







摘要
数据驱动的创新是由最近的科学进步、快速的技术进步、制造成本的大幅降低以及对有效决策支持系统的重大需求推动的。这导致人们努力收集大量异构和多源数据,然而,并非所有数据都具有相同的质量或信息量。以前捕获和量化数据效用的方法包括信息价值(VoI)、信息质量(QoI)和互信息(MI)。本文引入了一种新的度量方法,用于量化大量越来越复杂的数据是否会增强、降低或改变它们在特定任务中的信息内容和效用。我们提出了一种新的信息论度量,称为数据价值度量(DVM),它量化了大型异构数据集的有用信息内容(能量)。DVM公式基于正则化模型,平衡数据分析值(效用)和模型复杂性。DVM可用于确定附加、扩展或扩充数据集在特定应用领域是否有益。根据用于查询数据的数据分析、推理或预测技术的选择,DVM量化了与增加数据大小或扩展其特征丰富性相关的信息增长或退化。DVM定义为保真度和正则化项的混合。保真度反映了样本数据在推理任务中的有用性。调节项表示相应推理方法的计算复杂性。受深度学习中信息瓶颈概念的启发,保真度项取决于相应的有监督或无监督模型的性能。我们对DVM方法进行了测试,测试了几种可选的有监督和无监督回归、分类、聚类和降维任务。实验验证中使用了具有弱信号和强信号信息的真实数据集和模拟数据集。我们的研究结果表明,DVM有效地抓住了分析价值和算法复杂性之间的平衡。DVM的变化揭示了算法复杂性和数据分析价值之间的权衡,即数据集的样本量和特征丰富性。DVM值可用于确定数据的大小和特征,以优化各种有监督或无监督算法的相对效用。
介绍
背景
大数据集正变得无处不在,强调了解决平衡信息效用、数据价值、资源成本、计算效率和推理可靠性的挑战的重要性[1]。这篇手稿通过开发一种新的度量方法来解决这个问题,称为数据值度量(DVM),它量化了大型复杂数据集的能量或信息内容,可以将其用作判断是否追加、扩展或者在特定的应用领域中,增加数据大小或复杂性可能是有益的。在实践中,DVM提供了一种机制来平衡或权衡一对相互竞争的优先级(1)与增加或减少异构数据集(样本大小)和控制采样错误率相关的成本或权衡,(2)与相应科学推断相关的预期收益(例如,决策改进)或损失(例如,精度降低或可变性增加)。DVM方法的计算复杂度与互信息的计算复杂度成正比,互信息的计算复杂度与数据大小成线性关系。因此,DVM复杂性直接由用于获得分类、回归或聚类结果的推理方法或技术决定,其本身可能是非线性的。因此,DVM计算不会给标准分析协议增加大量开销。
尽管对于有监督和无监督的推理任务,存在几种性能度量,但很难使用已建立的方法来推断每个特定推理任务的数据的充分性。例如,可以对分类任务使用精度度量。假设非随机、非平稳或非齐次数据集的准确率达到70%。然后,问题是,我们是否可以通过添加更多样本或更多特征来提高准确性,或者使用替代模型来增加结果推断的价值。一般来说,仅通过考虑给定数据集上的特定性能指标,很难回答此类问题。以下总结了以前测量数据质量的几种方法。
相关工作
之前的几项研究提出了评估给定数据集信息增益的指标。例如,信息价值(VoI)分析最初在[2]中提出,在[3–5]中概述,它是一种决策理论统计框架,表示基于额外的预期信息[6]的预期推理准确性增加或损失减少。VoI方法的三种基本类型包括:(1)在简化的参数分布限制下,线性目标函数的推理和建模案例,这限制了其广泛的实用性[3,7];(2) 估计部分完全信息(EVPPI)期望值的方法,包括将参数空间划分为更小的子集,并在子集内对局部邻域进行恒定和最优推理[8,9];(3)逼近预期推断的高斯过程回归方法[10–12]。更具体地说,对于特定参数 φ,EVPPI 是当 φ 被完美估计时的预期推理增益或损失减少。 由于完美的 φ 事先是未知的,这种损失期望的减少被用于整个参数空间 φ∈�:
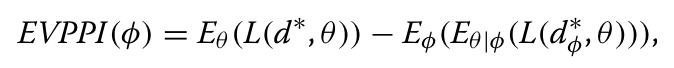
其中d是决定、推理或行动,d∗φ是已知φ时得到的最佳推断,θ是模型参数向量,E是期望值,L(d,θ)是似然函数[6]。请注意,VoI技术主要适用于特定类型的问题,例如决策理论背景下的证据合成。此外,它们的计算复杂度往往很高,需要嵌套的蒙特卡罗程序。
另一项相关研究[13]将理论(总体)参数与其样本驱动估计(统计学)之间的差异(误差)分解为三个独立分量。如果θ和ˆθ分别代表感兴趣的理论特征(例如,总体平均值)及其基于样本的参数估计(例如,样本算术平均值),则误差可以标准分解为:
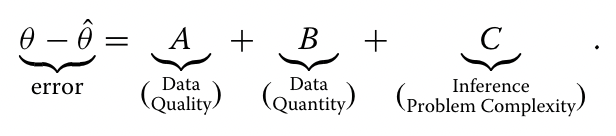
假设J是一个(均匀的)随机子集,它对整个(有限的,N)总体中的样本进行索引。对于样本{Xi:j∈In}中,Rj是一个随机样本指示符函数(值为0或1),用于捕获是否j∈In。当然∑Nj=1Rj=n,X是一个多维设计矩阵,捕捉数据(特征)的属性,g:X→R是一个连接图,允许我们计算样本(例如,用于矩计算的多项式函数或用于分布函数的指示函数),gj=g(Xj)是第j个特征的映射,A=A(g,R)是Rj和Gj之间关联的度量,采样率f=EJ(RJ)=n/N(样本与总体大小的比率),B=√(1−f)/f和C是一种表示估计基于样本的参数(ˆθ)难度的方法。
贝叶斯错误率是另一个量化内在分类极限的指标。在分类问题中,贝叶斯错误率代表了任何分类器所获得的最小分类错误[14,15]。贝叶斯错误率仅取决于类的分布,并表征了任何分类器的最小可实现错误。之前的几项研究提出了有效的贝叶斯错误率估
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









