






YNNU CLOUDCAL TASK FHT
1.创建Spark网络
sudo docker network rm spark_network
sudo docker network create --driver bridge --subnet 172.19.0.0/16 --gateway 172.19.0.1 spark_network
2.软件包准备
把dockerfile文件夹,sm文件夹,sw1,sw2文件夹, hosts文件,sshd_config文件放在/root/beam/work/spark:
sw1,sw2,sm文件夹为空,用于存放相应节点的文件
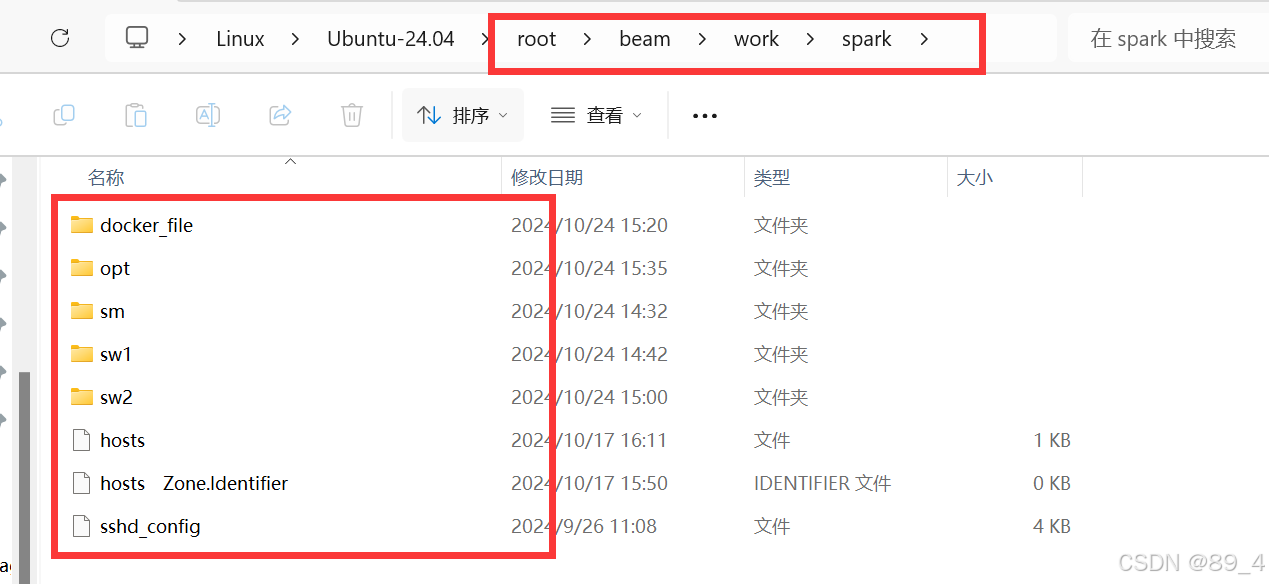
docker_file中的Dockerfile:
FROM ubuntu:latest
RUN sed -i 's|http://archive.ubuntu.com/ubuntu/|https://mirrors.tuna.tsinghua.edu.cn/ubuntu/|g' /etc/apt/sources.list
RUN apt-get update -y && apt install -y openssh-server
RUN apt install -y nano vim
RUN echo "root:root" | chpasswd
RUN mkdir /startup
RUN echo "#!/bin/bash\nservice ssh start\n/bin/bash" > /startup/startup.sh
RUN chmod -R 777 /startup/startup.sh
WORKDIR /root/
CMD ["/startup/startup.sh"]
hosts文件:
127.0.0.1 localhost
::1 localhost ip6-localhost ip6-loopback
fe00::0 ip6-localnet
ff00::0 ip6-mcastprefix
ff02::1 ip6-allnodes
ff02::2 ip6-allrouters
172.19.0.2 sm
172.19.0.3 sw1
172.19.0.4 sw2
sshd_config文件:
