






并发编程(下)
一、多进程开发
进程是计算机中资源分配的最小单元,一个进程中可以有多个线程,同一个进程中的线程共享资源,进程与进程之间相互隔离。python可以通过多进程利用CPU多核优势,所进程适用于计算密集型项目。
(一)进程介绍
import multiprocessing
def task():
pass
if __name__ == '__main__':
p1 = multiprocessing.Process(target=task)
p1.start()
也可以把多进程放在函数里,用main函数来运行。
from multiprocessing import Process
def task(arg):
pass
def run():
p = Process(target=task, args=('xxx', ))
p.start()
if __name__ == '__main__':
run()
在python中基于multiprocessing模块操作的进程,start methods主要有三种:
- fork:可以拷贝几乎所有资源,支持文件对象/线程锁等传参,unix系统适用,任意位置开始;
- spwan:run参数必备资源,不支持文件对象/线程锁等传参,unix、win适用,main代码模块开始;
- forkserver:run参数必备资源,不支持文件对象/线程锁等传参,部分unix适用,main代码模块开始。
(二)案例
1、示例一:fork模式下复制列表元素到子进程中
先创建一个子进程,然后设置模式为fork,我们可以运行一下子进程,看看线程里的name长什么样,实验结果显示,主线程的name被复制到子进程里。
import multiprocessing
def task():
print(name)
if __name__ == '__main__':
multiprocessing.set_start_method("fork") #fork、spawn、forkserver
name = []
p1 = multiprocessing.Process(target=task)
p1.start()
#[]
在子进程里面修改name,增加列表元素,在子进程和主进程里分别打印name观察,可以发现:进程中改变的name并不会影响主进程中的name。
import multiprocessing
import time
def task():
print(name)
#[]
name.append(123)
print(name)
#[123]
if __name__ == '__main__':
multiprocessing.set_start_method("fork") #fork、spawn、forkserver
name = []
p1 = multiprocessing.Process(target=task)
p1.start()
time.sleep(2)
print(name)
#[]
但是如果append操作放在主线程里,那么经过append操作的name会被复制到进程中,在子进程中打印name可以发现是多了123元素的列表。
import multiprocessing
import time
def task():
print(name)
#[123]
if __name__ == '__main__':
multiprocessing.set_start_method("fork") #fork、spawn、forkserver
name = []
name.append(123)
p1 = multiprocessing.Process(target=task)
p1.start()
2、示例二:spawn模式下复制列表元素到子进程中
切换到spawn模式后,我们可以发现在spawn模式下,name并不能直接复制到进程中,会报错,所以只能当作参数传入到task中。
import multiprocessing
import time
def task(data):
print(data)
#[]
if __name__ == '__main__':
multiprocessing.set_start_method("spawn") #fork、spawn、forkserver
name = []
p1 = multiprocessing.Process(target=task, args=(name, ))
p1.start()
同样的,在子进程中对name进行append操作,结果发现子进程中的改变并不会影响主进程中的name。
import multiprocessing
import time
def task(data):
print(data)
#[]
data.append(999)
print(data)
#[999]
if __name__ == '__main__':
multiprocessing.set_start_method("spawn") #fork、spawn、forkserver
name = []
p1 = multiprocessing.Process(target=task, args=(name, ))
p1.start()
time.sleep(2)
print(name)
#[]
3、示例三:在fork模式下复制文件对象到子进程中
spawn并不支持特殊对象:文件或锁的传参,而且即使是普通对象也只能通过传参的形式进行传递。
import multiprocessing
import time
def task():
print(name)
#[]
file_object.write('闫曦月\n')
file_object.flush() #高宇星和闫曦月这两个内容已经刷到硬盘中了
if __name__ == '__main__':
multiprocessing.set_start_method("fork") #fork、spawn、forkserver
name = []
file_object = open('x1.txt', mode='a+', encoding='utf-8')
file_object.write('高宇星\n')
#写入到内存中,内容还没有写到文件里,在子进程运行完之后才会将该内容刷到硬盘上
p1 = multiprocessing.Process(target=task)
p1.start()
txt的内容是:
高宇星
闫曦月
高宇星
