







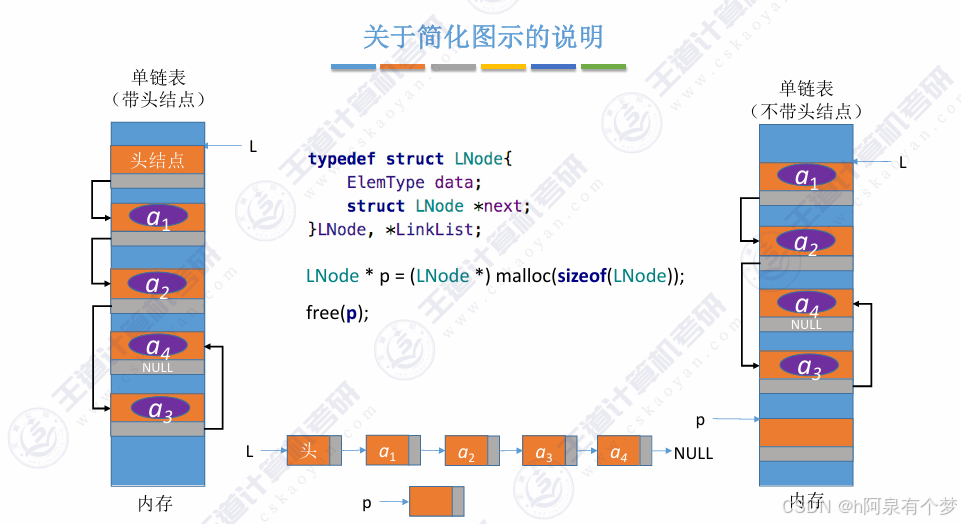
1、理论知识
2、可运行代码
(1)带头结点可运行代码
#include <stdio.h>
#include <stdlib.h>
#include <stdbool.h>
// 定义数据类型和链表结构体
typedef int ElemType;
typedef struct LNode {
ElemType data;
struct LNode *next;
} LNode, *LinkList;
// 初始化单链表
bool InitList(LinkList &L) {
L = (LNode *)malloc(sizeof(LNode)); // 分配头结点空间
if (L == NULL) { // 内存分配失败
return false;
}
L->next = NULL; // 头结点的指针域初始化为NULL
return true;
}
// 按位序插入元素
bool ListInsert(LinkList &L, int i, ElemType e) {
if (i < 1) {
return false; // i小于1时返回false
}
LNode *p = L; // p指向头结点
//因为 第一个指向的“头结点”为空,所以 j=0;
int j = 0; // 当前p指向的是第j个结点
// 寻找第i-1个结点
while (p != NULL && j < i - 1) {
p = p->next;
j++;
}
if (p == NULL) {
return false; // i值不合法
}
LNode *s = (LNode *)malloc(sizeof(LNode)); // 新建结点s
if (s == NULL) {
printf("内存分配失败\n");
return false;
}
s->data = e; // 将e赋值给s的数据域
s->next = p->next; // 将s的指针域指向p的后继结点
p->next = s; // 将p的指针域指向s
return true; // 插入成功
}
int main() {
LinkList L; //声明一个LinkList类型的变量L
InitList(L); // 调用InitList函数来初始化单链表,传入L作为参数
int position, value;//定义 position:第几个结点;value:要插入的值
// 提示用户输入插入位置和值
printf("请输入插入位置和值(例如:3 100),输入非正数结束插入:\n");
while (scanf("%d", &position) == 1 && position > 0) {
scanf("%d", &value);
if (ListInsert(L, position, value)){
printf("在第%d个位置插入元素%d成功\n", position, value);
}else{
printf("在第%d个位置插入元素%d失败\n", position, value);
}
printf("请输入下一个插入位置和值(输入非正数结束插入):\n");
}
// 打印链表
LNode *p = L->next; // 从头结点开始
printf("链表中的元素为:");
while (p != NULL) {
