







- 创建项目,初始化目录结构。
- 创建项目名称为pachong。
- 运行
npm init -y初始化项目。 - 修改package.json文件中的type属性为module。
- 安装 npm 包:
npm install puppeteer#爬虫 | 自动化UI测试 - 首先确保你的电脑上有python3环境
- 安装两个python包
pip install wordcloud#生成词云图pip install jieba#中文分词 (⚠️注意:如果安装的是python3,你的python包管理工具是pip3而不再是pip)
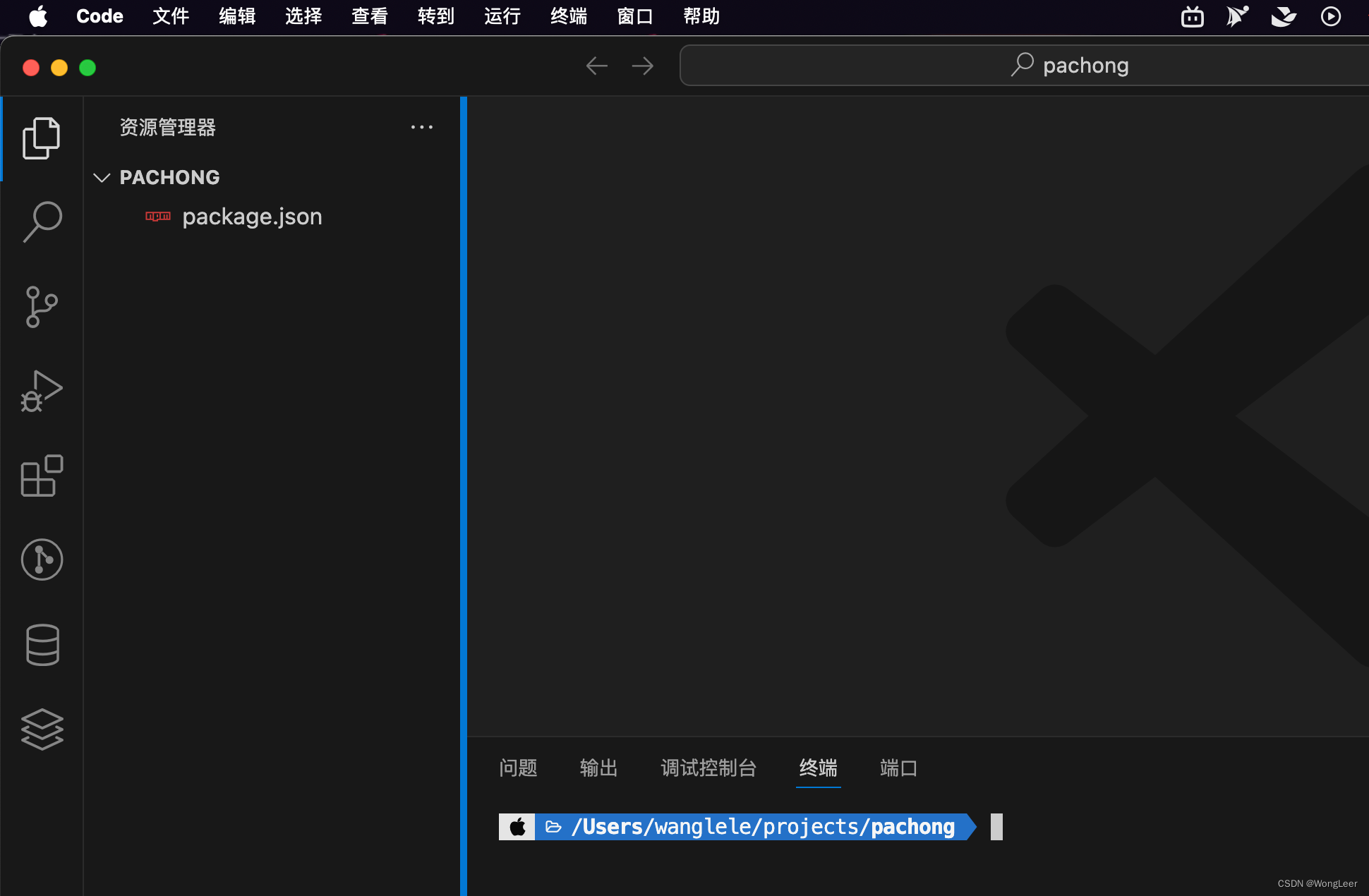
- 创建src目录。
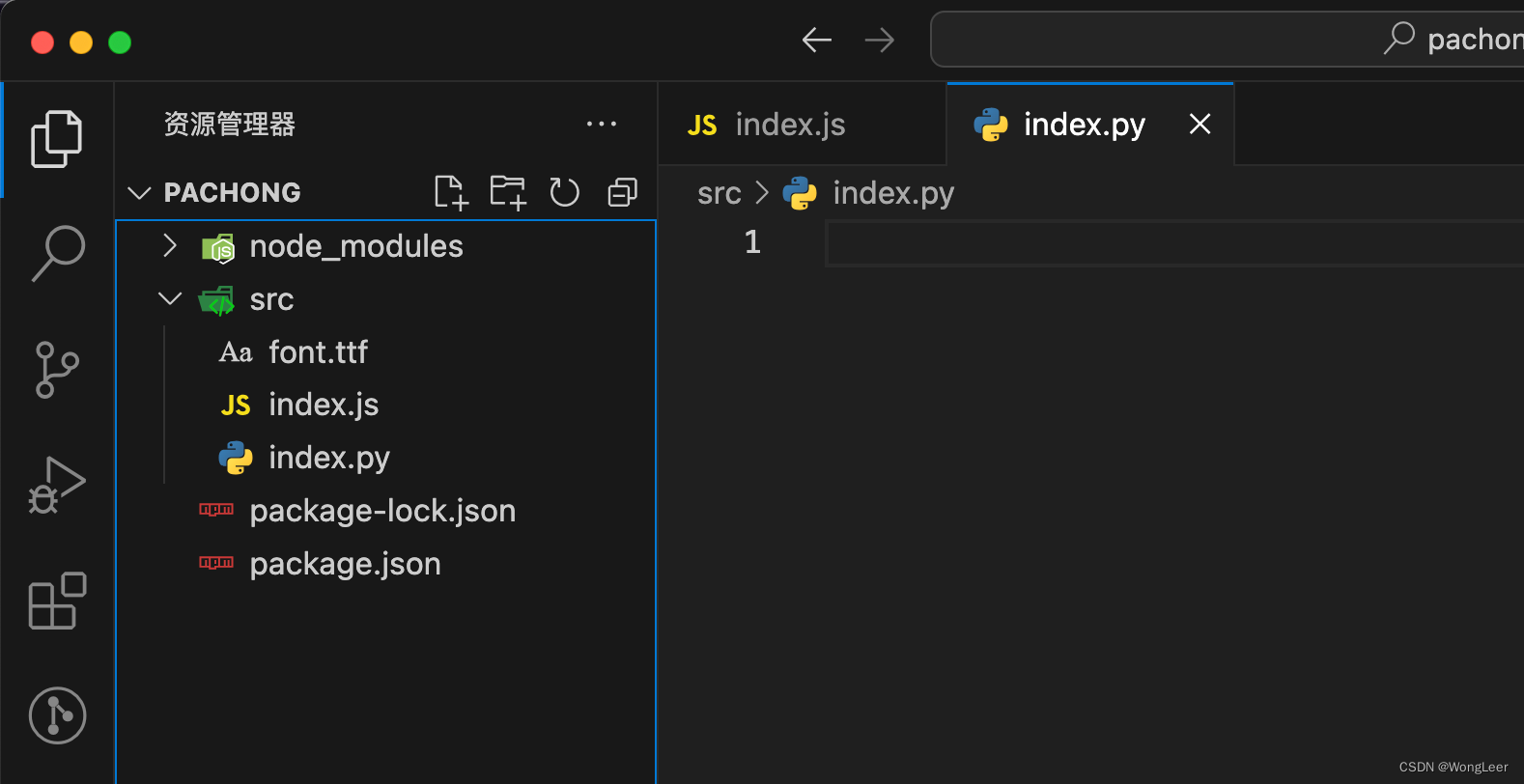
