







文章目录
导航参见:
【MapStruct】高性能对象转换神器MapStruct使用教程从基础到进阶(一)
【MapStruct】深入浅出带你学会从编译调试走进MapStruct源码(二)
一、背景
在上一篇文章中已经介绍并对比了一些对象转工具的基本特点,最后详细的介绍了一下MapStruct的详细使用教程。MapStruct常常被称为对象转换神器,性能极强,那相信很多小伙伴会很好奇:这东西能竟然这么玩,那它到底是咋实现的呢?本文将带你从编译调试进去到源码中,深入理解一下它的实现原理,之后将会发现其背后会用到很多知识点:JSR-269、编译原理、生成树AST、SPI机制、FreeMarker等等.......
二、 MapStruct底层源码解析
不急,我们先来了解一些基本概念,可能大家之前就已听说过、看过或背过,但是可能并没有清楚它到底是个啥。那我们先来补一下JSR的知识点,JSR(Java Specification Requests)意思是Java规范提案,是指向JCP(Java Community Process)提出新增一个标准化技术规范的正式请求。通俗点来说,JCP是一个由来自世界各地的Java代表组成的负责监督Java的发展的组织,JSR就是一个为了推动Java技术更好的发展的一个标准,允许所有Java开发者和授权者共同制定标准,最后这些标准被各个厂商实现。
