复杂度,避免被猜测id规律(可以采用雪花算法)
- 做好数据的基础格式校验
- 加强用户权限校验
- 做好热点参数的限流
缓存雪崩问题及解决思路
- 缓存雪崩是指在同一时间段,大量缓存的key同时失效,或者Redis服务宕机,导致大量请求到达数据库,带来巨大压力。
- 解决方案
- 给不同的Key的TTL添加随机值,让其在不同时间段分批失效
- 利用Redis集群提高服务的可用性(使用一个或者多个哨兵(Sentinel)实例组成的系统,对redis节点进行监控,在主节点出现故障的情况下,能将从节点中的一个升级为主节点,进行故障转义,保证系统的可用性。 )
- 给缓存业务添加降级限流策略
- 给业务添加多级缓存(浏览器访问静态资源时,优先读取浏览器本地缓存;访问非静态资源(ajax查询数据)时,访问服务端;请求到达Nginx后,优先读取Nginx本地缓存;如果Nginx本地缓存未命中,则去直接查询Redis(不经过Tomcat);如果Redis查询未命中,则查询Tomcat;请求进入Tomcat后,优先查询JVM进程缓存;如果JVM进程缓存未命中,则查询数据库)
缓存击穿问题及解决思路
- 缓存击穿也叫热点Key问题,就是一个被高并发访问并且缓存重建业务较复杂的key突然失效了,那么无数请求访问就会在瞬间给数据库带来巨大的冲击。
- 举个不太恰当的例子:一件秒杀中的商品的key突然失效了,大家都在疯狂抢购,那么这个瞬间就会有无数的请求访问去直接抵达数据库,从而造成缓存击穿。
- 常见的解决方案有两种
- 互斥锁
- 逻辑过期
逻辑分析:假设线程1在查询缓存之后未命中,本来应该去查询数据库,重建缓存数据,完成这些之后,其他线程也就能从缓存中加载这些数据了。但是在线程1还未执行完毕时,又进来了线程2、3、4同时来访问当前方法,那么这些线程都不能从缓存中查询到数据,那么他们就会在同一时刻访问数据库,执行SQL语句查询,对数据库访问压力过大
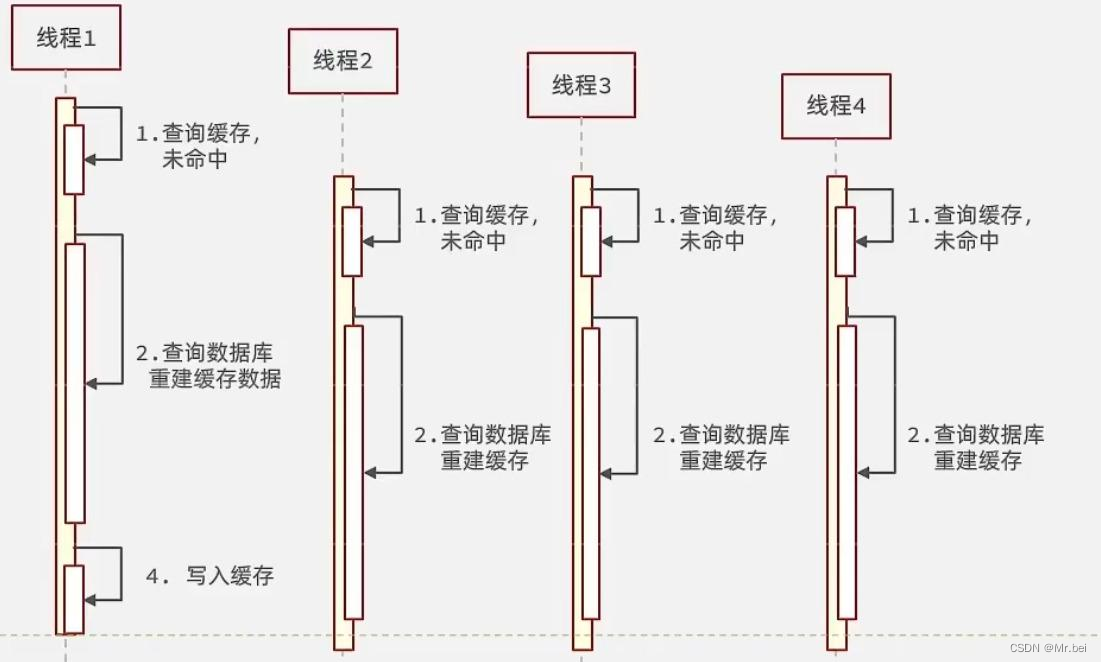
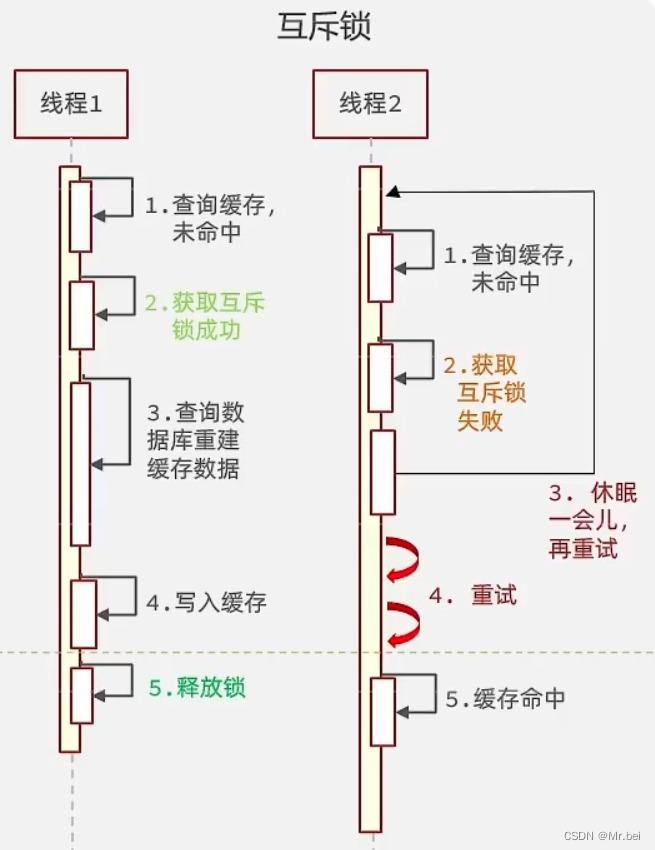
解决方案一:互斥锁
利用锁的互斥性,假设线程过来,只能一个人一个人的访问数据库,从而避免对数据库频繁访问产生过大压力,但这也会影响查询的性能,将查询的性能从并行变成了串行,我们可以采用tryLock方法+double check来解决这个问题。
线程1在操作的时候,拿着锁把房门锁上了,那么线程2、3、4就不能都进来操作数据库,只有1操作完了,把房门打开了,此时缓存数据也重建好了,线程2、3、4直接从redis中就可以查询到数据。
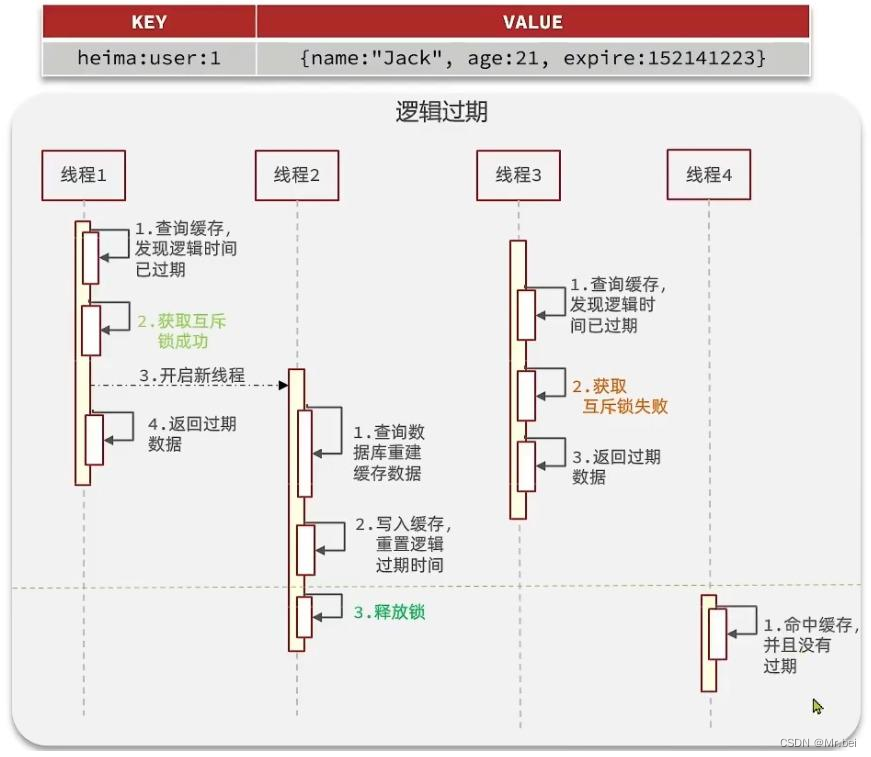
