







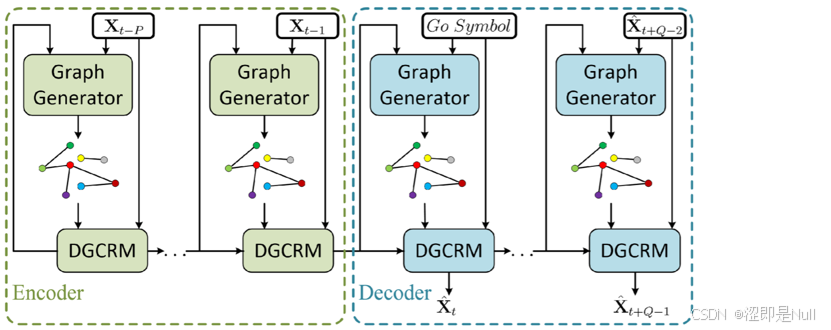
一、模型整体架构
1 图生成器(Graph Generator)
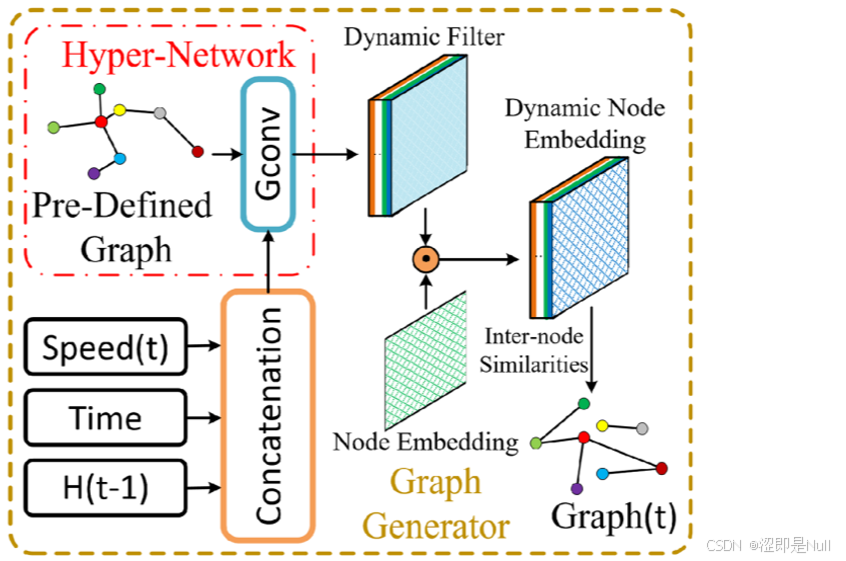
图生成器是模型的核心创新组件之一。它由基于超网络(Hyper - Network)的结构组成,在每个时间步,超网络根据当前时刻的车速(Speed)、时段编码(Time)和前一时刻的隐藏状态(),沿特征维度拼接(Concatenation)后可表示为动态节点特征
,然后把它整个网络模型的输入
(
为输入特征维度)。
x = input
x = x.transpose(1, 2).contiguous() # (batch_size, features, num_nodes) -> (batch_size, num_nodes, features)
hyper_input = torch.cat(
(x, Hidden_State.view(-1, self.num_nodes, self.hidden_size)), 2) 在实际道路网络中,交通流是双向的,某个路段的流量不仅受到其前驱路段的影响,还可能受到后继路段的影响。所以将 输入超网络(Hyper-Network),超网络中包含一组预定义图
和
(Pre-Defined Graph),
为
的转置。这样,模型不仅能学习到前驱节点如何影响当前节点,还能捕捉到当前节点对前驱节点的反馈,从而提升预测能力。
然后通过图卷积(Gconv)()生成动态滤波器(Dynamic Filter)。这里有一点需要注意,超网络还会从
中学习两种不同的网络参数
和
。一个用于生成源节点的动态滤波器,另一个用于生成目标节点的动态滤波器。
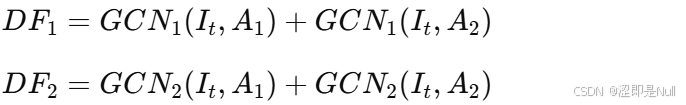
self.GCN1_tg = gcn(dims_hyper, gcn_depth, dropout, *list_weight, 'hyper')
self.GCN2_tg = gcn(dims_hyper, gcn_depth, dropout, *list_weight, 'hyper')
self.GCN1_tg_1 = gcn(dims_hyper, gcn_depth, dropout, *list_weight, 'hyper')
self.GCN2_tg_1 = gcn(dims_hyper, gcn_depth, dropout, *list_weight, 'hyper')