# This is the sshd server system-wide configuration file. See
# sshd_config(5) for more information.
Include /etc/ssh/sshd_config.d/*.conf
PermitRootLogin yes
KbdInteractiveAuthentication no
UsePAM no
#AllowAgentForwarding yes
#AllowTcpForwarding yes
#GatewayPorts no
X11Forwarding yes
#X11DisplayOffset 10
#X11UseLocalhost yes
#PermitTTY yes
PrintMotd no
# Allow client to pass locale environment variables
AcceptEnv LANG LC_*
# override default of no subsystems
Subsystem sftp /usr/lib/openssh/sftp-server
把Hadoop和jdk压缩包上传到/root/beam/work/spark/opt,然后解压得。
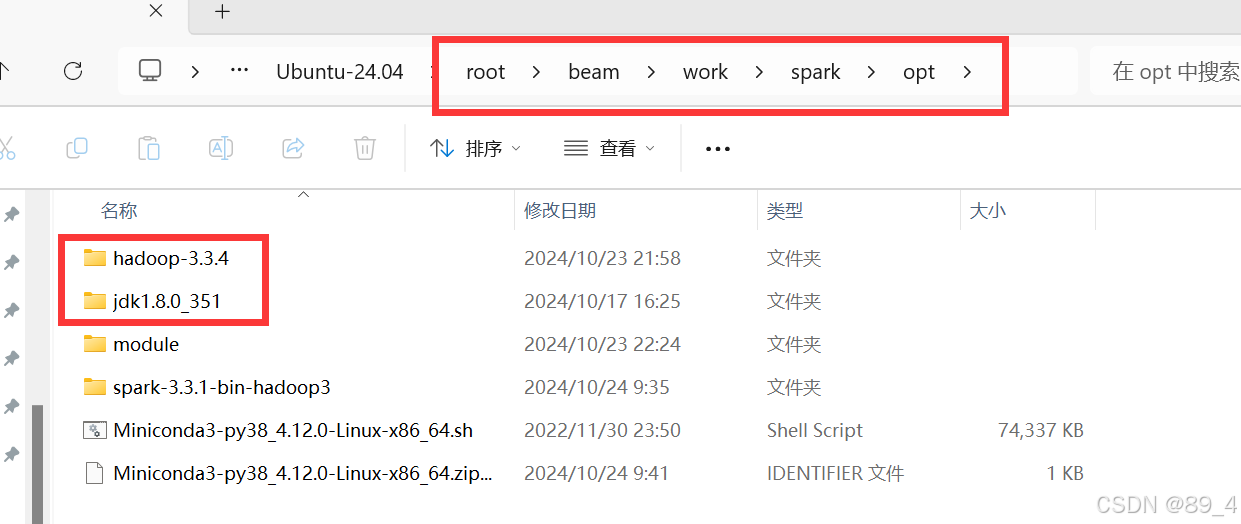
路径/root/beam/work/spark一会通过 -volume 挂载方式
挂载到3个容器中。
3.节点规划
| spark_master | spark_worker_1 | spark_worker_2 | |
|---|---|---|---|
| HDFS | NameNode DataNode | DataNode | SecondaryNameNode DataNode |
| YARN | ResourceManager | NodeManager | NodeManager |
4.使用Dockerfile创建三个容器
cd /root/beam/work/spark
在/root/beam/work/spark目录:
1.1 spark_master节点
sudo docker run -itd \
--name spark_master \
--hostname sm \
--net spark_network \
--ip 172.19.0.2 \
-v ~/beam/work/spark/sm:/root \
-v ~/beam/work/spark/hosts:/etc/hosts \
-v ~/beam/work/spark/sshd_config:/etc/ssh/sshd_config \
-v ~/beam/work/spark/opt:/opt \
-p 9870:9870 -p 8089:8089 -p 8080:8080 -p 4041:4040 \
cc:latest
1.2 spark_worker_1 节点
sudo docker run -itd \
--name spark_worker_1 \
--hostname sw1 \
--net spark_network \
--ip 172.19.0.3 \
-v ~/beam/work/spark/sw1:/root \
-v ~/beam/work/spark/hosts:/etc/hosts \
-v ~/beam/work/spark/sshd_config:/etc/ssh/sshd_config \
-v ~/beam/work/spark/opt:/opt \
cc:latest
1.3 spark_worker_2 节点