在本案例中,我们创建了一个txt文件,并将高宇星复制到子进程中,子进程在flush的时候把两个数据都写到了硬盘中,最后等子进程运行完之后,主进程再次将高宇星这条数据刷到硬盘中。
import multiprocessing
import time
def task():
print(name)
#[]
file_object.write('闫曦月\n')
file_object.flush()
if __name__ == '__main__':
multiprocessing.set_start_method("fork") #fork、spawn、forkserver
name = []
file_object = open('x1.txt', mode='a+', encoding='utf-8')
file_object.write('高宇星\n')
file_object.flush()
p1 = multiprocessing.Process(target=task)
p1.start()
txt的内容是:
高宇星
闫曦月
这里有不同点,是在主进程里,已经进行了flush,所以已经将内存中的信息高宇星刷到硬盘上了,所以在子进程运行结束之后就不会再刷高宇星到硬盘上了。
4、示例四:在fork模式下复制锁到子进程中
spawn模式下,锁没有办法被传参。
import multiprocessing
import threading
def task():
print(file_object, lock)
#<_io.TextIOWrapper name='x1.txt' mode='a+' encoding='utf-8'> <unlocked _thread.RLock object owner=0 count=0 at 0x7f8a8b14f870>
if __name__ == '__main__':
multiprocessing.set_start_method("fork") #fork、spawn、forkserver
name = []
file_object = open('x1.txt', mode='a+', encoding='utf-8')
lock = threading.RLock()
p1 = multiprocessing.Process(target=task)
p1.start()
当我们在主进程中申请了锁之后,主进程中打印出来的锁是已经进行locked过的。
import multiprocessing
import threading
def task():
pass
if __name__ == '__main__':
multiprocessing.set_start_method("fork") #fork、spawn、forkserver
name = []
lock = threading.RLock()
print(lock)
#<unlocked _thread.RLock object owner=0 count=0 at 0x7fbfe6241d20>
lock.acquire()
print(lock)
# <locked _thread.RLock object owner=4335336896 count=1 at 0x7fd59313cd20>
lock.release()
print(lock)
#<unlocked _thread.RLock object owner=0 count=0 at 0x7fb4ad241d20>
lock.acquire()
print(lock)
#<locked _thread.RLock object owner=4470484416 count=1 at 0x7fa1f4a3cd20>
p1 = multiprocessing.Process(target=task)
p1.start()
当我们在主进程中申请了锁之后,子进程中打印出来的锁是已经进行locked过的,是子进程的主线程锁的。
import multiprocessing
import threading
def task():
#拷贝的锁也是申请走的状态,被谁申请走了?被子进程中的主线程申请走了
print(lock)
#<locked _thread.RLock object owner=4690062784 count=1 at 0x7f9354a3cd20>
lock.acquire()
print(666)
if __name__ == '__main__':
multiprocessing.set_start_method("fork") #fork、spawn、forkserver
name = []
lock = threading.RLock()
#<unlocked _thread.RLock object owner=0 count=0 at 0x7fbfe6241d20>
lock.acquire()
p1 = multiprocessing.Process(target=task)
p1.start()
锁被子进程中的主线程申请走了,所以在子进程中如果创立其他线程的话,其他线程是获取不到锁的,所以程序代码都会卡住,只有将子线程中将主线程的锁进行释放,子进程中其他子线程才会获取到锁并执行下去。
import multiprocessing
import threading
import time
def func():
print("来了")
with lock:
print(666)
time.sleep(1)
def task():
for i in range(10):
t = threading.Thread(target=func)
t.start()
if __name__ == '__main__':
multiprocessing.set_start_method("fork") #fork、spawn、forkserver
name = []
lock = threading.RLock()
#<unlocked _thread.RLock object owner=0 count=0 at 0x7fbfe6241d20>
lock.acquire()
p1 = multiprocessing.Process(target=task)
p1.start()
'''
来了
来了
来了
来了
来了
来了
来了
来了
来了
来了
'''
#程序卡住了,运行不下去
将子线程中的主线程里的lock锁进行释放后,子线程可以正常执行代码。