在学习Spring框架的时候相信大家肯定学过@Component注解,当时经典对比就是将其和@Resource注解做对比,@Resource注解是基于的JSR-250的注解(@PreDestroy和@PostConstruct注解同样也是基于JSR-250)。那么现在回过头来看,这个JSR概念并不陌生,那它与MapStruct 又有啥关系呢?
mapstruct是基于JSR-269实现的(同样,大名鼎鼎的Lombok也是基于JSR-269实现,本文暂不做详细介绍,有兴趣可以去了解一下),这个规范自Java 6开始引入,允许开发者在编译时期进行注解处理,也就是说,开发者可以编写自己的注解处理器来处理源代码中的注解,从而在编译时生成额外的源代码、文档或其他文件。JSR-269使用Annotation Processor在编译期间处理注解,Annotation Processor相当于编译器的一种插件,因此又称为插入式注解处理。想要实现JSR 269,主要有以下几个步骤:
1. 自定义注解。
2. 继承AbstractProcessor类,并且重写process方法,在process方法中实现自己的注解处理逻辑。
3. 在META-INF/services目录下创建javax.annotation.processing.Processor文件注册自己实现的Annotation Processor。
4. 编译项目并deploy jar包到maven仓库,在其他项目引入该jar包,在接口上加上我们自定义的注解。