printf("%d ", p->data);
p = p->next;
}
printf("\n");
return 0;
}
(2)不带头结点可运行代码
#include <stdio.h>
#include <stdlib.h>
#include <stdbool.h>
// 定义数据类型和链表结构体
typedef int ElemType;
typedef struct LNode {
ElemType data;
struct LNode *next;
} LNode, *LinkList;
// 初始化单链表
bool InitList(LinkList &L) {
L = NULL; // 不创建头结点,直接将链表头指针设置为NULL
}
// 按位序插入元素
bool ListInsert(LinkList &L, int i, ElemType e) {
if (i < 1) {
return false; // i小于1时返回false
}
//插入第1个结点的操作 与其他结点的操作不同
if(i==1){
LNode *s = (LNode *)malloc(sizeof(LNode)); // 新建结点s
s->data = e;
s->next = L;
L=s; //头指针指向新结点
return true;
}
LNode *p = L; // 指针p 指向第1个结点(注意:这里的第1个结点不是头结点)
//因为“不带头结点”,如果链表非空,头指针已经指向第一个结点 ,所以 j=1;
int j = 1; // 当前p指向的是第几个结点,
// 循环找到第i-1个结点
while (p != NULL && j < i - 1) {
p = p->next;
j++;
}
if (p == NULL) {
return false; // i值不合法
}
LNode *s = (LNode *)malloc(sizeof(LNode)); // 新建结点s
if (s == NULL) {
printf("内存分配失败\n");
return false;
}
s->data = e; // 将e赋值给s的数据域
s->next = p->next; // 将s的指针域指向p的后继结点
p->next = s; // 将p的指针域指向s
return true; // 插入成功
}
int main() {
LinkList L;
InitList(L); // 初始化链表
int position, value;//定义 position:第几个结点;value:要插入的值
// 提示用户输入插入位置和值
printf("请输入插入位置和值(例如:3 100),输入非正数结束插入:\n");
while (scanf("%d", &position) == 1 && position > 0) {
scanf("%d", &value);
if (ListInsert(L, position, value)){
printf("在第%d个位置插入元素%d成功\n", position, value);
}else{
printf("在第%d个位置插入元素%d失败\n", position, value);
}
printf("请输入下一个插入位置和值(输入非正数结束插入):\n");
}
// 打印链表
LNode *p = L; // 从头指针L开始