import multiprocessing
import threading
import time
def func():
print("来了")
with lock:
print(666)
time.sleep(1)
def task():
for i in range(10):
t = threading.Thread(target=func)
t.start()
time.sleep(1)
lock.release()
if __name__ == '__main__':
multiprocessing.set_start_method("fork") #fork、spawn、forkserver
name = []
lock = threading.RLock()
#<unlocked _thread.RLock object owner=0 count=0 at 0x7fbfe6241d20>
lock.acquire()
p1 = multiprocessing.Process(target=task)
p1.start()
'''
来了
来了
来了
来了
来了
来了
来了
来了
来了
来了
666
666
666
666
666
666
666
666
666
666
'''
(三)常见功能
1、p.start()
当前进程准备就绪,等待被CPU调度(工作单元其实就是进程中的线程)
2、p.join()
等待当前进程的任务执行完毕后再向下继续执行
import multiprocessing
from multiprocessing import Process
import threading
import time
def task(arg):
time.sleep(2)
print("执行中。。。")
if __name__ == '__main__':
multiprocessing.set_start_method("spawn") #fork、spawn、forkserver
p = Process(target=task, args=('xxx', ))
p.start()
p.join()
print("继续执行。。。")
'''
执行中。。。
继续执行。。。
'''
3、p.daemon()
是布尔值,守护进程(必须放在start之前)
p.daemon = True :设置为守护进程,主进程执行完之后,子进程也自动关闭。
p.daemon = False :设置为非守护进程,主进程等待子进程,子进程执行完之后,主进程才结束。
import multiprocessing
from multiprocessing import Process
import threading
import time
def task(arg):
time.sleep(2)
print("执行中。。。")
if __name__ == '__main__':
multiprocessing.set_start_method("spawn") #fork、spawn、forkserver
p = Process(target=task, args=('xxx', ))
p.daemon = True
p.start()
print("继续执行。。。")
'''
继续执行。。。
'''
上述代码在执行完主进程之后就自动关闭了,子进程并没有得到执行。
4、进程名称的设置和获取
import multiprocessing
from multiprocessing import Process
import threading
import time
def task(arg):
time.sleep(2)
print("当前进程的名称:", multiprocessing.current_process().name)
if __name__ == '__main__':
multiprocessing.set_start_method("spawn") #fork、spawn、forkserver
p = Process(target=task, args=('xxx', ))
p.name = 'new bee'
p.daemon = False
p.start()
print("继续执行。。。")
'''
继续执行。。。
当前进程的名称: new bee
'''
5、自定义进程类
将进程定义为类,直接僵线程需要做的事儿写到run方法中
import multiprocessing
class MyProcess(multiprocessing.Process):
def run(self):
print('执行此进程', self._args)
if __name__ == '__main__':
multiprocessing.set_start_method('spawn')
p = MyProcess(args=('xxx', ))
p.start()
print("继续执行")
'''
继续执行
执行此进程 ('xxx',)
'''
6、获取进程和子进程id号
import multiprocessing
from multiprocessing import Process
import threading
import time
import os
def func():
time.sleep(1)
def task(arg):
for i in range(10):
t = threading.Thread(target=func)
t.start()
#time.sleep(2)
print(os.getpid(), os.getppid())
print("当前进程的名称:", multiprocessing.current_process().name)
print(len(threading.enumerate())) #获取线程个数
#11
if __name__ == '__main__':
print(os.getpid())
multiprocessing.set_start_method("spawn") #fork、spawn、forkserver
p = Process(target=task, args=('xxx', ))
p.name = 'new bee'
p.daemon = False
p.start()
print("继续执行。。。")
'''
8517 主进程id号
继续执行。。。
当前进程的名称: new bee
8558 子进程id号
8554 副进程id号