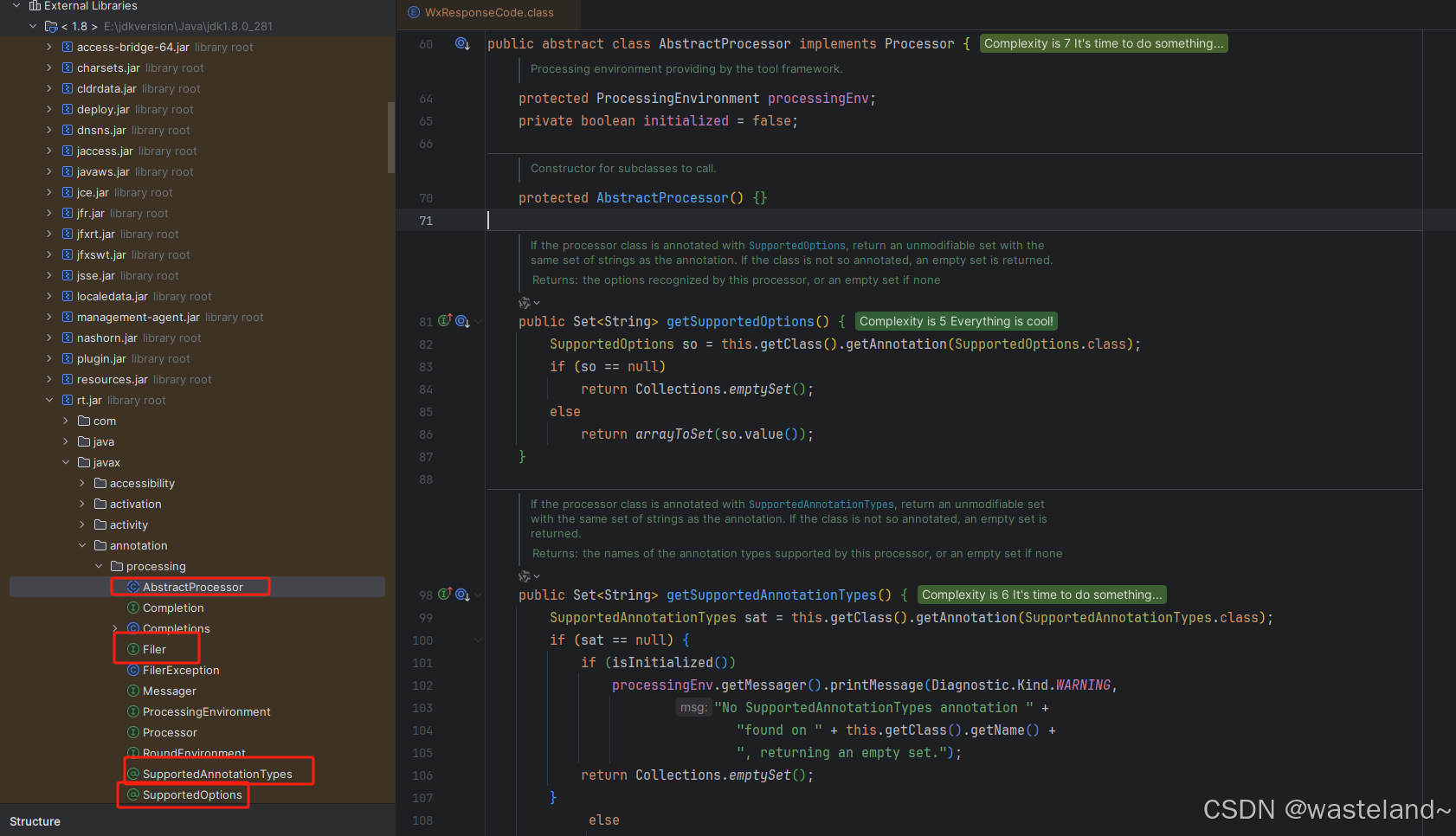
说明:AbstractProcessor在JDK的rt.jar里面的javax.annotation.processing包下面;同时生成impl类用的也是这个包下面的Filer接口的createSourceFile方法,SupportedAnnotationTypes注解、SupportedOptions注解、SupportedSourceVersion注解也都在,而这三个注解目前只看到Mapstruct底层有用到。
2.1 MapStruct作用时机
经常有文章中会提到MapStruct相比于BeanUtils等对象转换工具性能更好,那是为啥会更好呢?其根本原因是它作用于编译阶段,无需运行时阶段通过反射进行属性拷贝。那Java程序编译一般会经历以下流程:

上图中后半部分涉及到比较多的JVM相关知识,这里不做过多介绍,前半部分Java源码到class文件的过程由前端编译器完成,其编译过程其实比较复杂,具体过程如下图所示:

上图的流程可以概括为下面几个步骤:
- 生成抽象语法树。Java编译器对Java源码进行编译,经过词法分析和语法分析后,生成抽象语法树(Abstract Syntax Tree,AST)。
- 调用实现了JSR 269 API的程序。只要程序实现了JSR 269 API,就会在编译期间调用实现的注解处理器。