sudo docker run -itd \
--name spark_worker_2 \
--hostname sw2 \
--net spark_network \
--ip 172.19.0.4 \
-v ~/beam/work/spark/sw2:/root \
-v ~/beam/work/spark/hosts:/etc/hosts \
-v ~/beam/work/spark/sshd_config:/etc/ssh/sshd_config \
-v ~/beam/work/spark/opt:/opt \
cc:latest
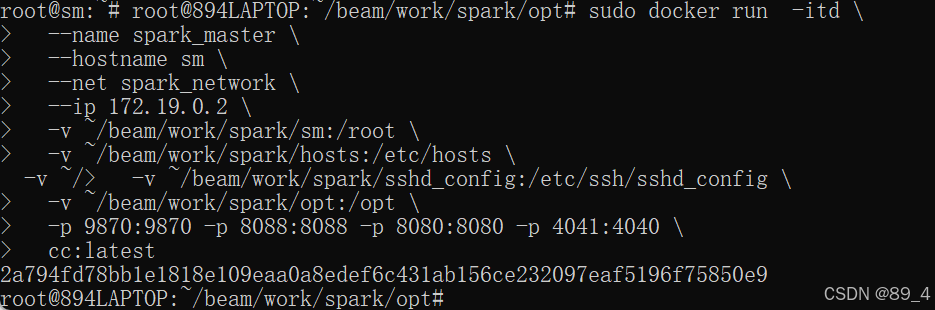
注意此处代码:
--ip 172.19.0.2 \ #指定ip地址
-v ~/beam/work/spark/sm:/root \ #挂载sm文件夹
-v ~/beam/work/spark/hosts:/etc/hosts \ #挂载hosts文件
-v ~/beam/work/spark/sshd_config:/etc/ssh/sshd_config \ #挂载sshd_config文件
-v ~/beam/work/spark/opt:/opt \ #挂载opt文件里的Hadoop和jdk
-p 9870:9870 -p 8088:8088 -p 8080:8080 -p 4041:4040 \ #端口映射
如图所示:
5.免密登录
sudo docker exec -it spark_master /bin/bash
进入sm节点后,
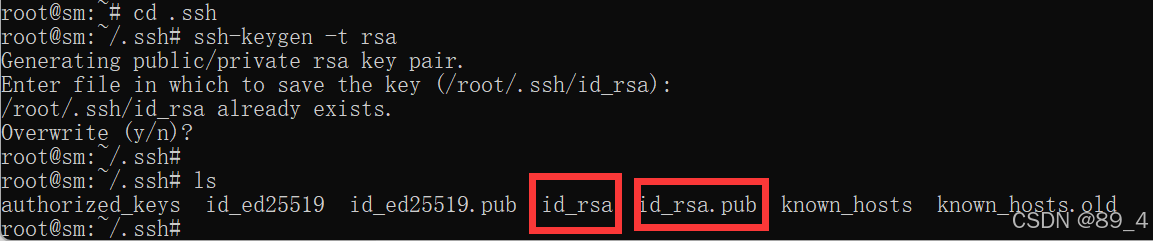
cd ~ # 进入当前用户目录
cd .ssh # 进入.ssh目录
ssh-keygen -t rsa
运行后生产私钥和公钥文件
然后把公钥传给其他节点,
ssh-copy-id sm # 最好对自己也设置一下
ssh-copy-id sw1
ssh-copy-id sw2
然后就可以ssh sw1无密访问其他节点。
对其他节点重复上述操作。
6.配置核心文件
接下来主要是配置四个核心文件core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml
进入/opt/hadoop-3.3.4/etc/hadoop/,依次修改这四个文件
cd /opt/hadoop-3.3.4/etc/hadoop/
6.1 修改core-site.xml
vim core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<!--指定namenode的地址-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://sm:8020</value>
</property>
<!--用来指定使用hadoop时产生文件的存放目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop-3.3.4/tmp</value>
</property>
<!--配置HDFS网页登录使用的静态用户为atguigu-->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
</configuration>
6.2修改hdfs-site.xml
vim hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- nn web 端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>sm:9870</value>