11
'''
7、cpu的个数
为了利用cpu多核优势,一般需要看看有多少个cpu,定义相同数量的进程
import multiprocessing
print(multiprocessing.cpu_count())
#4
二、进程间数据的共享
进程是资源分配的最小单元,每个进程中都维护自己独立的数据,不共享。如果想要进程之间的数据进行共享,可以借助一些中介来实现。
当我们在子进程中修改列表数据时,主进程中的列表数据并没有发生变化,说明主进程和子进程之间是割裂的,数据并不共享。
import multiprocessing
def task(data):
data.append(666)
print(data) #[666]
if __name__ == "__main__":
data_list = []
p = multiprocessing.Process(target=task, args=(data_list,))
p.start()
p.join()
print("主进程:", data_list)
#主进程: []
(一)共享
1、share memory: Value / Array
通过Value和Array在子进程中更改元素的变量值,改变后的值同样也能共享到主进程中
字母所代表的含义:
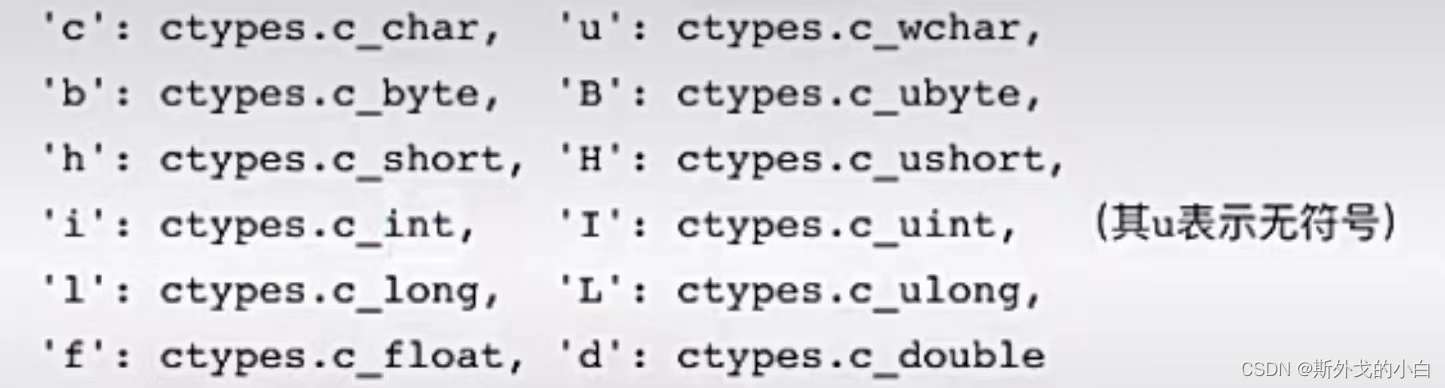
from multiprocessing import Process, Value, Array
def func(n, m1, m2):
n.value = 888
m1.value = 'a'.encode('utf-8')
m2.value = "武"
if __name__ == '__main__':
num = Value('i', 666)
v1 = Value('c')
v2 = Value('u')
p = Process(target=func, args=(num, v1, v2))
p.start()
p.join()
print(num.value) #888
print(v1.value) #a
print(v2.value) #武
Array可以更改数组的元素值
from multiprocessing import Process, Value, Array
def func(data_array):
data_array[0] = 666
if __name__ == '__main__':
arr = Array('i', [11, 22, 33, 44, 55, 66]) #数组:元素类型必须是int
p = Process(target=func, args=(arr, ))
p.start()
p.join()
print(arr[:])
#[666, 22, 33, 44, 55, 66]
2、Manager()
通过Manager来更改列表、字典的值
from multiprocessing import Process, Manager
def func(d, l):
d['高宇星'] = '18岁'
d['闫曦月'] = '68岁'
d[0.25] = None
l.append(666)
if __name__ == '__main__':
with Manager() as manager:
d = manager.dict()
l = manager.list()
p = Process(target=func, args=(d, l))
p.start()
p.join()
print(d) #{'高宇星': '18岁', '闫曦月': '68岁', 0.25: None}
print(l) #[666]
(二)交换
1、Queue
通过Queue将数据进行排队处理

import multiprocessing
def task(q):
for i in range(10):
q.put(i)
if __name__ == '__main__':
queue = multiprocessing.Queue()
p = multiprocessing.Process(target=task, args=(queue,))
p.start()
p.join()
print("主进程")
print(queue.get()) #0
print(queue.get()) #1
print(queue.get()) #2
print(queue.get()) #3
print(queue.get()) #4
print(queue.get()) #5
print(queue.get()) #6
print(queue.get()) #7
print(queue.get()) #8
print(queue.get()) #9
2、Pipe
通过构建一对连接对来交换信息
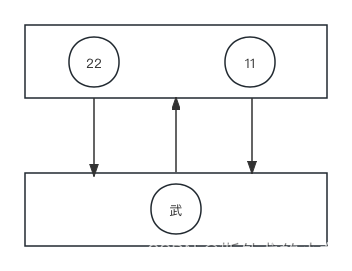
def task(chile_conn):
time.sleep(1)
chile_conn.send([111, 222, 333])
data = chile_conn.recv()
print("子进程接收:", data)
time.sleep(2)
if __name__ == '__main__':
parent_conn, child_conn = multiprocessing.Pipe()
p = multiprocessing.Process(target=task, args=(child_conn, ))
p.start()
info = parent_conn.recv()
print("主进程接收:", info)
parent_conn.send(666)
'''
主进程接收: [111, 222, 333]
子进程接收: 666
'''
三、进程锁
多个进程抢占某些操作时,为了防止操作出问题,可以通过进程锁来避免。
以下的循环代码就出现了这样的计算错误,f1.txt中写入的数字为20,正常来说如果循环了20次,每次都减1,循环结束之后应该为0,但是进程结束后得到的数值为19,说明出现在多进程中会抢占资源导致计算操作问题。
#进程锁
import time
import multiprocessing
def task():
#假设文件中保存的内容就是一个值:20
with open('f1.txt', mode='r', encoding='utf-8') as f:
current_num = int(f.read())