解决方案二:逻辑过期方案
方案分析:我们之所以会出现缓存击穿问题,主要原因是在于我们对key设置了TTL,如果我们不设置TTL,那么就不会有缓存击穿问题,但是不设置TTL,数据又会一直占用我们的内存,所以我们可以采用逻辑过期方案
我们之前是TTL设置在redis的value中,注意:这个过期时间并不会直接作用于Redis,而是我们后续通过逻辑去处理。假设线程1去查询缓存,然后从value中判断当前数据已经过期了,此时线程1去获得互斥锁,那么其他线程会进行阻塞,获得了锁的进程他会开启一个新线程去进行之前的重建缓存数据的逻辑,直到新开的线程完成者逻辑之后,才会释放锁,而线程1直接进行返回,假设现在线程3过来访问,由于线程2拿着锁,所以线程3无法获得锁,线程3也直接返回数据(但只能返回旧数据,牺牲了数据一致性,换取性能上的提高),只有等待线程2重建缓存数据之后,其他线程才能返回正确的数据
这种方案巧妙在于,异步构建缓存数据,缺点是在重建完缓存数据之前,返回的都是脏数据
对比互斥锁与逻辑删除
- 互斥锁方案:由于保证了互斥性,所以数据一致,且实现简单,只是加了一把锁而已,也没有其他的事情需要操心,所以没有额外的内存消耗,缺点在于有锁的情况,就可能死锁,所以只能串行执行,性能会受到影响
- 逻辑过期方案:线程读取过程中不需要等待,性能好,有一个额外的线程持有锁去进行重构缓存数据,但是在重构数据完成之前,其他线程只能返回脏数据,且实现起来比较麻烦
| 解决方案 | 优点 | 缺点 |
|---|---|---|
| 互斥锁 | 没有额外的内存消耗,保证一致性,实现简单 | 线程需要等待,性能受影响可能有死锁风险 |
| 逻辑过期 | 线程无需等待,性能较好 | 不保证一致性,有额外内存消耗,实现复杂 |
多线程安全问题
针对超卖这一问题的常见解决方案就是加锁:而对于加锁,我们通常有两种解决方案
- 悲观锁
- 悲观锁认为线程安全问题一定会发生,因此在操作数据之前先获取锁,确保线程串行执行
- 例如Synchronized、Lock等,都是悲观锁
- 乐观锁
- 乐观锁认为线程安全问题不一定会发生,因此不加锁,只是在更新数据的时候再去判断有没有其他线程对数据进行了修改
- 如果没有修改,则认为自己是安全的,自己才可以更新数据
- 如果已经被其他线程修改,则说明发生了安全问题,此时可以重试或者异常
- 悲观锁:悲观锁可以实现对于数据的串行化执行,比如syn,和lock都是悲观锁的代表,同时,悲观锁中又可以再细分为公平锁,非公平锁,可重入锁,等等