# 计算DF1和DF2
filter1 = self.GCN1_tg(hyper_input, predefined_A[0]) +
self.GCN1_tg_1(hyper_input, predefined_A[1])
filter2 = self.GCN2_tg(hyper_input, predefined_A[0]) +
self.GCN2_tg_1(hyper_input, predefined_A[1]) 节点嵌入 E 通常携带静态的、预定义的拓扑结构信息,而动态滤波器 则反映了实时的动态信息。因此,两个动态滤波器
、
再分别和源节点嵌入
、目标节点嵌入
进行哈达玛乘积,生成动态节点嵌入
、
(Dynamic Node Embedding)。这样就能得到既包含静态先验又适应当前状态的动态节点嵌入。
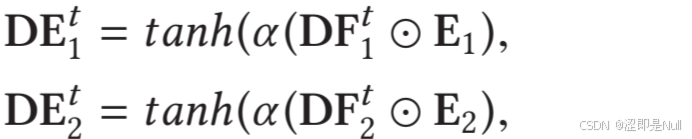
self.emb1 = nn.Embedding(self.num_nodes, node_dim)
self.emb2 = nn.Embedding(self.num_nodes, node_dim)
nodevec1 = self.emb1(self.idx)
nodevec2 = self.emb2(self.idx)
# 计算DE1和DE2
nodevec1 = torch.tanh(self.alpha * torch.mul(nodevec1, filter1))
nodevec2 = torch.tanh(self.alpha * torch.mul(nodevec2, filter2)) 最后, 利用节点嵌入之间的相似性计算动态图邻接矩阵 。
![]()
其中, 表示每个源节点与每个目标节点之间的相似性或关联强度,而
则计算了相反方向的相似性。通过相减,可以捕捉到节点间关联的方向性(即非对称性),这在实际交通网络中十分重要,因为信息传递往往存在方向性。
# 计算DAt
a = torch.matmul(nodevec1, nodevec2.transpose(2, 1)) - torch.matmul(nodevec2, nodevec1.transpose(2, 1))
adj = F.relu(torch.tanh(self.alpha * a))2 动态图卷积循环模块(DGCRM)
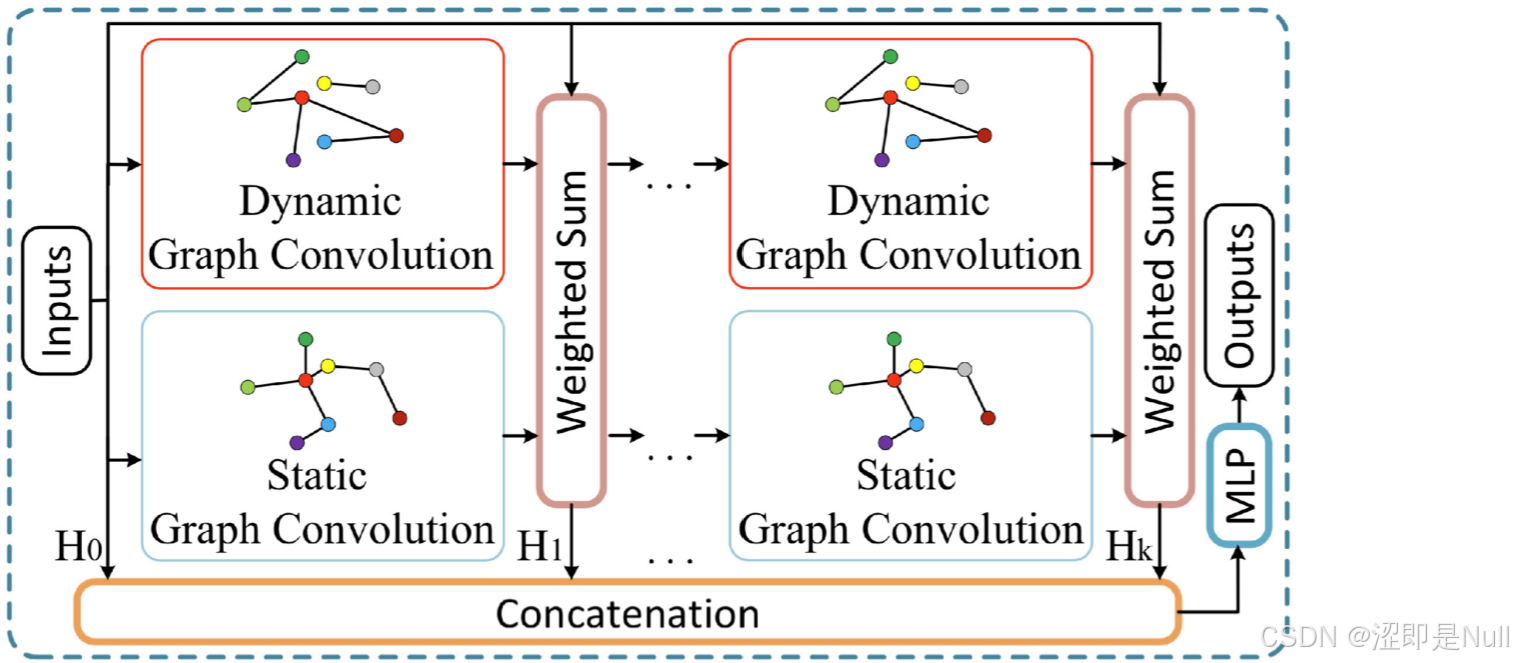
