







 本文探讨了ReLU激活函数导致的DeadReLUProblem,即神经元活性失效问题。通过实验展示问题表现,并分析其成因,包括激活函数特性及叠加层数的影响。文章介绍了如何通过调整学习率缓解问题,并详细讲解了nn.Sequential的使用和模型参数初始化技巧。
本文探讨了ReLU激活函数导致的DeadReLUProblem,即神经元活性失效问题。通过实验展示问题表现,并分析其成因,包括激活函数特性及叠加层数的影响。文章介绍了如何通过调整学习率缓解问题,并详细讲解了nn.Sequential的使用和模型参数初始化技巧。
提示:仅仅是学习记录笔记,搬运了学习课程的ppt内容,本意不是抄袭!望大家不要误解!纯属学习记录笔记!!!!!!
文章目录
前言
和Sigmoid、tanh激活函数不同,ReLU激活函数的叠加并不会出现梯度消失或者梯度爆炸,但ReLU激活函数中使得部分数值归零的特性却会导致另外一个严重的问——Dead ReLU Problem,也被称为神经元活性失效问题。
一、Dead ReLU Problem成因分析
1.Dead ReLU Problem直接表现
首先我们通过实验来观察神经元活性失效问题(Dead ReLU Problem)在建模过程中的直接表现。其实在上一节中,最后出现的ReLU叠加模型在迭代多次后在MSE取值高位收敛的情况,其实就是出现了神经元活性失效所导致的问题。
#设置随机数种子
torch.manual_seed(420)
features, labels = tensorGenReg(w=[2, -1], bias=False, deg=2)
train_loader, test_loader = split_loader(features, labels)
#实例化模型
torch.manual_seed(420)
relu_model3 = ReLU_class3(bias=False) #为了方便的观察神经元失效问题,我们创建不带截距的模型
#核心参数
num_epochs = 20
lr = 0.03
train_l, test_l = model_train_test(relu_model3,
train_loader,
test_loader,
num_epochs = num_epochs,
criterion = nn.MSELoss(),
optimizer = optim.SGD,
lr = 0.03,
cla = False,
eva = mse_cal)
# 绘制图像,查看MSE变化情况
plt.plot(list(range(num_epochs)), train_l, label='train_mse')
plt.plot(list(range(num_epochs)), test_l, label='test_mse')
plt.legend(loc=4)
plt.show()
print(relu_model3(features))

我们发现,模型在迭代多轮之后,训练误差和测试误差都在各自取值的高位收敛了,也就是误差不随模型迭代测试增加而递减。通过简单尝试我们不难发现,此时模型对所有数据的输出结果都是0。
2.Dead ReLU Problem成因分析
2.1 Dead ReLU Problem基本判别
神经元活性失效问题和ReLU激活函数本身特性有关。首先,我们观察ReLU激活函数函数图像与导函数图像。
# 绘制ReLU函数的函数图像和导函数图像
X = torch.arange(-5, 5, 0.1)
X.requires_grad=True
relu_y = torch.relu(X)
# 反向传播
relu_y.sum().backward()
# ReLU函数图像
plt.subplot(121)
plt.plot(X.detach(), relu_y.detach())
plt.title("ReLU Function")
# ReLU导函数图像
plt.subplot(122)
plt.plot(X.detach(), X.grad.detach())
plt.title("ReLU Derivative function")
plt.show()

我们进一步通过举例说明,现在有模型基本结构如下:设w1为第一层传播的权重,w2为第二层传播的权重,并且w1的第一列对应连接隐藏层第一个神经元的权重,w1的第二列对应连接隐藏层第二个神经元的权重,f为输入的特征张量,并且只有一条数据
w1 = torch.tensor([[0., 0], [-1, -2]], requires_grad=True)
w2 = torch.tensor([1., -1]).reshape(-1, 1)
w2.requires_grad = True
f = torch.tensor([[1, 2.]])
#第一次向前传播过程如下:
linear = torch.mm(f, w1)
print(linear)
#tensor([[-2., -4.]], grad_fn=<MmBackward0>)
#通过一个激活函数层
hidden = torch.relu(linear)
print(hidden)
#tensor([[0., 0.]], grad_fn=<ReluBackward0>)
#输出结果
out = torch.mm(hidden, w2)
print(out)
#tensor([[0.]], grad_fn=<MmBackward0>)
#l为f的真实标签,则损失函数和反向传播过程如下:
l = torch.tensor([[3.]])
loss = F.mse_loss(out, l)
loss.backward()
print(w1.grad)
'''
tensor([[0., 0.],
[0., 0.]])
'''
print(w2.grad)
'''
tensor([[0.],
[0.]])
'''
我们发现,当某条数据在模型中的输出结果为0时,反向传播后各层参数的梯度也全为0,此时参数将无法通过迭代更新。而进一步的,如果在某种参数情况下,整个训练数据集输入模型之后输出结果都是0,则在小批量梯度下降的情况下,每次再挑选出一些数据继续进行迭代,仍然无法改变输出结果是0的情况,此时参数无法得到更新、进而下次输入的小批数据结果还是零、从而梯度为0、从而参数无法更新…至此陷入死循环,模型失效、激活函数失去活性,也就出现了Dead ReLU Problem。