- 乐观锁:乐观锁会有一个版本号,每次操作数据会对版本号+1,再提交回数据时,会去校验是否比之前的版本大1 ,如果大1 ,则进行操作成功,这套机制的核心逻辑在于,如果在操作过程中,版本号只比原来大1 ,那么就意味着操作过程中没有人对他进行过修改,他的操作就是安全的,如果不大1,则数据被修改过,当然乐观锁还有一些变种的处理方式比如cas
- 乐观锁的典型代表:就是cas,利用cas进行无锁化机制加锁,var5 是操作前读取的内存值,while中的var1+var2 是预估值,如果预估值 == 内存值,则代表中间没有被人修改过,此时就将新值去替换 内存值
分布式锁
分布式锁:满足分布式系统或集群模式下多线程课件并且可以互斥的锁
分布式锁的核心思想就是让大家共用同一把锁,那么我们就能锁住线程,不让线程进行,让程序串行执行,这就是分布式锁的核心思路
- 可见性:多个线程都能看到相同的结果。
- 互斥:互斥是分布式锁的最基本条件,使得程序串行执行
- 高可用:程序不已崩溃,时时刻刻都保证较高的可用性
- 高性能:由于加锁本身就让性能降低,所以对于分布式锁需要他较高的加锁性能和释放锁性能
- 安全性:安全也是程序中必不可少的一环
常见的分布式锁有三种
- MySQL:MySQL本身就带有锁机制,但是由于MySQL的性能一般,所以采用分布式锁的情况下,使用MySQL作为分布式锁比较少见
- Redis:Redis作为分布式锁是非常常见的一种使用方式,现在企业级开发中基本都是用Redis或者Zookeeper作为分布式锁,利用SETNX这个方法,如果插入Key成功,则表示获得到了锁,如果有人插入成功,那么其他人就回插入失败,无法获取到锁,利用这套逻辑完成互斥,从而实现分布式锁
- Zookeeper:Zookeeper也是企业级开发中较好的一种实现分布式锁的方案,但本文是学Redis的,所以这里就不过多阐述了
| MySQL | Redis | Zookeeper | |
|---|---|---|---|
| 互斥 | 利用mysql本身的互斥锁机制 | 利用setnx这样的互斥命令 | 利用节点的唯一性和有序性实现互斥 |
| 高可用 | 好 | 好 | 好 |
| 高性能 | 一般 | 好 | 一般 |
| 安全性 | 断开连接,自动释放锁 | 利用锁超时时间,到期释放 | 临时节点,断开连接自动释放 |
分布式锁-Redisson
Redis提供了分布式锁的多种多样功能
- 可重入锁(Reentrant Lock)
- 公平锁(Fair Lock)
- 联锁(MultiLock)
- 红锁(RedLock)
- 读写锁(ReadWriteLock)
- 信号量(Semaphore)
- 可过期性信号量(PermitExpirableSemaphore)
- 闭锁(CountDownLatch)
Redisson可重入锁原理
-