在图生成器中,我们得到了动态图邻接矩阵 。这里需要再次结合一次预定义的静态图。之前超网络中也结合过一次静态图,它的作用主要让生成的动态滤波器“知道”基础的、长期不变的拓扑结构,从而使得生成的动态节点嵌入具有一定的稳定性和合理性。而这里再次结合静态图,是为了补充动态信息可能存在的不足或噪声干扰:动态滤波器生成的动态图主要反映实时变化,但在一些情况下,实时数据可能不稳定或者受到噪声影响,而静态图提供的是相对稳定的全局结构约束。前后两者共同作用,构成了既敏感于动态变化又稳健于全局结构的联合表示。
在开始图卷积之前,需要对之前计算出的 做一些处理:1. 添加自连接。即使没有邻居,该节点仍然能保留自己的特征信息;2. 归一化。防止节点特征数值太大,不稳定。
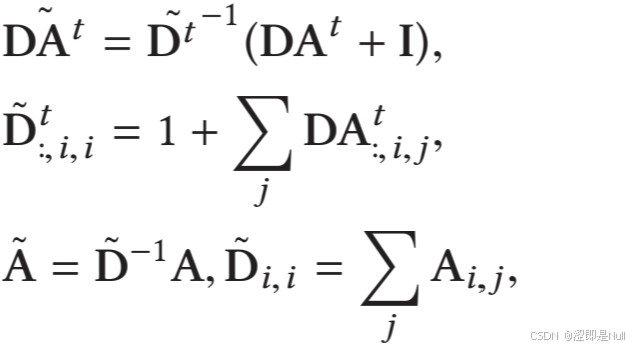
def preprocessing(self, adj, predefined_A):
adj = adj + torch.eye(self.num_nodes).to(self.device) # 给邻接矩阵添加自连接
adj = adj / torch.unsqueeze(adj.sum(-1), -1) # 按行归一化
return [adj, predefined_A]
# 将adj提前处理并再次结合静态图
adp = self.preprocessing(adj, predefined_A[0])
adpT = self.preprocessing(adj.transpose(1, 2), predefined_A[1]) 接下来,就可以进行图卷积了。 为归一化后的静态图,
为上一步预处理后的动态图。
、
、
为可学习的超参数。
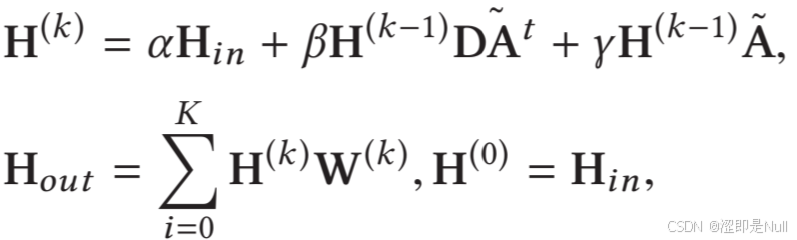
h = x
out = [h]
for _ in range(self.gdep):
h = self.alpha * x +
self.beta * self.gconv(h, adj[0]) +
self.gamma * self.gconv_preA(h, adj[1])
out.append(h)最后,用动态图卷积模块替换 GRU 中的矩阵乘法,即可得到 DGCRM。
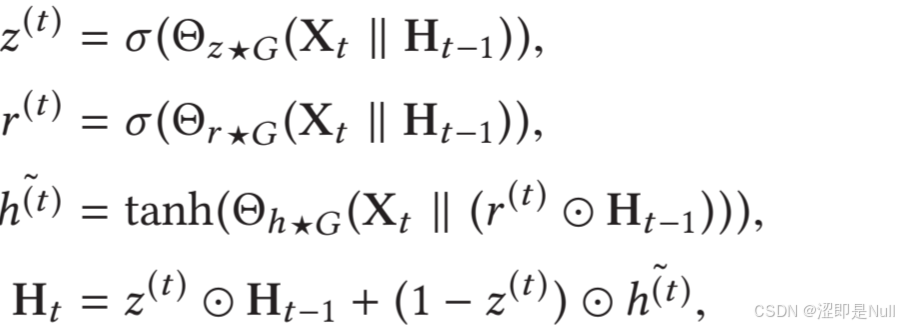
combined = torch.cat((x, Hidden_State), -1)
z = F.sigmoid(self.gz1(combined, adp) + self.gz2(combined, adpT))