- 修改抽象语法树。在实现JSR 269 API的程序中,可以修改抽象语法树,插入自己的实现逻辑。
- 生成字节码。修改完抽象语法树后,Java编译器会生成修改后的抽象语法树对应的字节码文件。
2.2 Debug模式追踪
上一小节已经介绍了 MapStruct作用时机,它作用于编译阶段,那么有什么方法可以验证一下并且深入理解MapStruct的实现原理呢?那就需要开启编译Debug模式。可以根据下述步骤进行调试:
(1)在终端里将路径切换到pom所在路径。例如pom的路径是/workspace/dts-shop/,则cd到该路径下。
(2)在终端执行mvnDebug compile。执行该命令后,终端会提示已经监听了8000端口,如下图所示。(注意,执行mvnDebug之前得先配置maven的环境变量,否则无法识别这个命令)

(3)在IDEA工具栏中,点击下拉箭头旁边的 “Edit Configurations” 按钮,然后创建添加Remote JVM Debug,端口号是8000,配置好后运行,具体如下图所示。

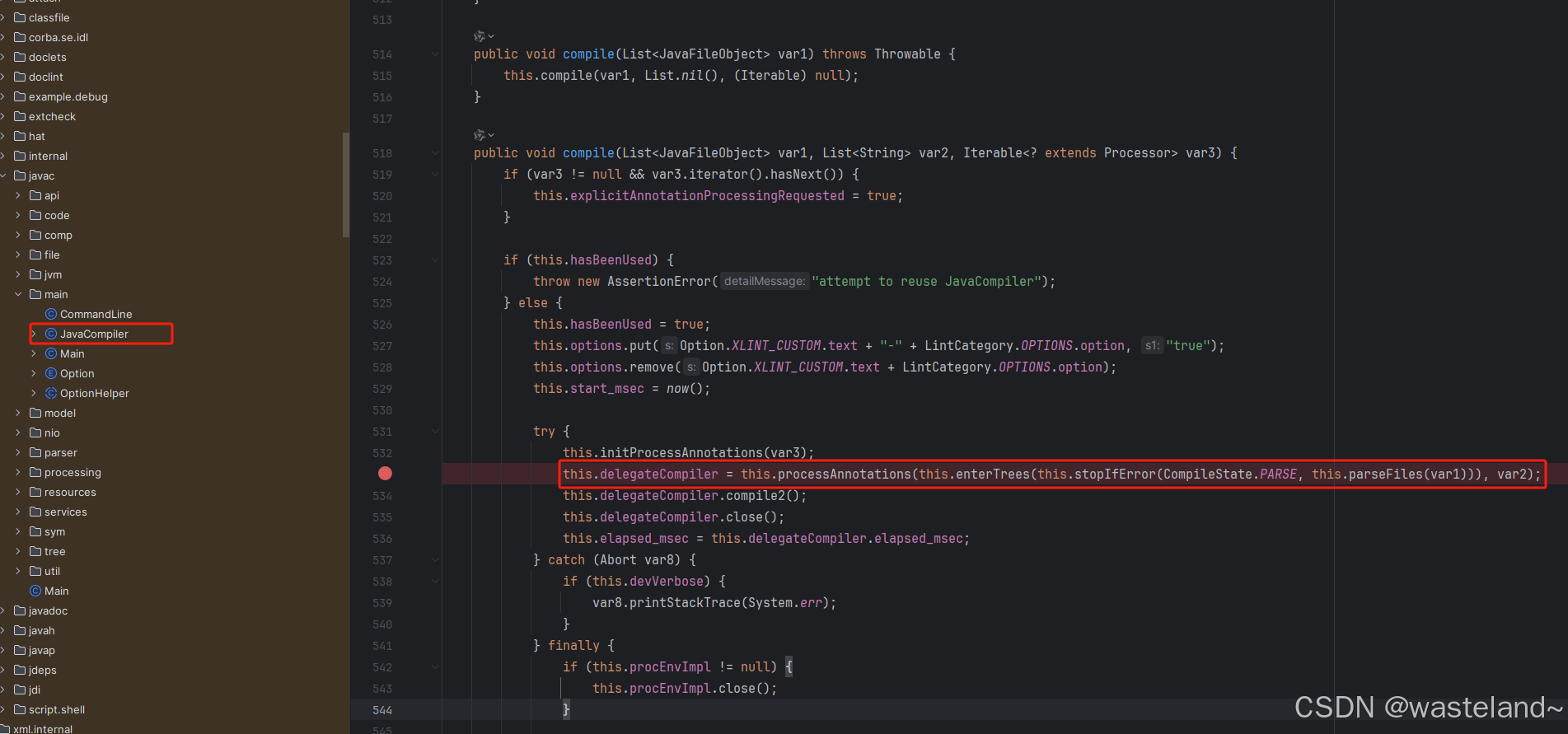