- 新建两个文件分别用于书写nodeJs代码和python代码。
- 在网上找一个自己喜欢的字体ttf文件,准备让生成的词图云使用。
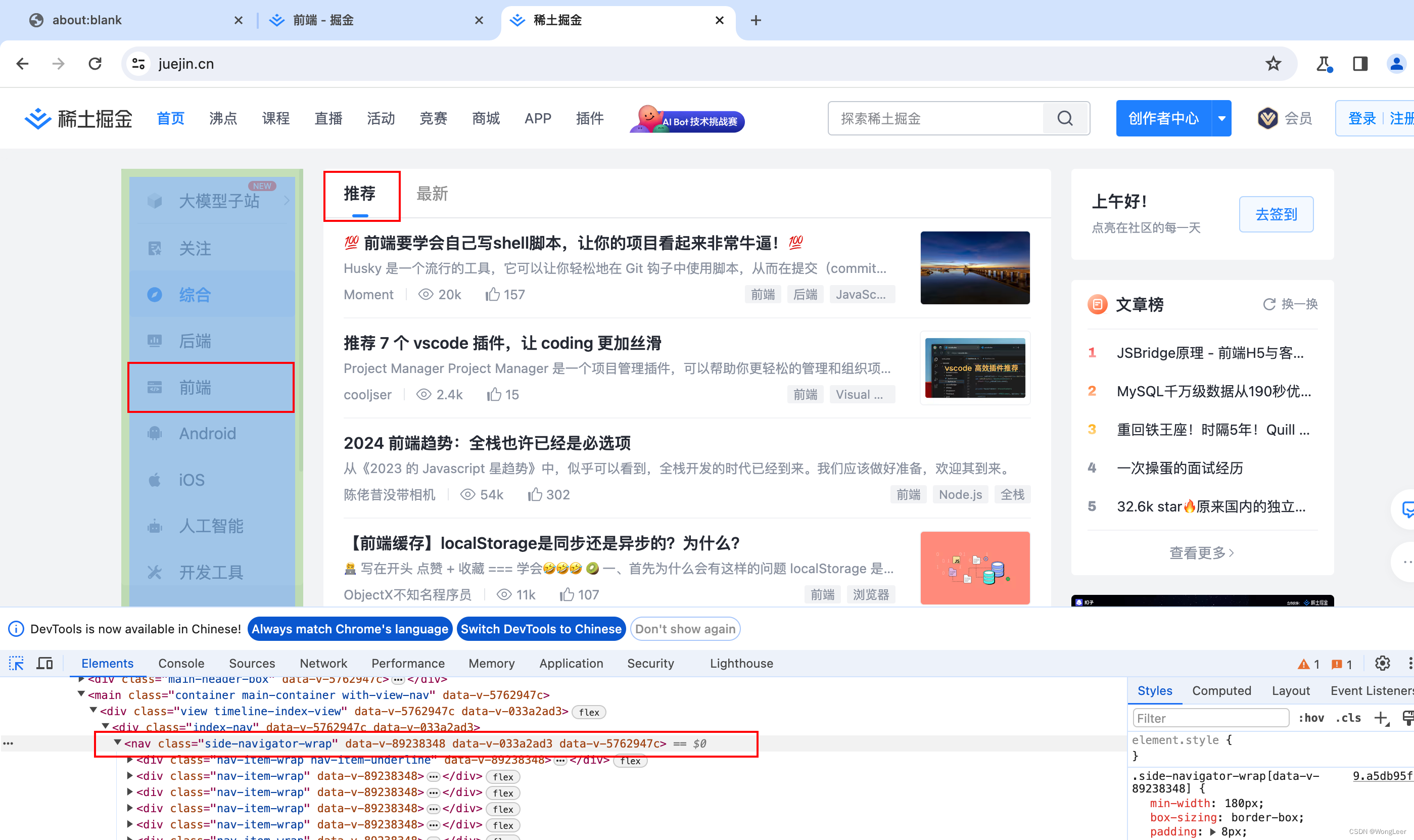
- 介绍我们要爬取的内容
- 我们要爬取的是掘金首页的导航栏 -> 前端模块 -> 推荐
- 爬取前端(或者其他指定模块)推荐模块里所有文章的标题,并且依靠python脚本提供的分词和词图云的能力最终生成看板。
- source code
index.js
import puppeteer from "puppeteer"; // puppeteer 的每一个操作都是异步的
import {
spawn } from "node:child_process";
const keywords = process.argv[2]; // 获取在终端执行 node index.js keywords 中的 keywords
// 1. 创建一个浏览器实例
const browser = await puppeteer.launch({
headless: false, // 关闭无头模式 (什么是无头模式:无需打开浏览器就可以直接爬取,我们做demo还是想看到效果因此暂时关掉)
});
// 2. 创建一个页面实例
const page = await browser.newPage();
// 3. 跳转页面
await page. 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 7857
7857

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