r = F.sigmoid(self.gr1(combined, adp) + self.gr2(combined, adpT))
temp = torch.cat((x, torch.mul(r, Hidden_State)), -1)
Cell_State = F.tanh(self.gc1(temp, adp) + self.gc2(temp, adpT))
Hidden_State = torch.mul(z, Hidden_State) + torch.mul(1 - z, Cell_State)二、训练策略
作者在训练时使用了课程学习(Curriculum Learning)。其核心思想是“由易到难”,让模型先学习简单的任务,再逐步过渡到更复杂的任务。
在训练初期,解码器只预测较短的序列(即只计算前 个时间步,而
小于整个预测序列长度 Q)。这样,模型在刚开始时只需要处理较少的循环步骤,从而减少了计算量和内存开销。随着训练的进行,模型逐渐累积了对短期依赖的较好把握,此时我们逐步增加解码器需要预测的时间步数。这样模型就从处理简单的短期预测任务,逐渐适应长序列预测的复杂性。
self.iter = 0 # 记录训练了多少个批次
self.task_level = 1 # 预测步长(递增)
self.step = step_size # 每step个批次增加一个 task_level
self.seq_out_len = seq_out_len # 预测序列长度
def train(self, input, real_val, ycl, idx=None, batches_seen=None):
self.iter += 1
if self.iter % self.step == 0 and self.task_level < self.seq_out_len:
self.task_level += 1
# 开始训练
self.model.train()
self.optimizer.zero_grad() # 清空梯度,防止梯度累积
# 使用课程学习
output = self.model(input,
idx=idx,
ycl=ycl,
batches_seen=self.iter,
task_level=self.task_level)
······

















 578
578

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









