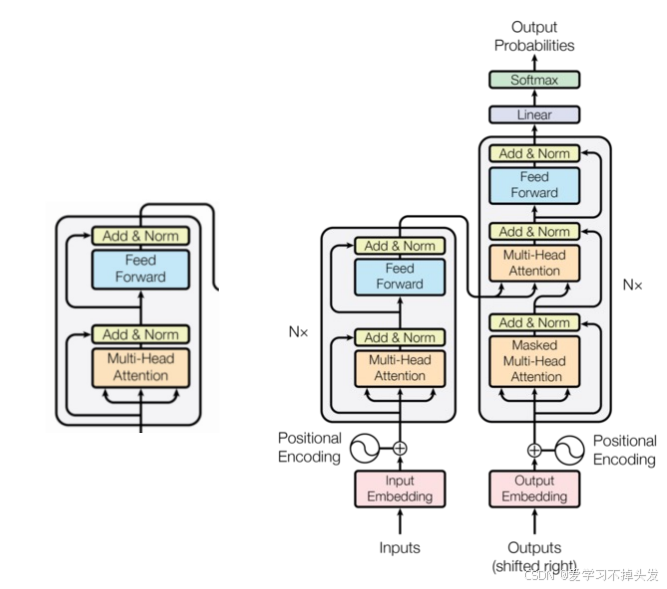
1 编码器层部分
- 编码器层是编码器的组成单元(是编码部分的组成单元)
- 完成一次对输入特征的提取, 即编码过程
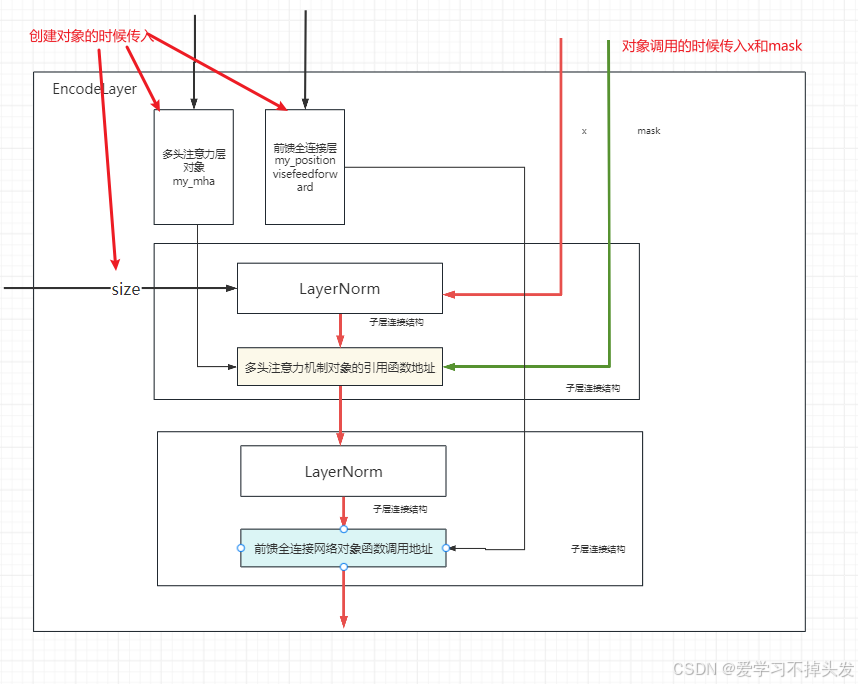
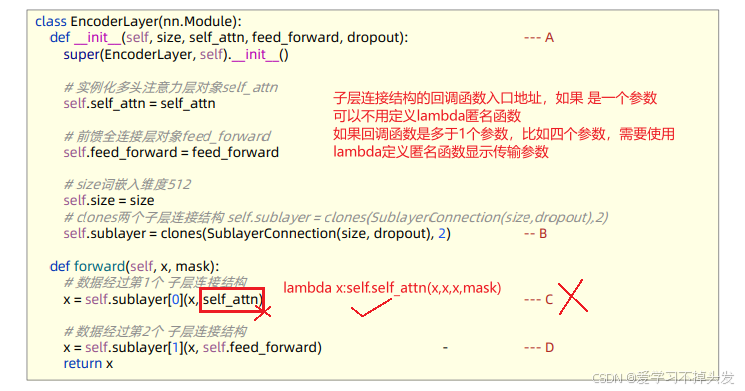
class EncoderLayer(nn.Module):
def __init__(self, size, self_attn, feed_forward, dropout):
super(EncoderLayer, self).__init__()
self.self_attn = self_attn
self.feed_forward = feed_forward
self.size = size
self.sublayer = clones(SublayerConnection(size, dropout), 2)
def forward(self, x, mask):
x = self.sublayer[0](x, lambda x:self.self_attn(x, x, x, mask))
x = self.sublayer[1](x, self.feed_forward)
return x
def dm07_test_EncoderLayer():
pe_result = torch.randn(2, 4, 512)
mask = Variable(torch.zeros(8, 4, 4))
my_mha = MultiHeadedAttention(8, 512, 0.1)
d_model, d_ff = 512, 1024
my_positionwisefeedforward = PositionwiseFeedForward(d_model, d_ff)
my_encoderlayer = EncoderLayer(512, my_mha, my_positionwisefeedforward, 0.1)
print('my_encoderlayer-->', my_encoderlayer)
el_result = my_encoderlayer(pe_result, mask)
print('el_result-->', el_result.shape)

1.1 深拷贝多头注意力机制和前馈全连接传参
- 编码器层,在传入多头自注意力机制对象的时候,需要进行深拷贝,保证每个编码器层使用自己独立的my_mha对象,my_positionwisefeedforward对象;也就说每个层拥有自己独立自注意力层权重参数
c = copy.deepcopy
my_encoderlayer = EncoderLayer(512, c(my_mha), c(my_positionwisefeedforward), 0.1)
1.2 子层连接结构传参
2 编码器实现
- 由N个编码器层堆叠而成
- 编码器用于对输入进行指定的特征提取过程, 也称为编码
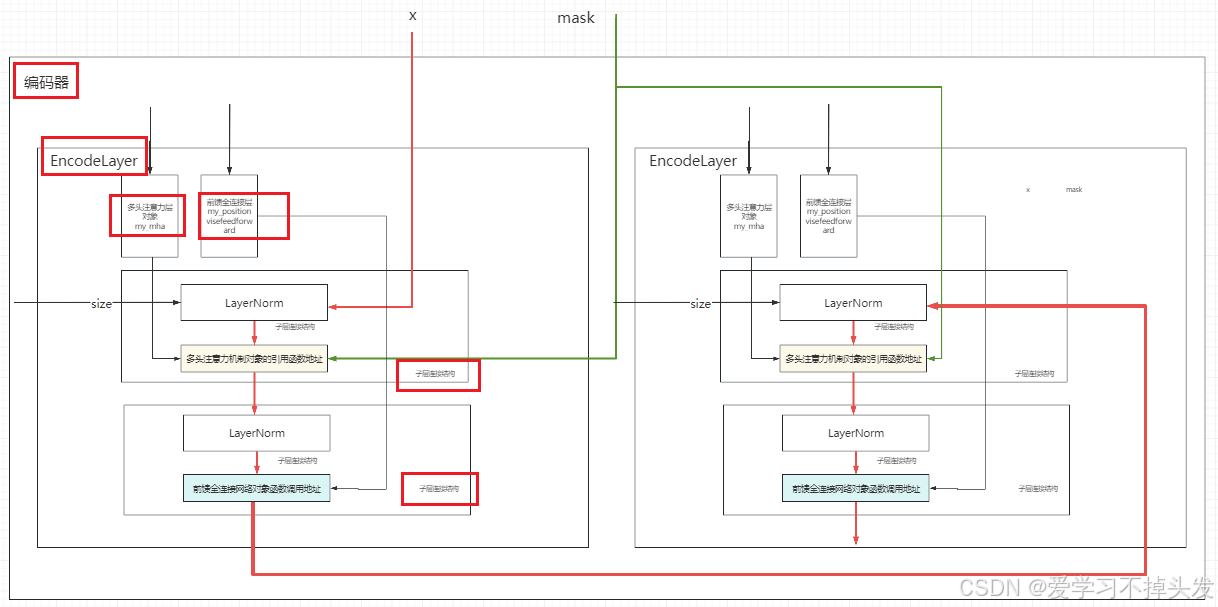
class Encoder(nn.Module):
def __init__(self, layer, N):
super(Encoder, self).__init__()
self.layers = clones(layer, N)