在Lock锁中,他是借助于等曾的一个voaltile的一个state变量来记录重入的状态的
- 如果当前没有人持有这把锁,那么state = 0
- 如果有人持有这把锁,那么state = 1
- 如果持有者把锁的人再次持有这把锁,那么state会+1
- 如果对于synchronize而言,他在c语言代码中会有一个count
- 原理与state类似,也是重入一次就+1,释放一次就-1,直至减到0,表示这把锁没有被人持有
-
在redisson中,我们也支持可重入锁
- 在分布式锁中,它采用hash结构来存储锁,其中外层key表示这把锁是否存在,内层key则记录当前这把锁被哪个线程持有

Redisson锁重试和WatchDog机制
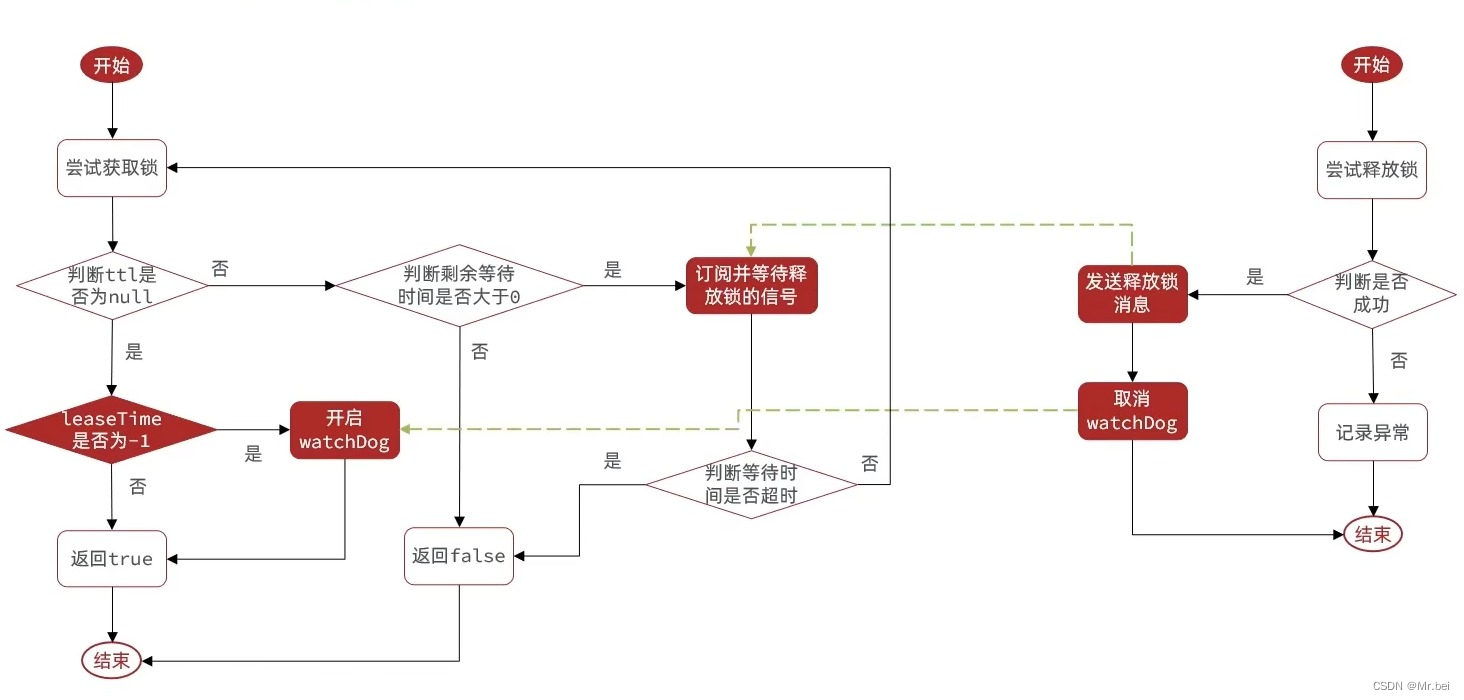
Redisson锁的MutiLock原理
- 为了提高Redis的可用性,我们会搭建集群或者主从,现在以主从为例
- 此时我们去写命令,写在主机上,主机会将数据同步给从机,但是假设主机还没来得及把数据写入到从机去的时候,主机宕机了
- 哨兵会发现主机宕机了,于是选举一个slave(从机)变成master(主机),而此时新的master(主机)上并没有锁的信息,那么其他线程就可以获取锁,又会引发安全问题
- 为了解决这个问题。Redisson提出来了MutiLock锁,使用这把锁的话,那我们就不用主从了,每个节点的地位都是一样的,都可以当做是主机,那我们就需要将加锁的逻辑写入到每一个主从节点上,只有所有的服务器都写入成功,此时才是加锁成功,假设现在某个节点挂了,那么他去获取锁的时候,只要有一个节点拿不到,都不能算是加锁成功,就保证了加锁的可靠性
小结
- 不可重入Redis分布式锁
- 原理:利用SETNX的互斥性;利用EX避免死锁;释放锁时判断线程标识
- 缺陷:不可重入、无法重试、锁超时失效
- 可重入Redis分布式锁
- 原理:利用Hash结构,记录线程标识与重入次数;利用WatchDog延续锁时间;利用信号量控制锁重试等待
- 缺陷:Redis宕机引起锁失效问题
- Redisson的multiLock
- 原理:多个独立的Redis节点,必须在所有节点都获取重入锁,才算获取锁成功
- 缺陷:运维成本高、实现复杂
Redis消息队列
- 什么是消息队列?字面意思就是存放消息的队列,最简单的消息队列模型包括3个角色
- 消息队列:存储和管理消息,也被称为消息代理(Message Broker)
- 生产者:发送消息到消息队列
- 消费者:从消息队列获取消息并处理消息