解释:在使用javac命令去编译源文件时,实际上是去执行com.sun.tools.javac.Main#main方法,而真正执行编译动作的正是 Java 编译器的主要类com.sun.tools.javac.main.JavaCompiler类,它是 JDK 中 javac 命令行工具的实现,属于 JDK 内部实现的一部分,但并不是公开的 API。com.sun.tools.javac.main.JavaCompiler 类位于 tools.jar 文件中。tools.jar 文件通常位于 JDK 安装目录的 lib 文件夹中,例如,如果 JDK 安装路径是 /jdkversion/Java/jdk1.8.0_281/,则 tools.jar 文件位于/jdkversion/Java/jdk1.8.0_281/lib/tools.jar。在 JDK 8 及以前的版本中,tools.jar 是单独的文件;在 JDK 9 及以后版本,JDK 已经迁移到模块化系统,javac 的相关工具被拆分到不同的模块中,而不再通过 tools.jar 提供。
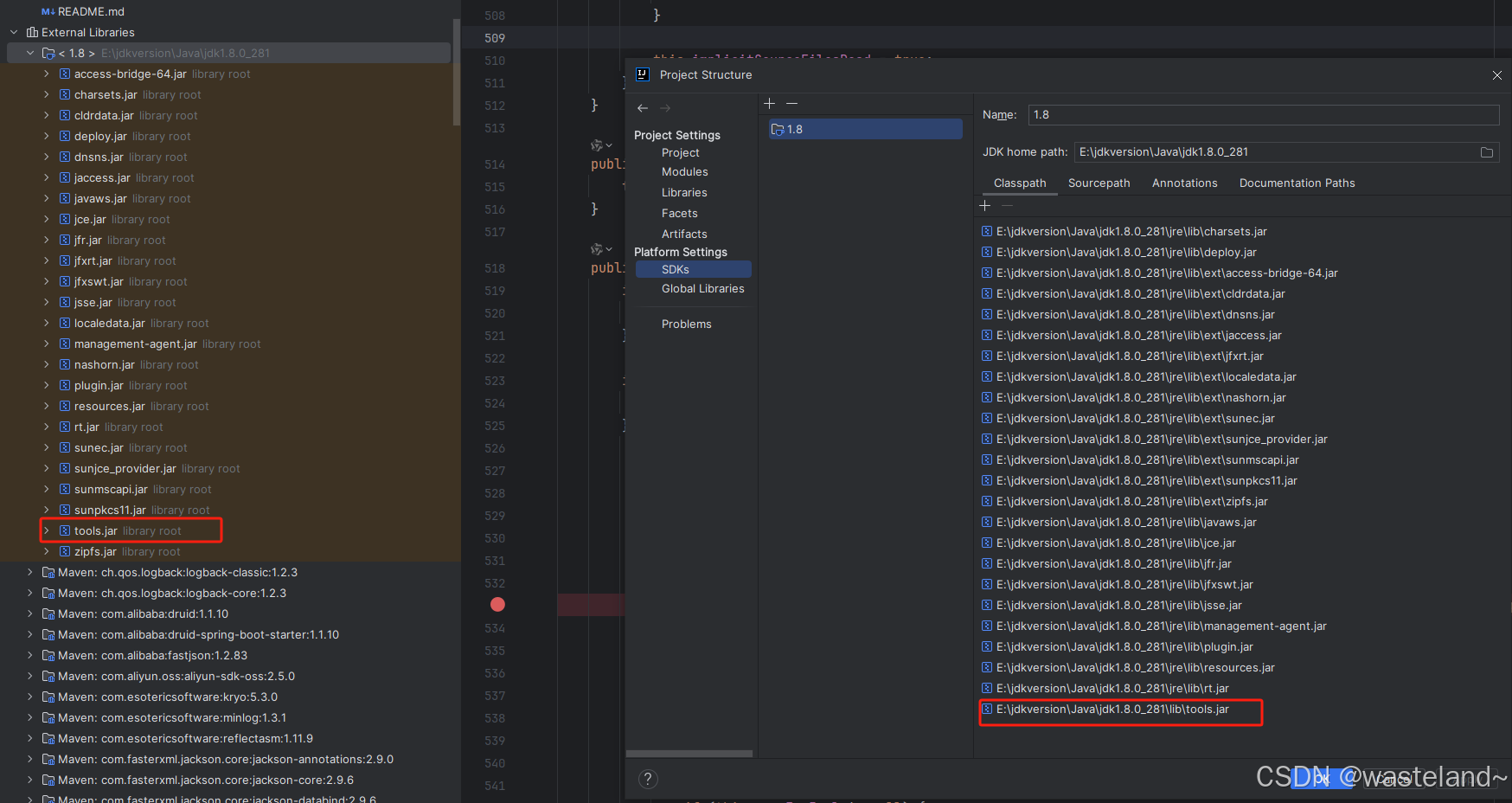
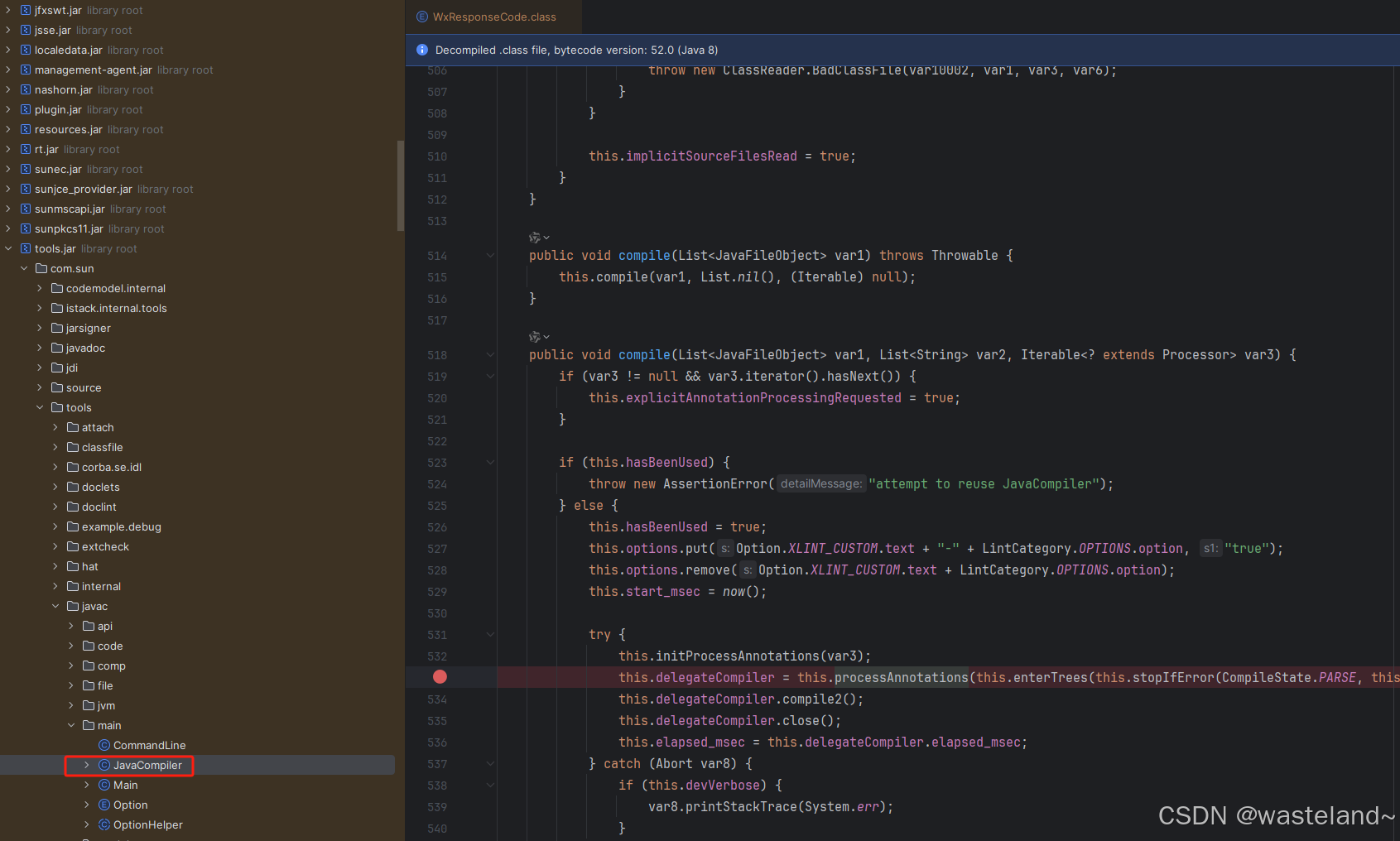
(4)在JavaCompiler类的compile方法里,打上断点,把它当作起点(当然comile方法前面还有调用,这里不做介绍),打上断点后前面运行后自然会停在这里。
2.3 MapStruct实现原理
2.3.1 MapStruct处理时机源码分析
依赖阅读源码:
(1)mapstruct主要有两个jar包。