</property>
<!-- 2nn web 端访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>sw2:9868</value>
</property>
<!-- 指定 Hadoop DataNode 存储其数据的目录-->
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///opt/hadoop-3.3.4/data/datanode</value>
</property>
</configuration>
6.3修改yarn-site.xml
vim yarn-site.xml
<configuration>
<!--nomenodeManager获取数据的方式是shuffle-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--指定Yarn的老大(ResourceManager)的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>sm</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<!--yarn总管理器的web http通讯地址-->
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>0.0.0.0:8089</value>
</property>
</configuration>
6.4修改mapred-site.xml文件
vim mapred-site.xml
<configuration>
<!--告诉hadoop以后MR(Map/Reduce)运行在YARN上-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
配置worker
vim /opt/hadoop-3.3.4/etc/hadoop/workers
修改为
sm
sw1
sw2
7.配置环境变量
vim /etc/profile.d/my_env.sh
export JAVA_HOME=/opt/jdk1.8.0_351
export PATH=$PATH:$JAVA_HOME/bin
export HADOOP_HOME=/opt/hadoop-3.3.4
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
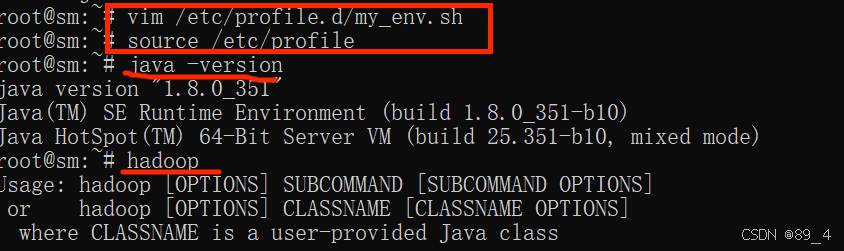
保存后刷新,然后验证
source /etc/profile
java -version
hadoop
8.运行
8.1 初始化
cd /opt/hadoop-3.3.4/
hdfs namenode -format
8.2 主节点sm运行Hadoop,yarn (spark)
/opt/hadoop-3.3.4/sbin/start-all.sh
/opt/spark-3.3.1-bin-hadoop3/sbin/start-master.sh #可选
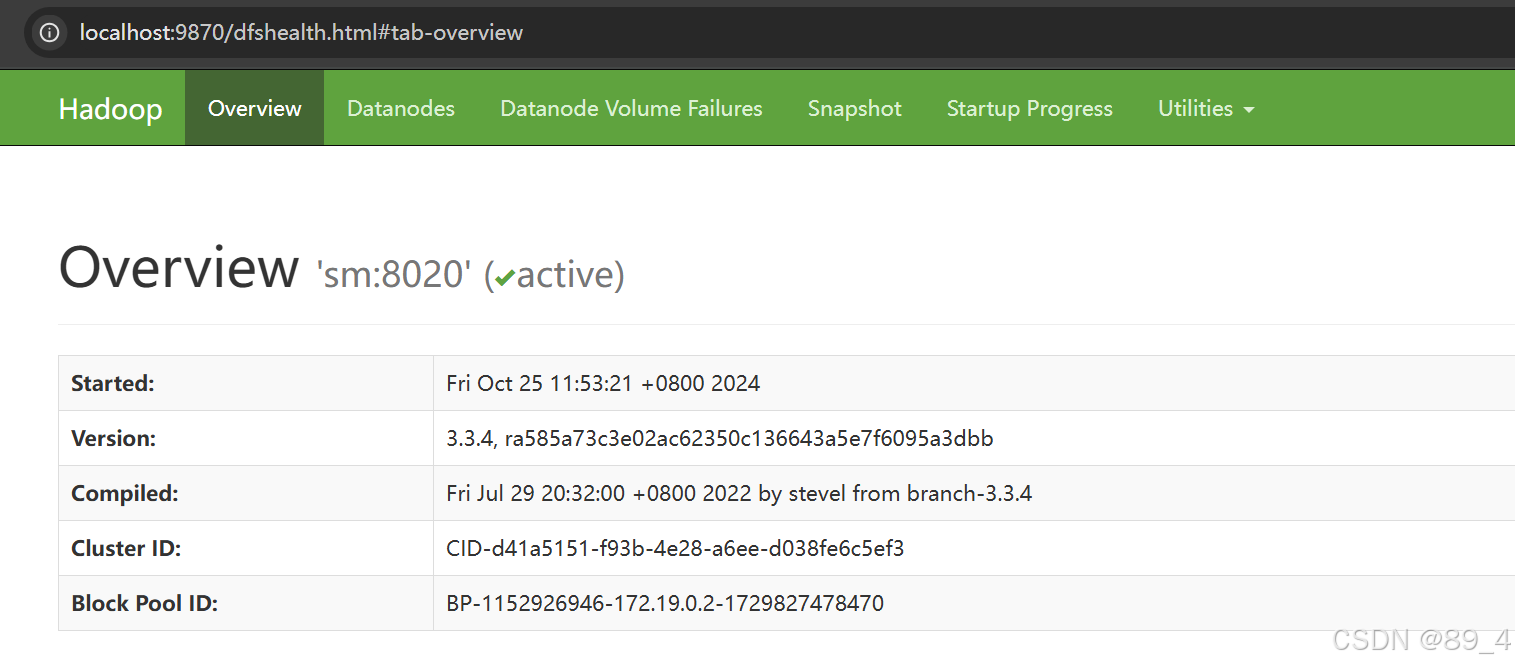
9.访问web验证

直接在docker desktop里点击相应端口
或
https://宿主机ip:9870
或
http://localhost:9870/

















 1394
1394

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