- 使用队列的好处在于解耦:举个例子,快递员(生产者)吧快递放到驿站/快递柜里去(Message Queue)去,我们(消费者)从快递柜/驿站去拿快递,这就是一个异步,如果耦合,那么快递员必须亲自上楼把快递递到你手里,服务当然好,但是万一我不在家,快递员就得一直等我,浪费了快递员的时间。所以解耦还是非常有必要的
基于List实现消息队列
- 优点
- 利用Redis存储,不受限于JVM内存上限
- 基于Redis的持久化机制,数据安全性有保障
- 可以满足消息有序性
- 缺点
- 无法避免消息丢失(经典服务器宕机)
- 只支持单消费者(一个消费者把消息拿走了,其他消费者就看不到这条消息了)
基于PubSub的消息队列
SUBSCRIBE channel [channel]:订阅一个或多个频道
PUBLISH channel msg:向一个频道发送消息
PSUBSCRIBE pattern [pattern]:订阅与pattern格式匹配的所有频道
- 优点:
- 采用发布订阅模型,支持多生产,多消费
- 缺点:
- 不支持数据持久化
- 无法避免消息丢失(如果向频道发送了消息,却没有人订阅该频道,那发送的这条消息就丢失了)
- 消息堆积有上限,超出时数据丢失(消费者拿到数据的时候处理的太慢,而发送消息发的太快)
基于Stream的消息队列
- STREAM类型消息队列的XREAD命令特点
- 消息可回溯
- 一个消息可以被多个消费者读取
- 可以阻塞读取
- 有漏读消息的风险
基于Stream的消息队列—消费者组
-
消费者组(Consumer Group):将多个消费者划分到一个组中,监听同一个队列,具备以下特点
- 消息分流
- 队列中的消息会分留给组内的不同消费者,而不是重复消费者,从而加快消息处理的速度
- 消息标识
- 消费者会维护一个标识,记录最后一个被处理的消息,哪怕消费者宕机重启,还会从标识之后读取消息,确保每一个消息都会被消费
- 消息确认
- 消费者获取消息后,消息处于pending状态,并存入一个pending-list,当处理完成后,需要通过XACK来确认消息,标记消息为已处理,才会从pending-list中移除
- 消息分流
-
STREAM类型消息队列的XREADGROUP命令的特点
- 消息可回溯
- 可以多消费者争抢消息,加快消费速度
- 可以阻塞读取
- 没有消息漏读风险
- 有消息确认机制,保证消息至少被消费一次
小结
| List | PubSub | Stream | |
|---|---|---|---|
| 消息持久化 | 支持 | 不支持 | 支持 |
| 阻塞读取 | 支持 | 支持 | 支持 |
| 消息堆积处理 | 受限于内存空间,可以利用多消费者加快处理 | 受限于消费者缓冲区 | 受限于队列长度,可以利用消费者组提高消费速度,减少堆积 |
| 消息确认机制 | 不支持 | 不支持 | 支持 |