print("排队抢票了")
time.sleep(1)
current_num -= 1
with open('f1.txt', mode='w', encoding='utf-8') as f:
f.write(str(current_num))
if __name__ == '__main__':
for i in range(20):
p = multiprocessing.Process(target=task)
p.start()
为了避免这一问题,需要用锁来介入:
import time
import multiprocessing
def task(lock):
#假设文件中保存的内容就是一个值:20
print("开始")
lock.acquire()
with open('f1.txt', mode='r', encoding='utf-8') as f:
current_num = int(f.read())
print("排队抢票了")
time.sleep(1)
current_num -= 1
with open('f1.txt', mode='w', encoding='utf-8') as f:
f.write(str(current_num))
lock.release()
if __name__ == '__main__':
multiprocessing.set_start_method('spawn')
lock = multiprocessing.RLock() #进程锁
for i in range(20):
p = multiprocessing.Process(target=task, args=(lock, ))
p.start()
#spawn模式需要进行特殊处理,即需要sleep一会,不然会报错
time.sleep(7)
在spawn模式(windows系统中)需要特殊处理:time.sleep(),否则会报错。除了time.sleep(),还有另一个解决方案:做循环处理。如下方代码所示:
import time
import multiprocessing
def task(lock):
#假设文件中保存的内容就是一个值:20
print("开始")
lock.acquire()
with open('f1.txt', mode='r', encoding='utf-8') as f:
current_num = int(f.read())
print("排队抢票了")
time.sleep(1)
current_num -= 1
with open('f1.txt', mode='w', encoding='utf-8') as f:
f.write(str(current_num))
lock.release()
if __name__ == '__main__':
multiprocessing.set_start_method('spawn')
lock = multiprocessing.RLock() #进程锁
process_list = []
for i in range(20):
p = multiprocessing.Process(target=task, args=(lock, ))
p.start() #多进程开始运行
process_list.append(p)
#spawn模式需要进行特殊处理,即需要sleep一会,不然会报错
for item in process_list:
item.join() #多进程有序运行
四、进程池
在开发过程中,如果无限制得创建进程和线程则会在导致资源浪费的同时降低代码运行效率。如果有两百个任务,创建200个进程是现实的,因为最终也只有4个核进行处理,所以可以创建4个进程,200个任务循坏处理。
(一)构造进程池
在下述代码中,我们构造了4个进程,循环10次进程的执行,反复调用了进程池中构造的进程。
#构建进程池
import time
from concurrent.futures import ProcessPoolExecutor, ThreadPoolExecutor
def task(num):
print("执行", num, multiprocessing.current_process())
time.sleep(2)
if __name__ == '__main__':
pool = ProcessPoolExecutor(4)
for i in range(10): #10个任务进行循坏
pool.submit(task, i)
'''
执行 0 <SpawnProcess name='SpawnProcess-4' parent=18235 started>
执行 1 <SpawnProcess name='SpawnProcess-3' parent=18235 started>
执行 2 <SpawnProcess name='SpawnProcess-2' parent=18235 started>
执行 3 <SpawnProcess name='SpawnProcess-1' parent=18235 started>
执行 4 <SpawnProcess name='SpawnProcess-4' parent=18235 started>
执行 5 <SpawnProcess name='SpawnProcess-3' parent=18235 started>
执行 6 <SpawnProcess name='SpawnProcess-1' parent=18235 started>
执行 7 <SpawnProcess name='SpawnProcess-2' parent=18235 started>
执行 8 <SpawnProcess name='SpawnProcess-4' parent=18235 started>
执行 9 <SpawnProcess name='SpawnProcess-3' parent=18235 started>
''')
(二)shutdowm()阻塞
含义是:等待进程池中的任务都执行外币,再继续往后执行。
#构建进程池
import time
from concurrent.futures import ProcessPoolExecutor, ThreadPoolExecutor
def task(num):
print("执行", num, multiprocessing.current_process())