2.2 Dead ReLU Problem发生概率
当然,我们也可略微进行一些拓展。试想以下,出现Dead ReLU Problem问题的概率,其实是伴随ReLU层的增加而增加的。如果是两层ReLU层,模型结构如下:
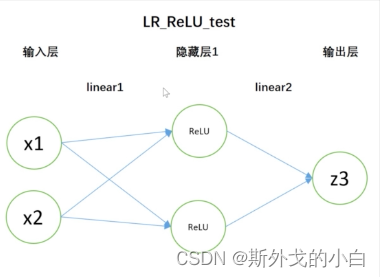
向前传播过程中,模型输出结果为: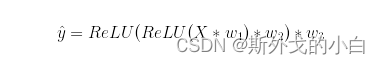

最终,我们可以通过如下表达式判别ReLU激活函数是否失效:
train_loader.dataset[:][0]
'''
tensor([[-1.4463, -0.6221],
[-0.4742, -0.2939],
[ 1.9870, 0.1949],
...,
[-1.6366, -2.1399],
[-1.8178, -1.4618],
[ 0.2646, 2.3555]])
'''
relu_model3(train_loader.dataset[:][0])
#所有的结果都为零
(relu_model3(train_loader.dataset[:][0]) == 0).sum()
#tensor(700) #训练数据一共有700个,结果为0的数据就有700个
当然,如果模型是带入偏差进行的建模,出现Dead ReLU Problem的时候模型输出结果恒为bias的取值。
二、通过调整学习率缓解Dead ReLU Problem
在所有的解决Dead ReLU Problem的方法中,最简单的一种方法就是调整学习率。尽管我们知道,ReLU叠加越多层越容易出现神经元活性失效,但我们可以简单通过降低学习率的方法来缓解神经元活性失效的问题。甚至可以说这是一种通用且有效的方法。
学习率作为模型重要的超参数,会在各方面影响模型效果,此前我们曾介绍学习率越小、收敛速度就越慢,而学习率过大、则又容易跳过最小值点造成模型结果震荡。对于ReLU激活函数来说,参数“稍有不慎”就容易落入输出值全为0的陷阱,因此训练过程需要更加保守,采用更小的学习率逐步迭代。当然学习率减少就必然需要增加迭代次数,但由于ReLU激活函数计算过程相对简单,增加迭代次数并不会显著增加计算量。
在这里插入代码片

减小学习率再次查看loss函数的收敛效果
#减小学习率
# 设置随机数种子
torch.manual_seed(420)
# 核心参数
num_epochs = 40
lr = 0.001
# 实例化模型
relu_model3 = ReLU_class3()
# 模型训练
train_l, test_l = model_train_test(relu_model3,
train_loader,
test_loader,
num_epochs = num_epochs,
criterion = nn.MSELoss(),
optimizer = optim.SGD,
lr = lr,
cla = False,
eva = mse_cal)
# 绘制图像,查看MSE变化情况
plt.plot(list(range(num_epochs)), train_l, label='train_mse')
plt.plot(list(range(num_epochs)), test_l, label='test_mse')
plt.title('lr=0.001')
plt.legend(loc = 1)
plt.show()

