







一、从 DETR 到 DINO
目标检测是计算机视觉中的基础任务,涉及识别和定位图像中的物体。传统的目标检测系统,如 Faster R-CNN 和 YOLO,就像一条复杂的生产流水线,需要多个精心设计的工序:先生成可能包含物体的区域(称为"锚点"),然后筛选重叠的预测("非极大值抑制")。这些方法虽然有效,但由于严重依赖卷积操作和手工设计的组件,其过于复杂且难以优化。
2020年,一项名为 DETR(DEtection TransFormer)的革命性技术出现了。它借鉴了自然语言处理中的 Transformer 架构,简化了整个检测过程,实现了真正的端到端目标检测。然而,尽管 DETR 方法优雅,但这些模型难以匹配改进后的经典检测器的性能,并且训练收敛缓慢。DINO 模型(具有改进型去噪锚框的 DETR)通过对 DETR 架构引入几项关键改进,解决了这些限制并实现了最先进的性能。
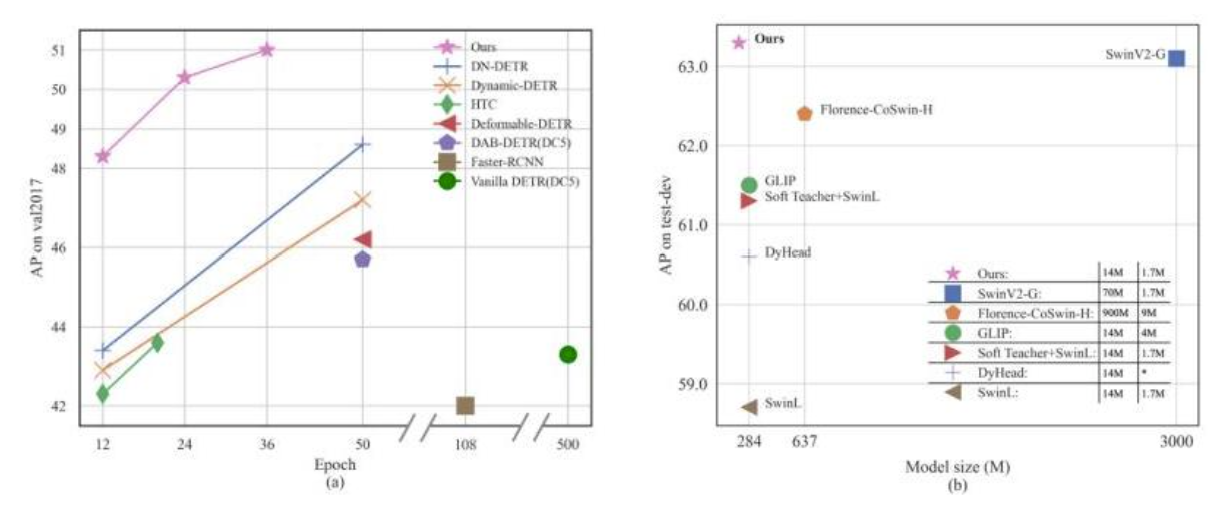
图1:DINO 模型与其他 DETR 变体的性能比较。(a) DINO 模型在 COCO val2017 上以更少的训练周期实现显著更高的 AP。(b) DINO 在各种模型尺寸上优于(当时)最先进的模型。
二、DINO 的架构与创新
如图 2 所示,DINO 模型的整体架构包含 4 个部分:
(1)骨干网络:使用 ResNet-50 或 Swin Transformer 从输入图像中提取特征。
(2)Transformer 编码器:处理并增强图像特征。
(3)Transformer 解码器:优化目标查询以预测物体位置和类别。
(4)预测头:为目标类别和边界框生成最终预测。