time.sleep(2)
if __name__ == '__main__':
pool = ProcessPoolExecutor(4)
for i in range(10):
pool.submit(task, i)
pool.shutdown(True) #阻塞
(三)回调
在进程结束时执行其他功能,可以使用回调函数。跟线程池回掉函数不同的是:在线程池中由子线程来调用,而进程池中由主进程来执行任务。
import time
from concurrent.futures import ProcessPoolExecutor
import multiprocessing
def task(num):
print("执行", num)
time.sleep(2)
return num
def done(res):
print(multiprocessing.current_process())
print(res)
time.sleep(1)
print(res.result())
time.sleep(1)
if __name__ == '__main__':
pool = ProcessPoolExecutor(4)
for i in range(8):
fur = pool.submit(task, i)
fur.add_done_callback(done) #done的调用由主进程处理(与线程池不同)
print(multiprocessing.current_process())
pool.shutdown(True)
(四)锁
如果进程池汇中要使用进程锁,multiprocessing.RLock()是不可用的,需要基于Manager中的Lock和RLock来实现。
import time
import multiprocessing
from concurrent.futures import ProcessPoolExecutor
def task(lock):
print("开始")
with lock:
with open('f1.txt', mode='r', encoding='utf-8') as f:
current_num = int(f.read())
print("排队抢票了")
time.sleep(1)
current_num -= 1
with open('f1.txt', mode='w', encoding='utf-8') as f:
f.write(str(current_num))
if __name__ == '__main__':
pool = ProcessPoolExecutor()
manager = multiprocessing.Manager()
lock_object = manager.RLock() #创建锁
for i in range(10):
pool.submit(task, lock_object)
五、协程
计算机中提供了:线程、进程(是真实存在的),而协程师程序员通过代码编写的方法(并不是真实存在的)。协程也被称为微线程,是一种用户态内的上下文切换技术,简而言之,是通过一个线程实现代码块相互切换执行(来回跳着执行)。
例如:
def func1():
print(1)
print(2)
def func2():
print(3)
print(4)
func1()
func2()
上述代码是普通的函数定义和执行,按流程分别执行两个函数中的代码,并先后输出:1、2、3、4。但如果介入协程技术就可以实现函数见代码切换执行,最终输出:1、3、2、4.
在python中由多种方式可以实现协程,例如:greenlet、
from greenlet import greenlet
def func1():
print(1) #第一步:输出1
gr2.switch() #第二步:切换到func2函数
print(2) #第三步:输出3
gr2.switch() #第四步:切换到func1函数
def func2():
print(3) #第二步:输出3
gr1.switch() #第三步:切换到func1函数
print(4) #第四步:输出4
gr1 = greenlet(func1)
gr2 = greenlet(func2)
gr1.switch() #第一步:执行func1函数
与上述代码有同等效果的代码有:
def func1():
yield 1
yield from func2()
yield 2
def func2():
yield 3
yield 4
f1 = func1()
for item in f1:
print(item)
虽然上述两种代码都实现了协程,但是这种编写代码的方式没有什么意义。这种来回切执行,很可能让程序运行速度变得更慢了(相比于串行而言)。
协程如何才能有意义?
不需要用户手动切换,而是遇到IO操作时自动切换。这就需要介绍async语法:
import asyncio
async def func1():
print(1)
await asyncio.sleep(2)
print(2)
async def func2():
print(3)
await asyncio.sleep(2)
print(4)
task = [
asyncio.ensure_future(func1()),
asyncio.ensure_future(func2())
]
loop = asyncio.get_event_loop()
loop.run_until_complete(asyncio.wait(task))
案例:基于协程的爬虫,需要pip install aiohttp

协程、线程和进程的区别:
线程:是计算机中可以被cpu调度的最小单元;
进程:是计算机资源分配的最小单元(进程为线程提供资源)
一个进程中可以有多个线程,同一个进程中的线程可以共享此过程中的资源。
由于CPython中GIL的存在:
线程适用于IO密集型操作;
进程适用于计算密集型操作。
协程,协程也可以被称为微线程,是一种用户态内的上下文切换技术,在开发中结合遇到IO自动切换,就可以通过一个线程实现开发操作,所以在处理IO操作时,协程比线程更节省开销(协程的开发难度大一些)。
现在很多python中的框架都在支持协程,比如:FastAPI、Tornado、Sanic、Django3、aiohttp等,企业开发使用的也越来越多。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