我们发现学习率调小之后,模型更能够避开神经元活性失效陷阱。关于更多学习率调整策略,我们会在后续完整介绍。
三、ReLU激活函数特性理解

关于“随机性”的作用,其实我们已经见过很多次了,在集成模型中,我们将在一定随机性条件下构建的、彼此不同的基分类器进行集成,从而创建一个效果明显好于单个基分类器的集成模型;在SGD中,我们采用每次带入随机部分数据的方法进行梯度下降迭代,从而使得迭代过程能够跳出局部最小值点;而在ReLU激活函数中,我们随机挑选部分参数进行迭代,从而完成数据的“非线性”转化,进而保证模型本身的有效性。也正因如此,ReLU激活函数也被称为非饱和激活函数。
我们可以观察上一节模型训练结束后各层参数的梯度。
四、nn.Sequential快速建模方法及nn.init模型参数自定义方法
1.nn.Sequential快速建模方法介绍
而此时的实例化,是nn.Sequential类的实例化,也就是说,通过nn.Sequential创建的模型本质上都是nn.Sequential的一个实例。
#设置随机种子
torch.manual_seed(25)
#构建模型
relu_test=nn.Sequential(nn.Linear(2, 2,bias=False), nn.ReLU(), nn.Linear(2, 1, bias=False))
print(list(relu_test.parameters()))
'''
[Parameter containing:
tensor([[ 0.3561, -0.4343],
[-0.6182, 0.5823]], requires_grad=True), Parameter containing:
tensor([[-0.1658, -0.2843]], requires_grad=True)]
'''
print(isinstance(relu_test, nn.Sequential))
#True
## 而此前创建的模型都是我们所创建的类的实例
print(isinstance(relu_model3, ReLU_class3))
#True
总而言之,我们不难发现,利用nn.Sequential进行模型创建在模型结构相对简单时可以大幅减少代码量,并且模型效果和先通过定义类、再进行实例化的模型效果相同,但该方法在定义高度复杂的模型、或者定义更加灵活的模型时就显得力不从心了。因此,对于新手,推荐先掌握利用类定义模型的方法,再掌握利用nn.Sequential定义模型的方法。
2.模型参数自定义方法
接下来,继续补充关于手动设置模型初始参数及模型参数共享的方法。首先,对于模型参数来说,parameters返回结果是个生成器(generator),通过list转化后会生成一个由可微张量构成的list。
通过修改可微张量方法修改参数
print(relu_test.parameters())
print(list(relu_test.parameters()))
print(list(relu_test.parameters())[0])
'''
Parameter containing:
tensor([[ 0.3561, -0.4343],
[-0.6182, 0.5823]], requires_grad=True)
a = list(relu_test.parameters())[0]
nn.init.uniform_(a, 0, 1)
print(list(relu_test.parameters())[0])
'''
Parameter containing:
tensor([[0.5933, 0.2911],
[0.2416, 0.5582]], requires_grad=True)
'''
使用init方法创建满足某种分布的参数
(1).nn.init.uniform_方法,新生成的参数服从均匀分布
print(relu_test.parameters())
print(list(relu_test.parameters()))
print(list(relu_test.parameters())[0])
w1 = torch.tensor([[0., 0], [-1, -2]])
w2 = torch.tensor([1., -1]).reshape(-1, 1)
#list(relu_test.parameters())[0].data = w1.t()
#list(relu_test.parameters())[1].data = w2.t()
# 查看修改结果
#print(list(relu_test.parameters()))
(2).nn.init.normal_方法,新生成的参数服从正态分布
print(relu_test.parameters())
print(list(relu_test.parameters()))
print(list(relu_test.parameters())[0])
'''
Parameter containing:
tensor([[ 0.3561, -0.4343],
[-0.6182, 0.5823]], requires_grad=True)
a = list(relu_test.parameters())[0]
nn.init.uniform_(a, 0, 1)
print(list(relu_test.parameters())[0])
'''
nn.init.normal_(list(relu_test.parameters())[0], 0, 1)
print(list(relu_test.parameters())[0])
'''
Parameter containing:
tensor([[-1.3812, 1.2157],
[ 0.0827, 0.5799]], requires_grad=True)
'''
(3)nn.init.constant_方法,新生成的参数值为某一常数
nn.init.constant_(list(relu_test.parameters())[0], 1)
print(list(relu_test.parameters())[0])
'''
Parameter containing:
tensor([[1., 1.],
[1., 1.]], requires_grad=True)
'''
#和下述表达式等效,然后再令其可导并替换原始参数值。
torch.full_like(list(relu_test.parameters())[0], 1)
'''
tensor([[1., 1.],
[1., 1.]])
'''


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









