







随着充电桩业务的逐年快速铺开,数据量呈现出爆炸性的增长态势。在业务初期,项目团队采用MongoDB和PolarDB这种事务性数据库来支撑业务运行。然而,随着数据量的急剧增加,这些数据库在处理百万级、千亿级数据量的分析、聚合任务时已无法满足业务对数据处理速度和准确性的高要求。
为了应对这一挑战,项目团队采用专门的分析型数据架构,它专注于处理非事务性质的任务,如数据分析和聚合,能够更高效地处理大规模数据,为业务提供更加准确、及时的数据支持。
本文重点介绍充电桩项目的亿级数据处理和分析,并详细阐述从关系型数据库到分析型数据库的整个演进过程。
01 数据下载优化
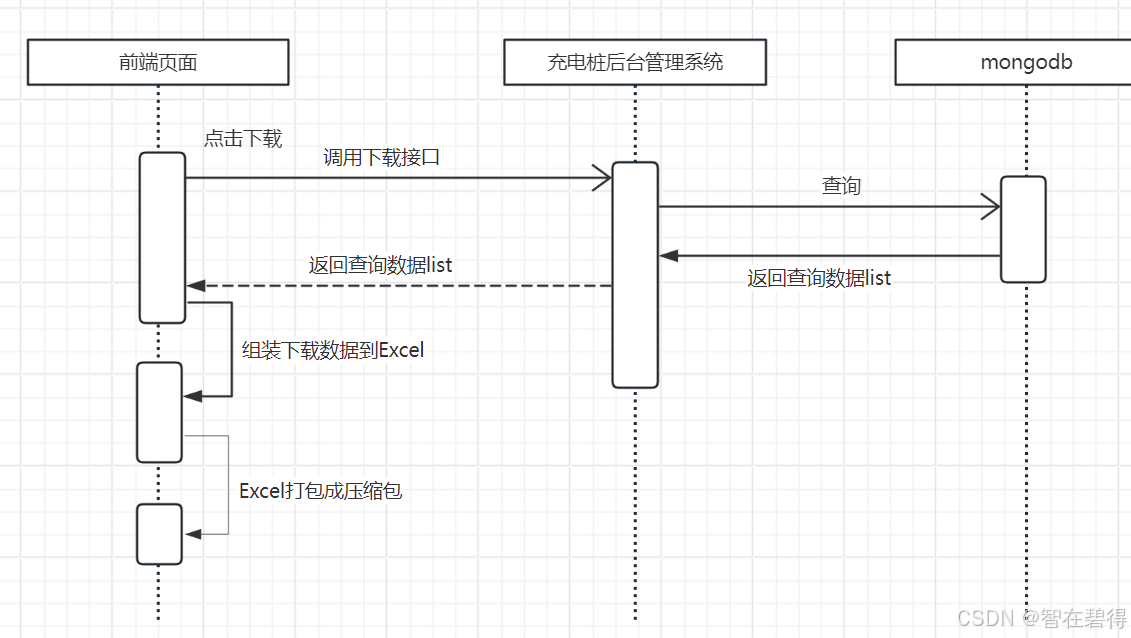
充电桩项目初期下载时序图
在充电桩项目初期,项目团队采用MongoDB作为主要数据库。在该架构下,前端调用下载接口请求数据,后端服务会立即访问MongoDB或PolarDB,检索并返回所有相关数据。前端接收到这些数据后,会负责执行Excel写入操作以及数据压缩处理,最终生成一个可供用户直接下载的文件。然而,这种操作方式在实际应用过程中面临以下挑战:
-
数据传输时间过长:由于下载的数据量大,可能会超出F5负载均衡器设定的常规连接时间限制(2分钟),导致连接中断;
-
服务资源占用过高:大规模数据的处理会占用服务器的CPU和内存资源
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