(2)通过根据JSR-269可以知道META-INF/services目录下创建javax.annotation.processing.Processor文件注册的MappingProcessor就是MapStruct的入口。
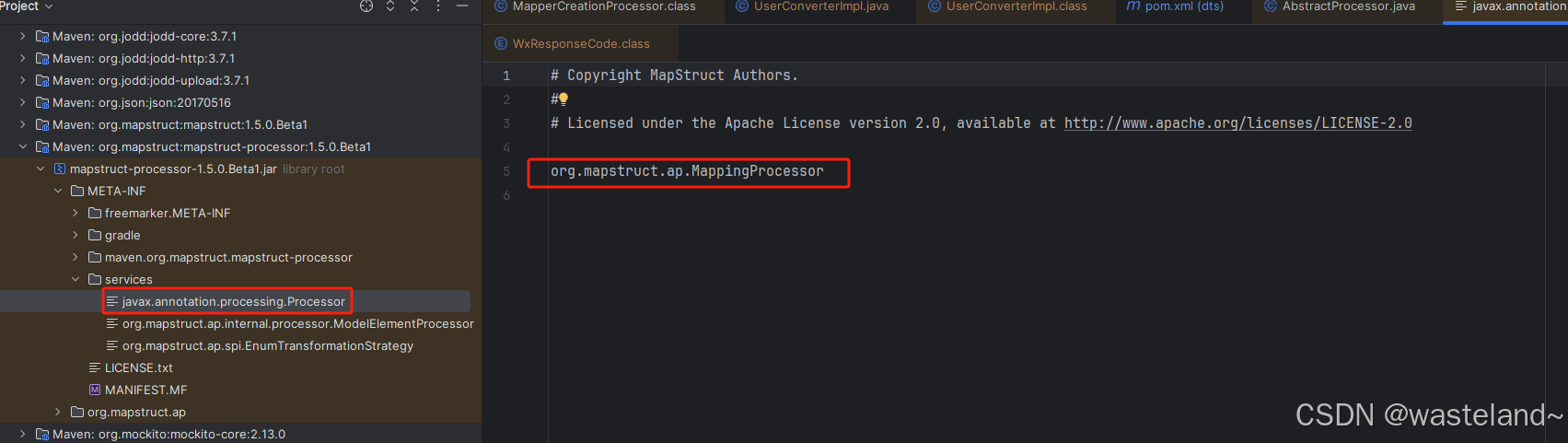
(3)com.sun.tools.javac.main.JavaCompiler#compile方法的有段代码在编译的时候会调用到MappingProcessor。
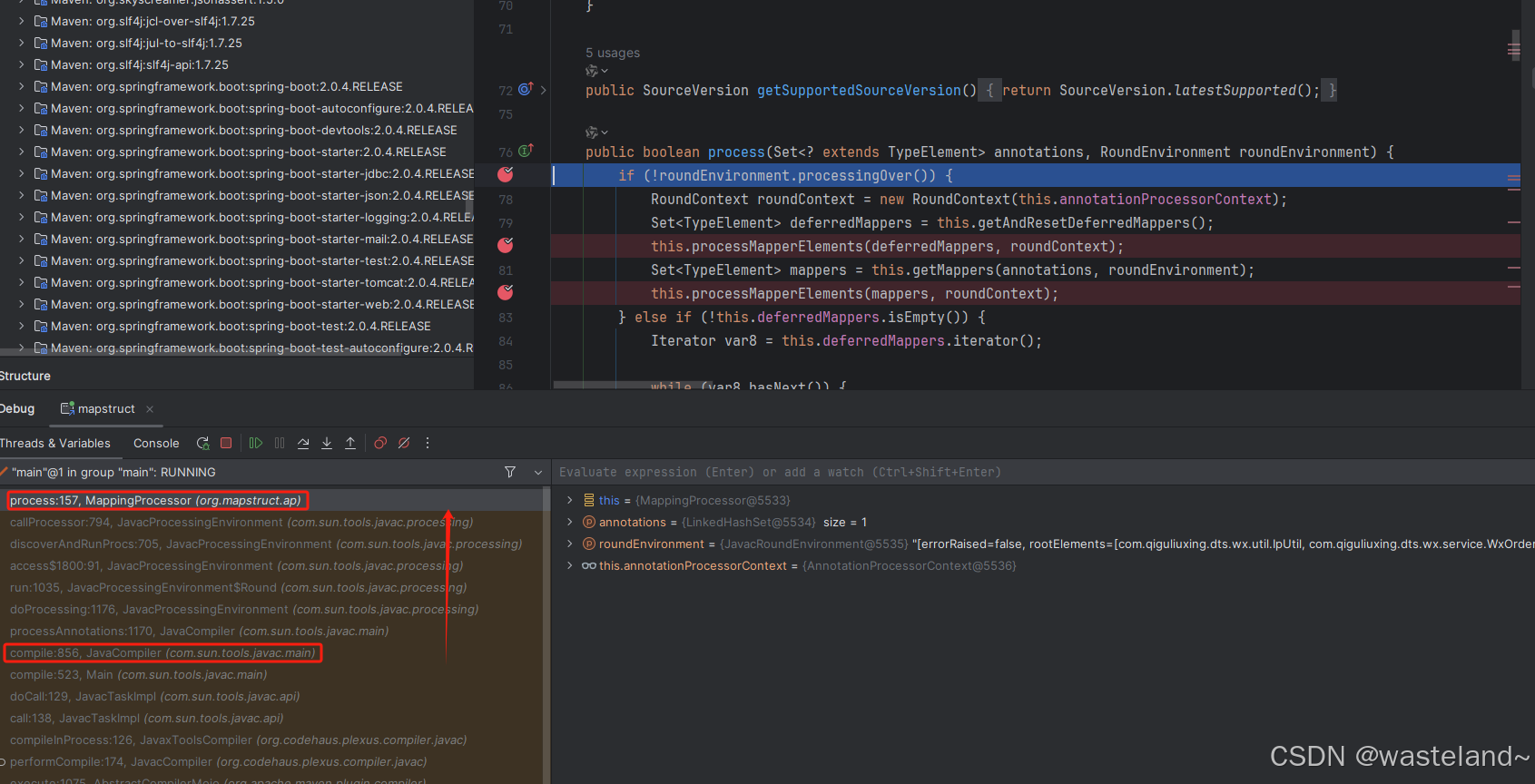
开启编译Debug模式,根据栈帧的调用链路也可以验证上述结论:
2.3.2 MapStruct处理动作源码分析
由于前面介绍到MappingProcessor就是MapStruct处理动作开始的核心类,那么现在就开始剖析MappingProcessor类。
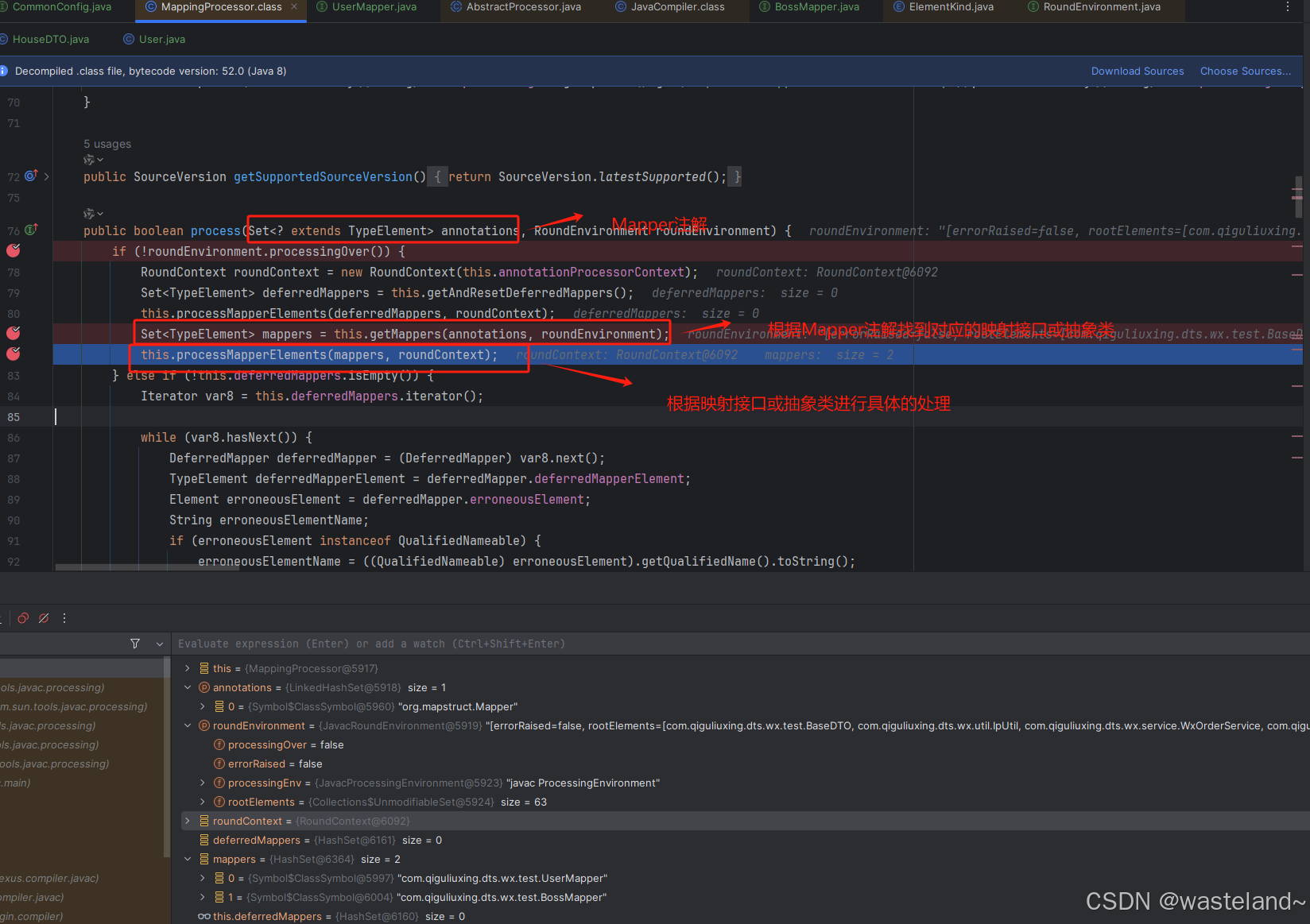
(1)下图中代码会先根据@Mapper注解去找到对应的映射接口或抽象类,具体代码就不做展示,可以自行跟进去查看,然后再调用this.processMapperElements(mappers, roundContext)执行具体的代码改造工作。
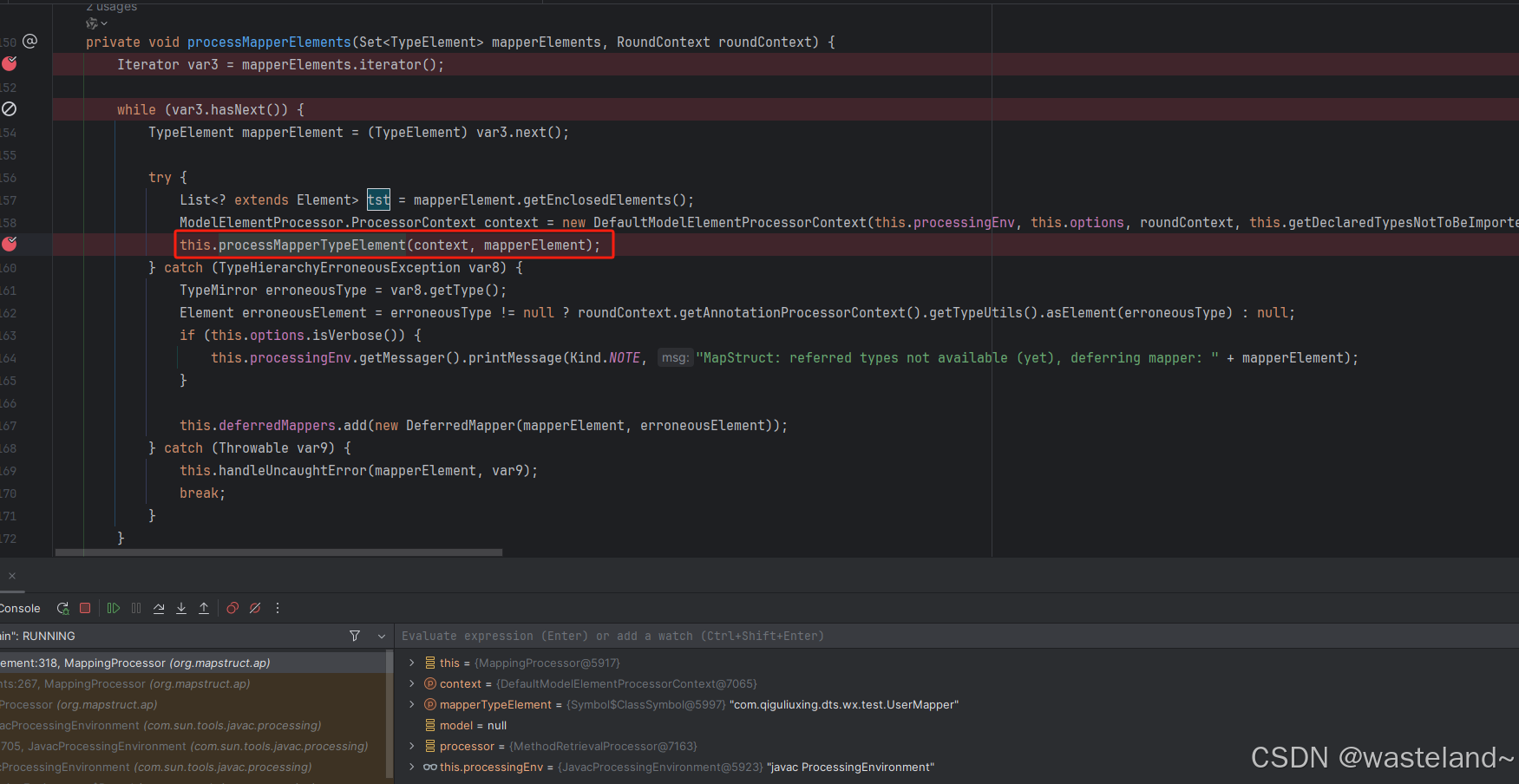