| 消息回溯 | 不支持 | 不支持 | 支持 |
GEO数据结构
GEO就是Geolocation的简写形式,代表地理坐标。Redis在3.2版本中加入了对GEO的支持,允许存储地理坐标信息,帮助我们根据经纬度来检索数据。常见的命令有:
GEOADD:添加一个地理空间信息,包含:经度(longitude)、纬度(latitude)、值(member)
GEODIST:计算指定的两个点之间的距离并返回
GEOHASH:将指定member的坐标转为hash字符串形式并返回
GEOPOS:返回指定member的坐标
GEORADIUS:指定圆心、半径,找到该圆内包含的所有member,并按照与圆心之间的距离排序后返回。6.2以后已废弃
GEOSEARCH:在指定范围内搜索member,并按照与指定点之间的距离排序后返回。范围可以是圆形或矩形。6.2.新功能
GEOSEARCHSTORE:与GEOSEARCH功能一致,不过可以把结果存储到一个指定的key。 6.2.新功能
BitMap用法
Redis中是利用string类型数据结构实现BitMap,因此最大上限是512M,转换为bit则是 2^32个bit位
BitMap的操作命令有:
SETBIT:向指定位置(offset)存入一个0或1
GETBIT :获取指定位置(offset)的bit值
BITCOUNT :统计BitMap中值为1的bit位的数量
BITFIELD :操作(查询、修改、自增)BitMap中bit数组中的指定位置(offset)的值
BITFIELD_RO :获取BitMap中bit数组,并以十进制形式返回
BITOP :将多个BitMap的结果做位运算(与 、或、异或)
BITPOS :查找bit数组中指定范围内第一个0或1出现的位置
HyperLogLog用法
常用的三个方法
PFADD key element [element...]
summary: Adds the specified elements to the specified HyperLogLog
PFCOUNT key [key ...]
Return the approximated cardinality of the set(s) observed by the HyperLogLog at key(s).
PFMERGE destkey sourcekey [sourcekey ...]
lnternal commands for debugging HyperLogLog values



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