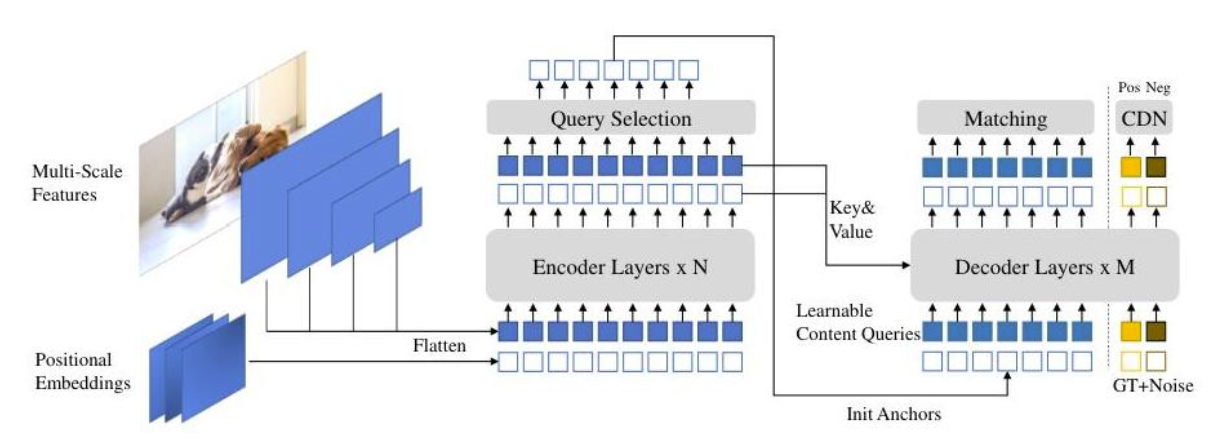
图2:DINO 架构概览,展示了具有对比性去噪训练的 Transformer 编码器-解码器结构。
DINO 模型在保留先前 DETR 变体架构基础的同时引入了几项关键创新,这些创新包括:
2.1 对比性去噪训练
我们经常遇见类似的难题:比如区分双胞胎、识别相似的动物品种。DINO 模型的第一个创新就是教会模型这种细微区分的能力。
想象你在教一个孩子认识猫:你会同时展示一只真正的猫(正样本)和一些看起来像猫但实际上不是的动物(负样本),比如小型犬或者幼狮,并告诉他们:"这是猫,而这些看起来像猫但不是猫"。
DINO的对比性去噪训练就是这个道理。在训练过程中,它同时学习识别某个物体的正确版本(尽管有些噪声)和容易混淆的错误版本。这使得 DINO 能更准确地区分相似物体,减少重复检测的问题。
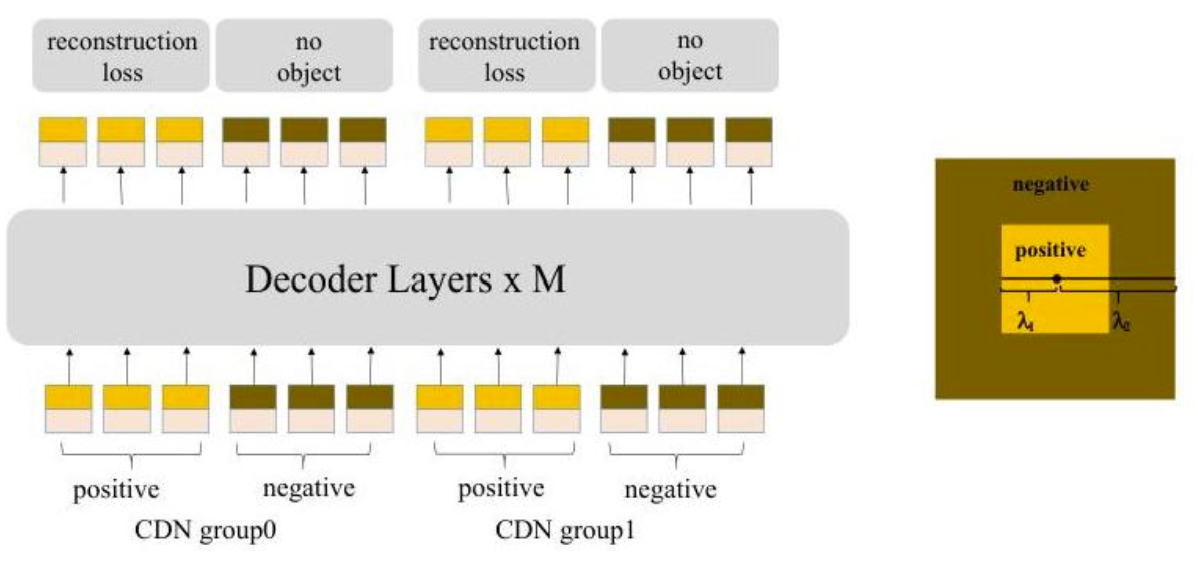
图3:对比性去噪训练过程。解码器在 CDN 组中处理正样本和负样本,帮助模型区分相似物体。
虽然 DN-DETR 引入去噪来稳定二分图匹配,但 DINO 模型经过对比性去噪训练以后,能够更高的精度。DN 和 DINO 模型之间的训练比较,清晰地展示了 DINO 模型在定位精度方面的改进:
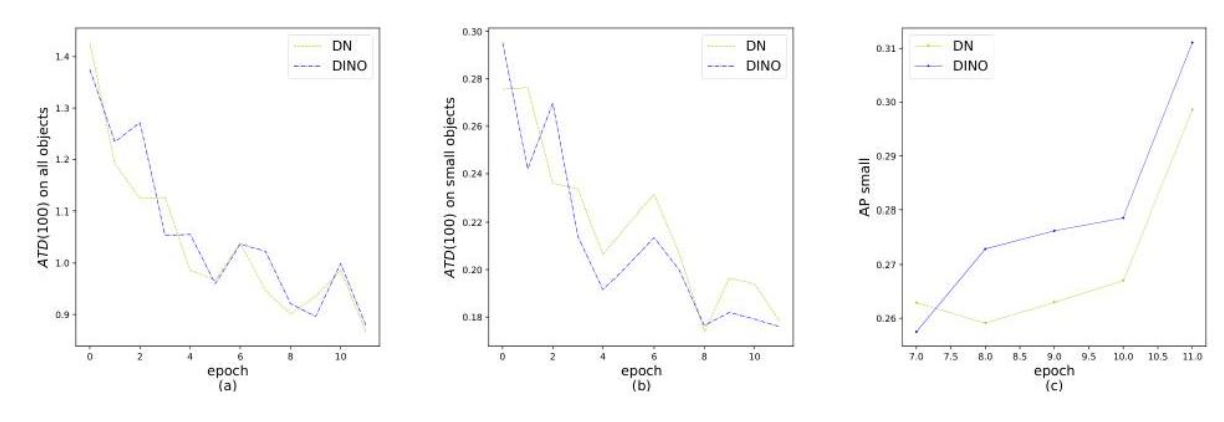
图4 DN 和 DINO 之间的训练比较,显示了位置精度的性能差异。
2.2 混合查询选择
DINO的第二个创新类似于结合了人类的直觉和深入思考的优势——在寻找物体时,人类会先用“直觉”快速扫描可能的位置(“那里好像有个人形物体”),然后用“思考”仔细分析内容(“看外形和颜色,那是一个穿蓝色衣服的小男孩”)。DINO的混合查询选择模仿了这两个阶段:
(1)位置查询(从图像直接生成):相当于直觉,告诉模型"看这里可能有东西";
(2)内容查询(通过学习获得):相当于思考,分析"这里的东西是什么"。
对比之前的 DETR 变体中,这种混合方法提供了更好的初始锚框位置,同时保持了学习内容查询的灵活性。通过利用编码器对图像内容的理解来放置初始锚框,DINO 模型实现了更好的初始化和更快的收敛。
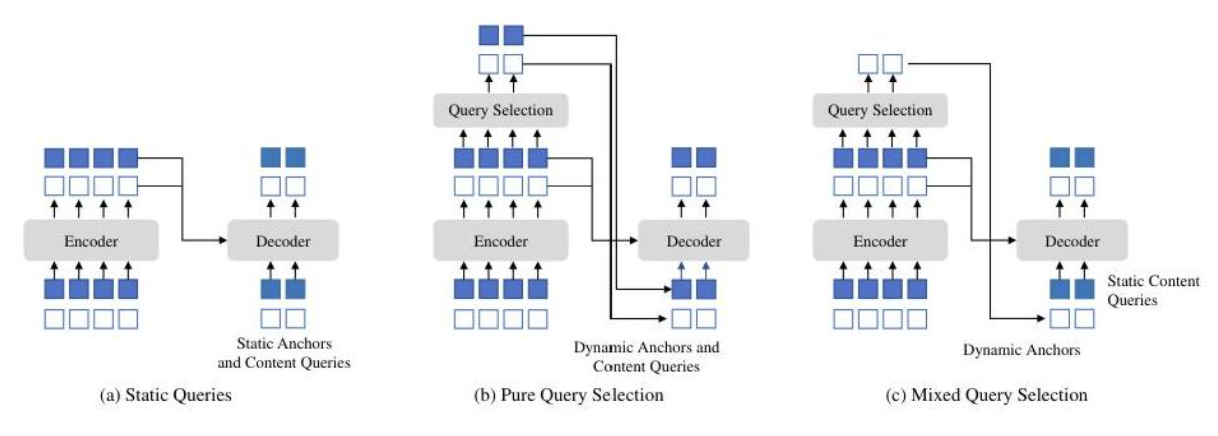
图5 不同查询选择策略的比较:(a) 静态查询,(b) 纯查询选择,(c) DINO使用的混合查询选择。
2.3 二次前瞻机制
DINO的第三个创新就像是优秀的战略规划,不仅考虑当前决策,还考虑后续影响。想象你在玩国际象棋。新手只看当前一步,而高手会思考“如果我走这步,对方可能会如何应对,然后我该如何回应...”。
传统模型在检测物体时会逐步细化预测,但每一步只考虑当前信息。DINO 模型的二次前瞻允许后期更精确的分析反馈给前期决策,实现整体最优化。

图6:(a) 一次前瞻和 (b) 二次前瞻边界框预测细化机制的比较。
三、模型性能与优势
DINO 模型相比先前的基于 DETR 的检测器展示了显著的性能改进。关键性能指标包括:
(1)使用 ResNet-50 骨干网络在 COCO 上 12 轮训练达到 48.3 AP,36 轮训练达到51.0 AP;
(2)使用 ResNet-50 骨干网络并结合辅助损失达到 58.1 AP;
(3)在 Objects365 上进行预训练后,使用SwinL骨干网络在 COCO test-dev 上达到最先进的 63.3 AP。

图7:DINO、DN-Deformable-DETR 和 Deformable DETR 之间的训练收敛比较,显示 DINO 更快的收敛和更高的性能。
与此同时,论文证明,DINO 模型能在更短时间内训练出更准确的模型,大大提高了实际应用效率。
结语
DINO 模型在端到端目标检测方面取得了重大突破,不仅是在 COCO 基准测试上实现了最先进的结果,还显著提升了训练效率,使类 DETR 模型更适用于实际应用。
DINO 模型的成功证明了基于 Transformer 的目标检测方法的可行性,还开辟了新的研究方向。随着计算资源的增加和数据规模的扩大,DINO 模型展现出卓越的可扩展性和崭新的能力,为后续 DINO 家族的强大模型奠定了基调。
== 彩蛋 ==
1. 论文《DINO: DETR with Improved DeNoising Anchor Boxes for End-to-End Object Detection》,作者:Hao Zhang, Feng Li, Shilong Liu, Lei Zhang, Hang Su, Jun Zhu, Lionel M. Ni, Heung-Yeung Shum。链接:https://arxiv.org/abs/2203.03605
2. 调用最新 DINO 家族 API 请前往 DINO-X 开放平台:https://cloud.deepdataspace.com/

















 1215
1215

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