printf("链表中的元素为:");
while (p != NULL) {
printf("%d ", p->data);
p = p->next;
}
printf("\n");
return 0;
}
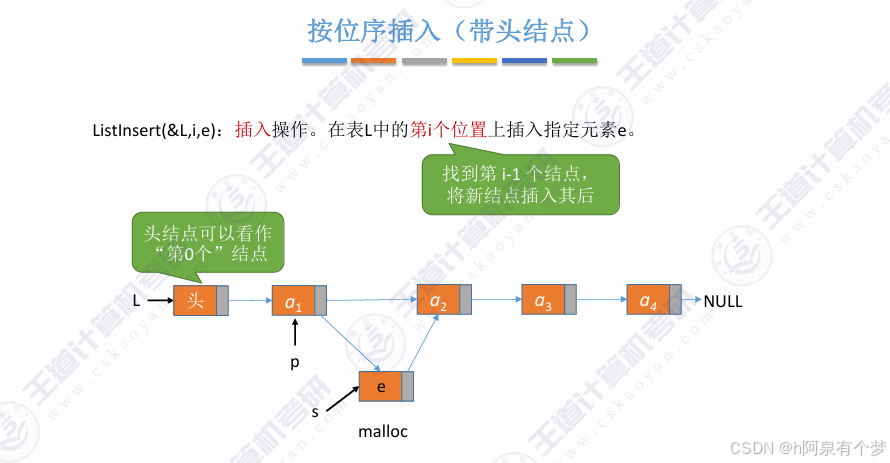
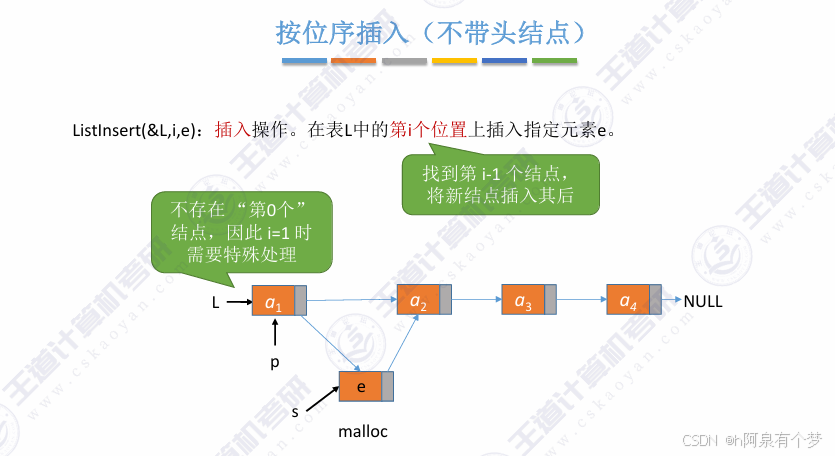
(3)两者代码区别部分
①初始化

②插入操作
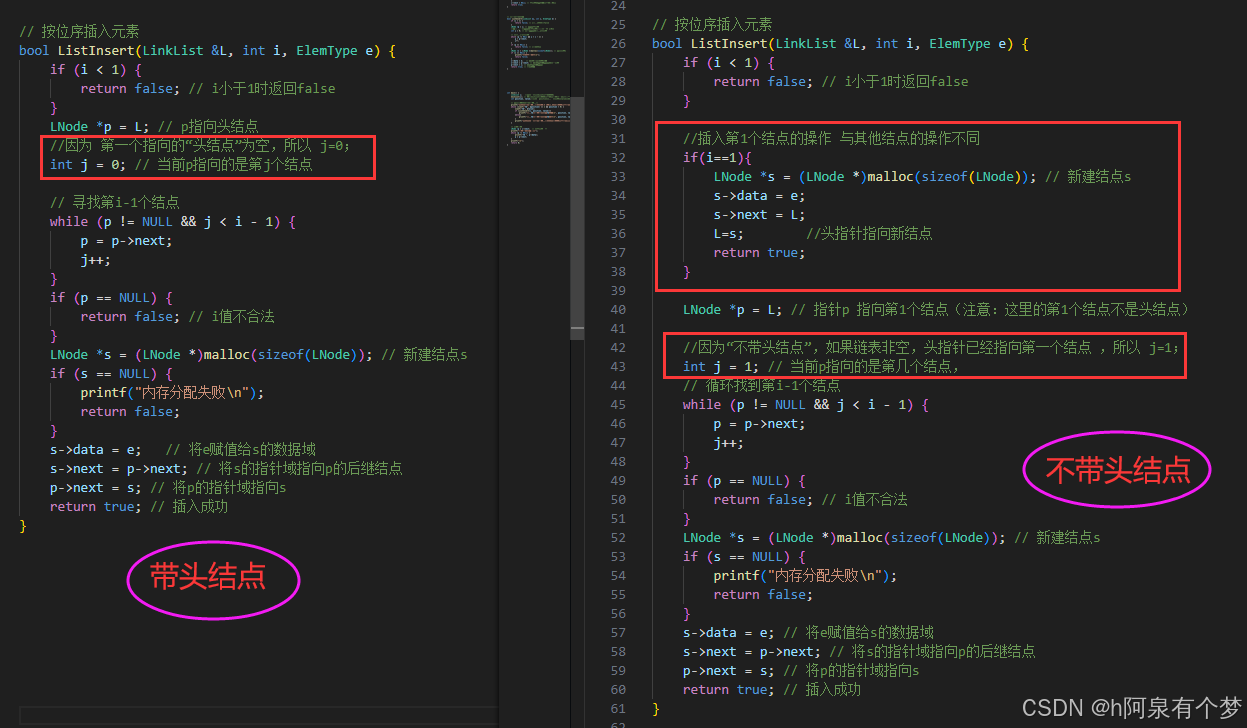
(4)代码解释
typedef int ElemType;
typedef struct LNode {
ElemType data;
struct LNode *next;
} LNode, *LinkList;
定义了一个结构体LNode,它包含一个整型数据域data和一个指向下一个LNode的指针next。LinkList是一个指向LNode的指针类型。
bool ListInsert(LinkList &L, int i, ElemType e) {
// ... 省略具体实现 ...
}
这个函数用于在链表L的第i个位置插入一个值为e的新节点。函数返回一个布尔值,表示插入操作是否成功。
int main() {
// ...
}
main函数是程序的入口点。它初始化链表,提示用户输入插入位置和值,并调用ListInsert函数执行插入操作。最后,打印出链表中的所有元素。
bool InitList(LinkList &L) {
L = (LNode *)malloc(sizeof(LNode)); // 分配头结点空间
if (L == NULL) { // 内存分配失败
return false;
}
L->next = NULL; // 头结点的指针域初始化为NULL
return true;
}
初始化函数InitList为链表分配了一个头结点,并将头结点的指针域设置为NULL。
bool ListInsert(LinkList &L, int i, ElemType e) {
// ... 省略具体实现 ...
}
在带头结点的链表中,插入操作首先检查i的合法性,然后通过循环找到第i-1个节点。之后,创建一个新的节点并将其插入到第i个位置。
bool InitList(LinkList &L) {
L = NULL; // 不创建头结点,直接将链表头指针设置为NULL
}
链表头指针直接被设置为NULL,表示链表为空。
if(i==1){
LNode *s = (LNode *)malloc(sizeof(LNode)); // 新建结点s
s->data = e;
s->next = L;
L=s; //头指针指向新结点
return true;
}
在不带头结点的版本中,如果插入位置是第一个,需要特殊处理,因为此时没有头结点可以作为插入点的前驱。因此,直接创建新结点并将其设置为链表的头结点。
两段代码的主要区别在于是否使用头结点。带头结点的链表在插入和删除操作时可以统一处理,而不带头结点的链表在处理第一个元素时需要特殊考虑。头结点可以简化链表操作,但会占用额外的内存空间。不带头结点的链表在空间上更高效,但代码实现上稍微复杂一些。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









