







第二门课 第二周
一、Mini-batch 梯度下降
向量化可以较快地处理m个样本,但是若m很大的话(比如m等于500万,到
),处理速度还是很慢。针对这一现象,将五百万个样本分割为一些小的子集(比如分割为5000个子集(𝑋 {1}至𝑋 {5000}),这些子集被取名为 mini-batch,每一个子集有1000个样本(比如第一个子集𝑋 {1}表示
到
))。
它不会总朝向最小值靠近,但它比随机梯度下降要更持续地靠近最小值的方向。
如果样本数m比较小(小于2000),直接使用batch梯度下降法;m较大时,一般的mini-batch 大小为 64 到 512(2的n次方),尝试不同的n,然后看能否找到一个让梯度下降优化算法最高效的大小。
二、动量梯度下降法
指数加权平均:V𝑡 = 𝛽*V(𝑡−1) + (1 − 𝛽)*𝜃𝑡
动量梯度下降法:是计算梯度的指数加权平均数,并利用该梯度更新权重。
公式为:
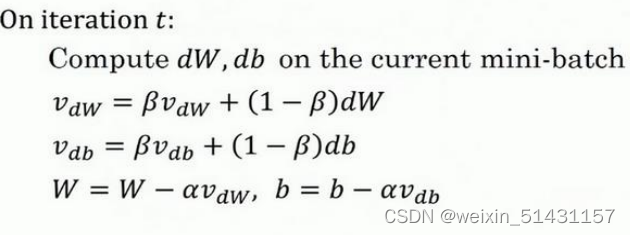
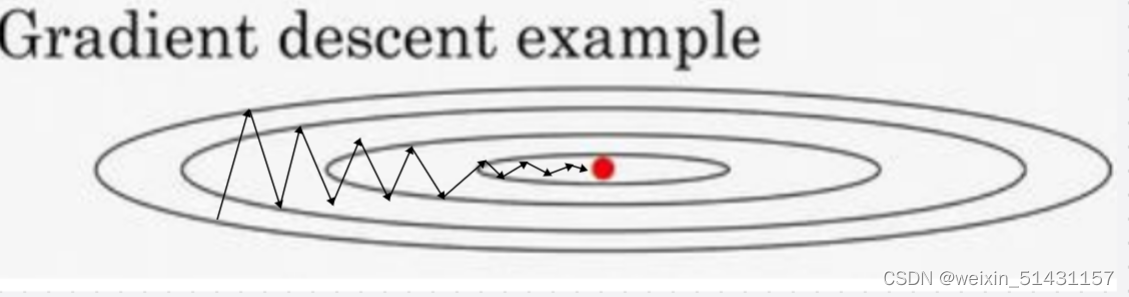
迭代效果如下图所示,纵向震荡较大,横向迭代速度需提高。
三、RMSprop
RMSprop,全称是均方根,将微分进行平方,然后最后使用平方根。
减缓纵轴方向的学习,同时加快横轴方向的学习
公式为:
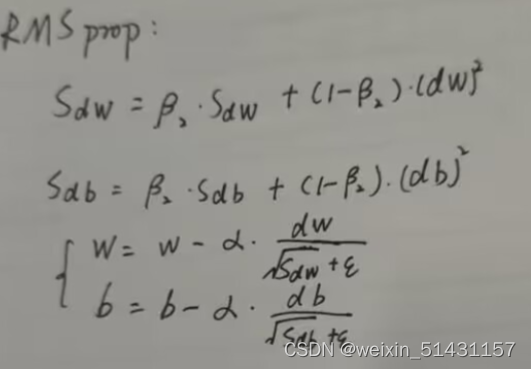
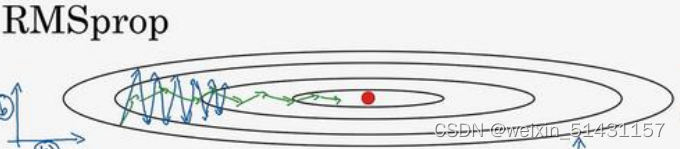
RMSprop减缓纵轴方向的学习,同时加快横轴方向的学习。
四、Adam算法
Adam 优化算法基本上就是将 Momentum 和 RMSprop 结合在一起。
Momentum 更新了超参数𝛽1(一般取值为0.9),RMSprop 更新了超参数𝛽2(一般取值为0.999),式中ε的作用是为了确 保数值稳定(无论何时都不会除以一个很小很小的值),值设为
公式为:

torch.optim.Adam() #pytorch运用
五、学习率衰减
随时间慢慢减少学习率,称为学习率衰减。
torch.optim.lr_scheduler.LambdaLR #pytorch运用


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