self.norm = LayerNorm(layer.size)
def forward(self, x, mask):
for layer in self.layers:
x = layer(x, mask)
return self.norm(x)
def dm08_test_Encoder():
c = copy.deepcopy
pe_result = torch.randn(2, 4, 512)
mask = Variable(torch.zeros(8, 4, 4))
my_mha = MultiHeadedAttention(8, 512, 0.1)
d_model, d_ff = 512, 1024
my_positionwisefeedforward = PositionwiseFeedForward(d_model, d_ff)
my_encoderlayer = EncoderLayer(512, c(my_mha), c(my_positionwisefeedforward), 0.1)
myencoder = Encoder(my_encoderlayer, 6)
print('myencoder--->', myencoder)
encoder_result = myencoder(pe_result, mask)
print('encoder_result--->', encoder_result.shape, encoder_result)

3 解码器层部分
- 是解码器的组成单元
- 每个解码器层根据给定的输入向目标方向进行特征提取操作,即解码过程
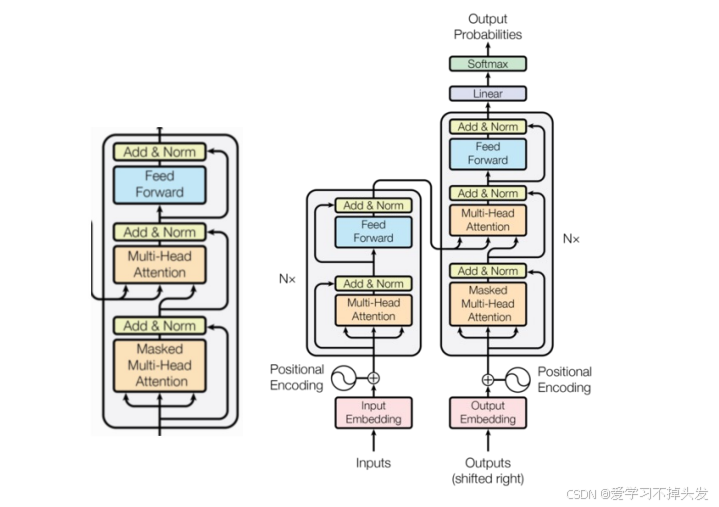
class DecoderLayer(nn.Module):
def __init__(self, size, self_attn, src_attn, feed_forward, dropout):
super(DecoderLayer, self).__init__()
self.size = size
self.self_attn = self_attn
self.src_attn = src_attn
self.feed_forward = feed_forward
self.sublayer = clones(SublayerConnection(size, dropout), 3)
def forward(self, x, memory, source_mask, target_mask):
m = memory
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, target_mask))
x = self.sublayer[1](x, lambda x: self.src_attn(x, m, m, source_mask))
x = self.sublayer[2](x, self.feed_forward)
return x
def dm01_test_DecoderLayer():
pe_result = torch.randn(2, 4, 512)
source_mask = Variable(torch.zeros(8, 4, 4))
target_mask = Variable(torch.zeros(8, 4, 4))
self_attn = src_attn = MultiHeadedAttention(8, 512, 0.1)
d_model, d_ff = 512, 1024
ff = PositionwiseFeedForward(d_model, d_ff)
my_decoderlayer = DecoderLayer(512, self_attn, src_attn, ff, 0.1)
print('my_decoderlayer--->', my_decoderlayer)
memory = torch.randn(2, 4, 512)
dl_result = my_decoderlayer(pe_result, memory, source_mask, target_mask)
print('dl_result--->', dl_result.shape, dl_result)
4 解码器实现
- 多个解码器层组成解码器(解码器部分)
- 根据编码器的结果以及上一次预测的结果, 对下一次可能出现的‘值’进行特征表示;
class Decoder(nn.Module):
def __init__(self, layer, N):
super(Decoder, self).__init__()
self.layers = clones(layer, N)
self.norm = LayerNorm(layer.size)
def forward(self, x, memory, source_mask, target_mask):
for layer in self.layers:
x = layer(x, memory, source_mask, target_mask)
return self.norm(x)
def dm02_test_Decoder():
c = copy.deepcopy
pe_result = torch.randn(2, 4, 512)
source_mask = Variable(torch.zeros(8, 4, 4))
target_mask = Variable(torch.zeros(8, 4, 4))
self_attn = src_attn = MultiHeadedAttention(8, 512, 0.1)
d_model, d_ff = 512, 1024
ff = PositionwiseFeedForward(d_model, d_ff)
my_decoderlayer = DecoderLayer(512, c(self_attn), c(src_attn), c(ff), 0.1)
print('my_decoderlayer--->', my_decoderlayer)
memory = torch.randn(2, 4, 512)
my_decoder = Decoder(my_decoderlayer, 6)
print('my_decoder--->', my_decoder)
decoder_result = my_decoder(pe_result, memory, source_mask, target_mask)
print('decoder_result--->', decoder_result.shape, decoder_result)

























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