(2)遍历每个映射接口或映射抽象类,然后去具体处理其定义的对应方法。
(3)先加载好ModelElementProcessor基类的各个子类,然后再让各个子类完成各自的工作,下文会总结各个子类完成了什么工作。
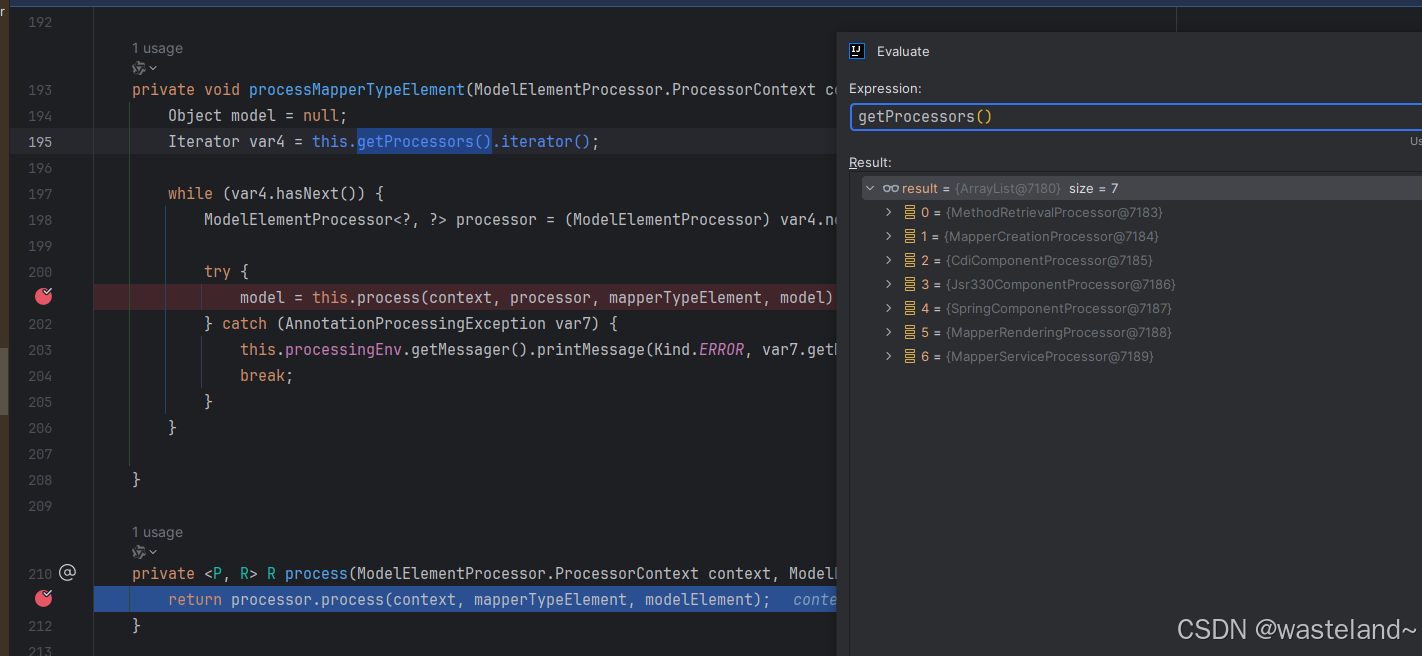
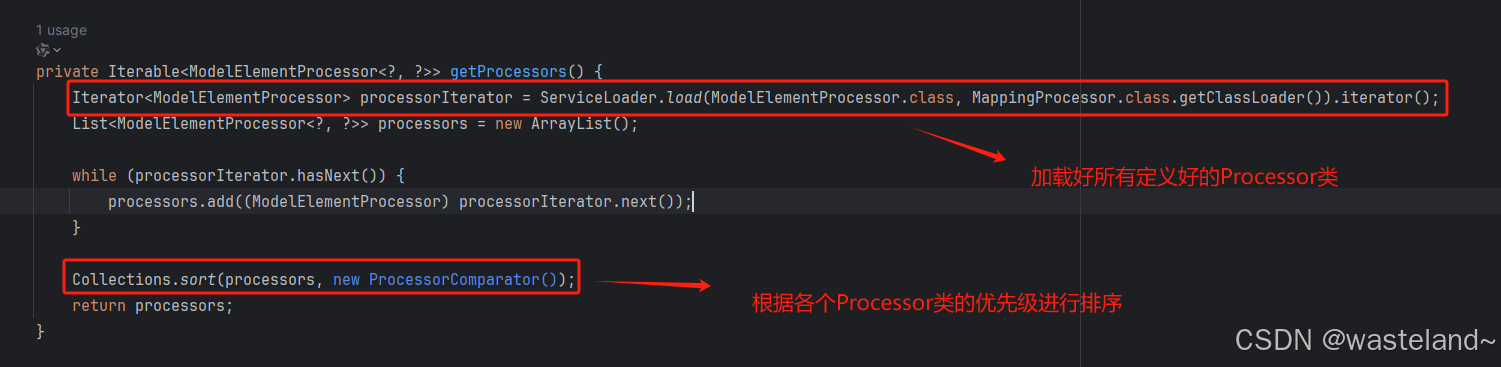
(4)在获取各个处理的过程中,先是利用java SPI的方式使用了ServiceLoader加载好所有定义好的Processor类,形成类似于责任链的一种方式(用数组执行节点而不是用链表)。
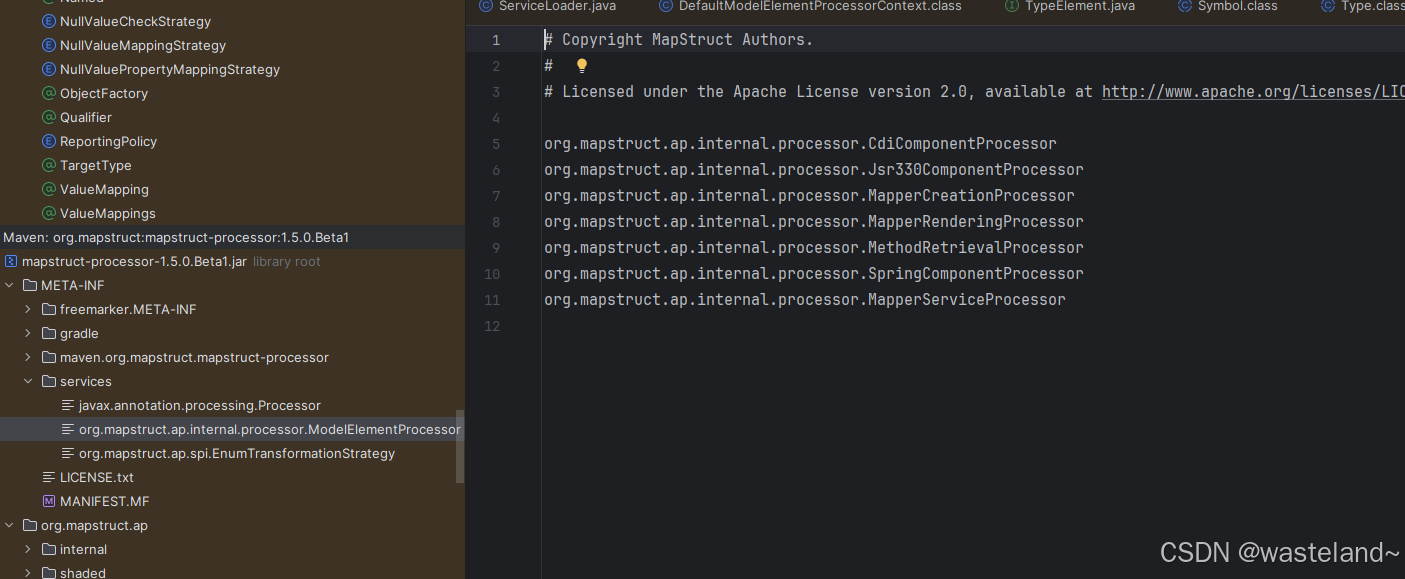
注意:熟悉Java SPI机制的朋友能够通过上图一眼发现这就是MapStruct应用SPI机制的典型体现。SPI机制相关知识在《SPI机制:Java SPI原理及源码剖析、应用场景分析与自实现案例实战详解》这篇文章中有详细的介绍。`
(5)排序规则是按照各个Processor类的优先级进行的排序,大家有兴趣点进去各个Processor类也能看到获取优先级的方法。
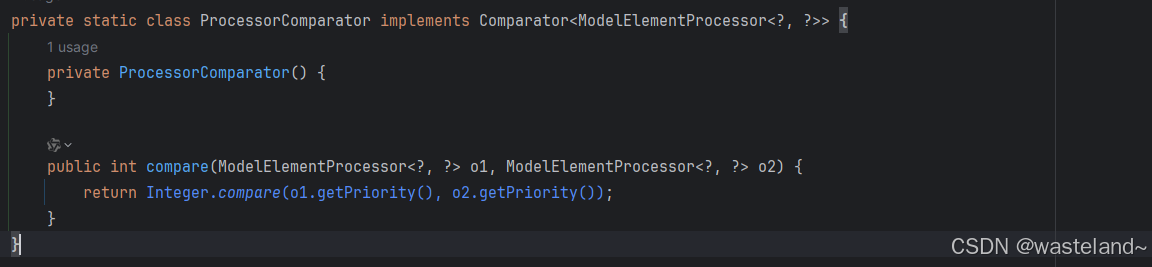
(6)process节点都继承ModelElementProcessor基类,关系如下图所示:

(7)然后按照各个Processor类按照优先级排序后会依次执行其对应的process方法。
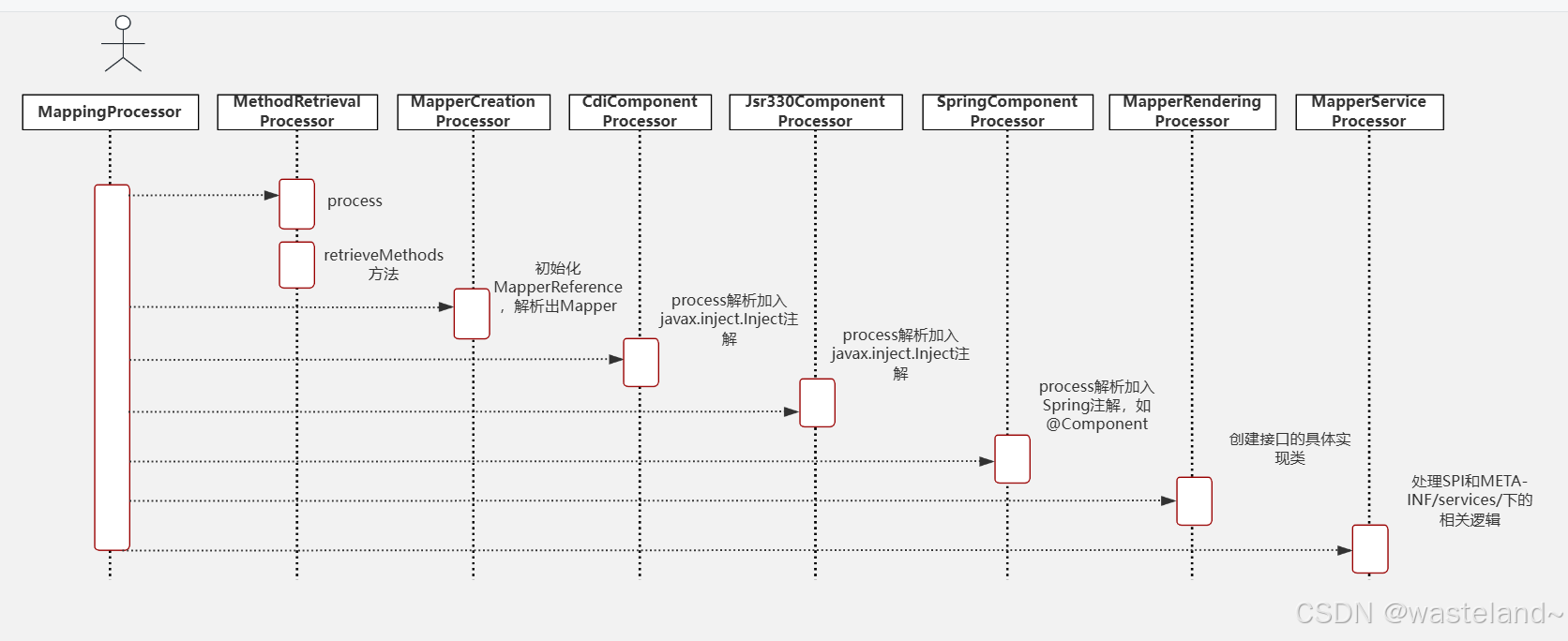
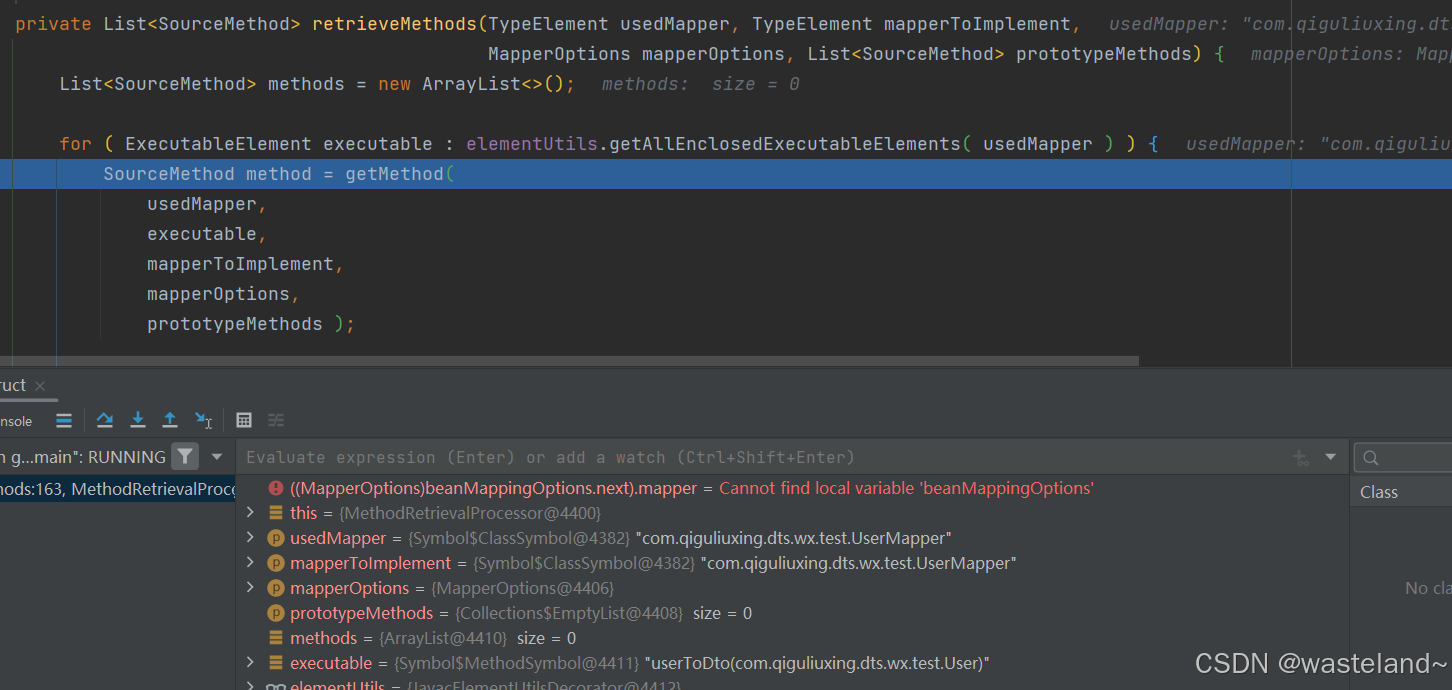
(8)从MethodRetrievalProcessor类的process方法Debug到深层源码中可以发现:核心方法是retrieveMethods方法和getMethod方法。
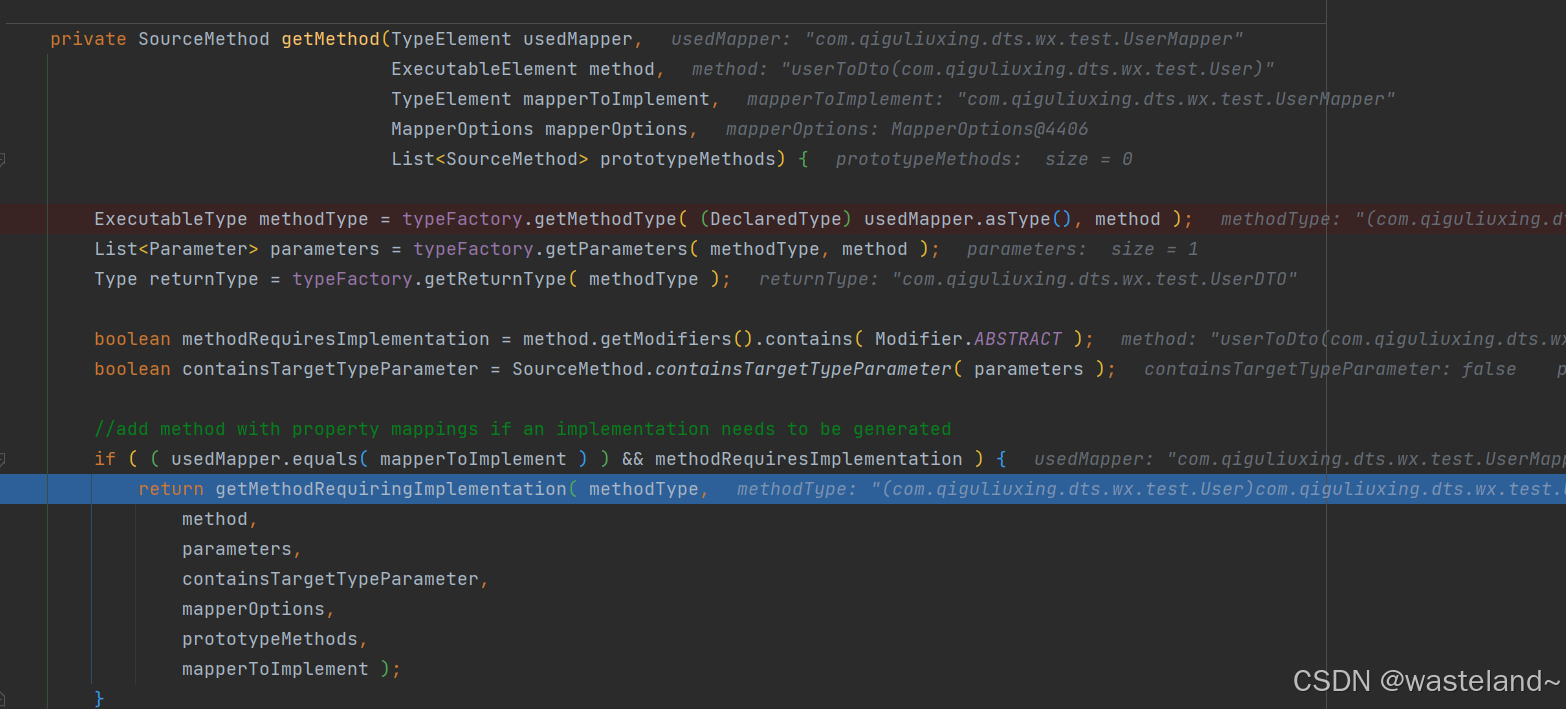
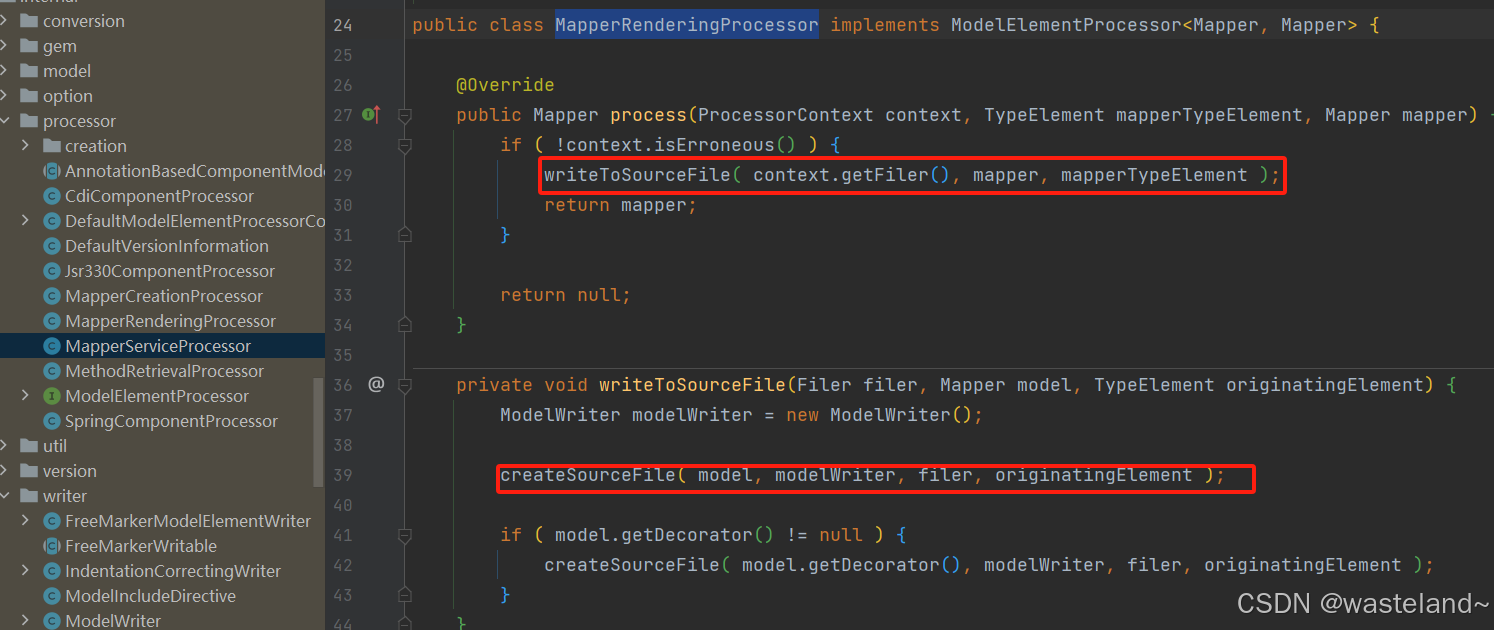
(8)而MapperRenderingProcessor类Debug到源码中可以发现:核心方法是writeToSourceFile方法和createSourceFile方法,在这个Processor类中会创建出对应Mapper的实现类,比如定义UserMapper,会创建出UserMapperImpl类,并且该类也会完成对应对象的转换工作。
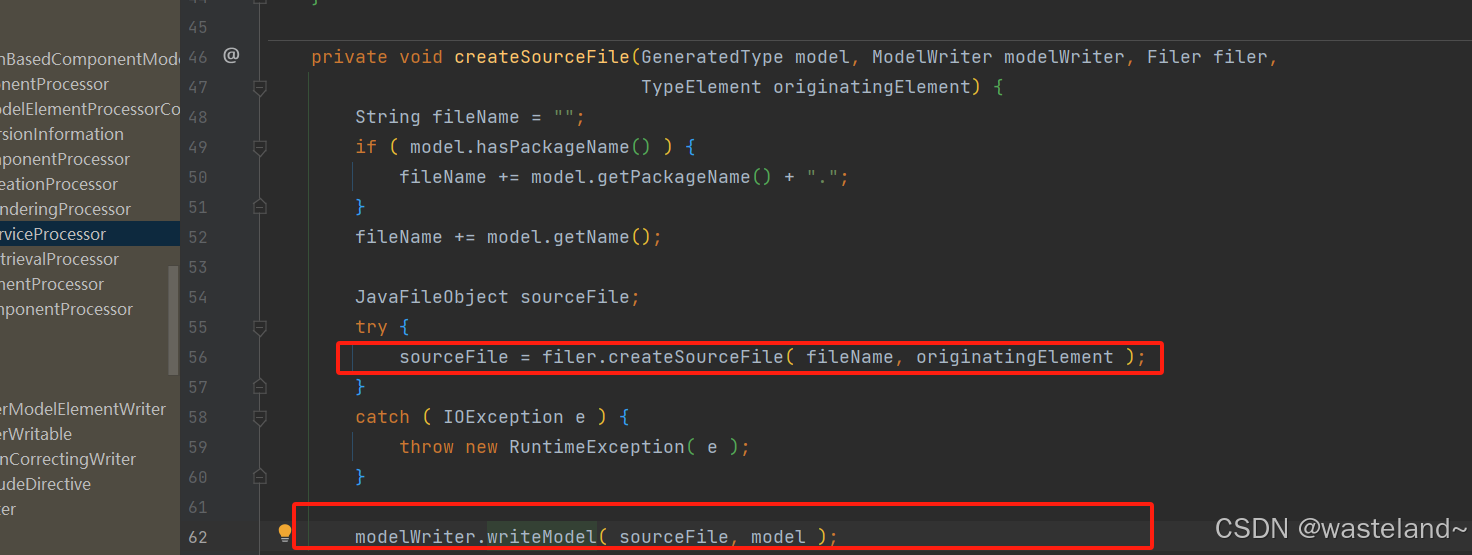
这里还想提一下的是MapStruct 库的注解处理器生成源代码文件是利用了模板引擎 FreeMarker 库,这里推荐一篇相关好文:【FreeMarker】一文快速入门FreeMarker。如下图可以看到FreeMarker利用模板生成setter方法:
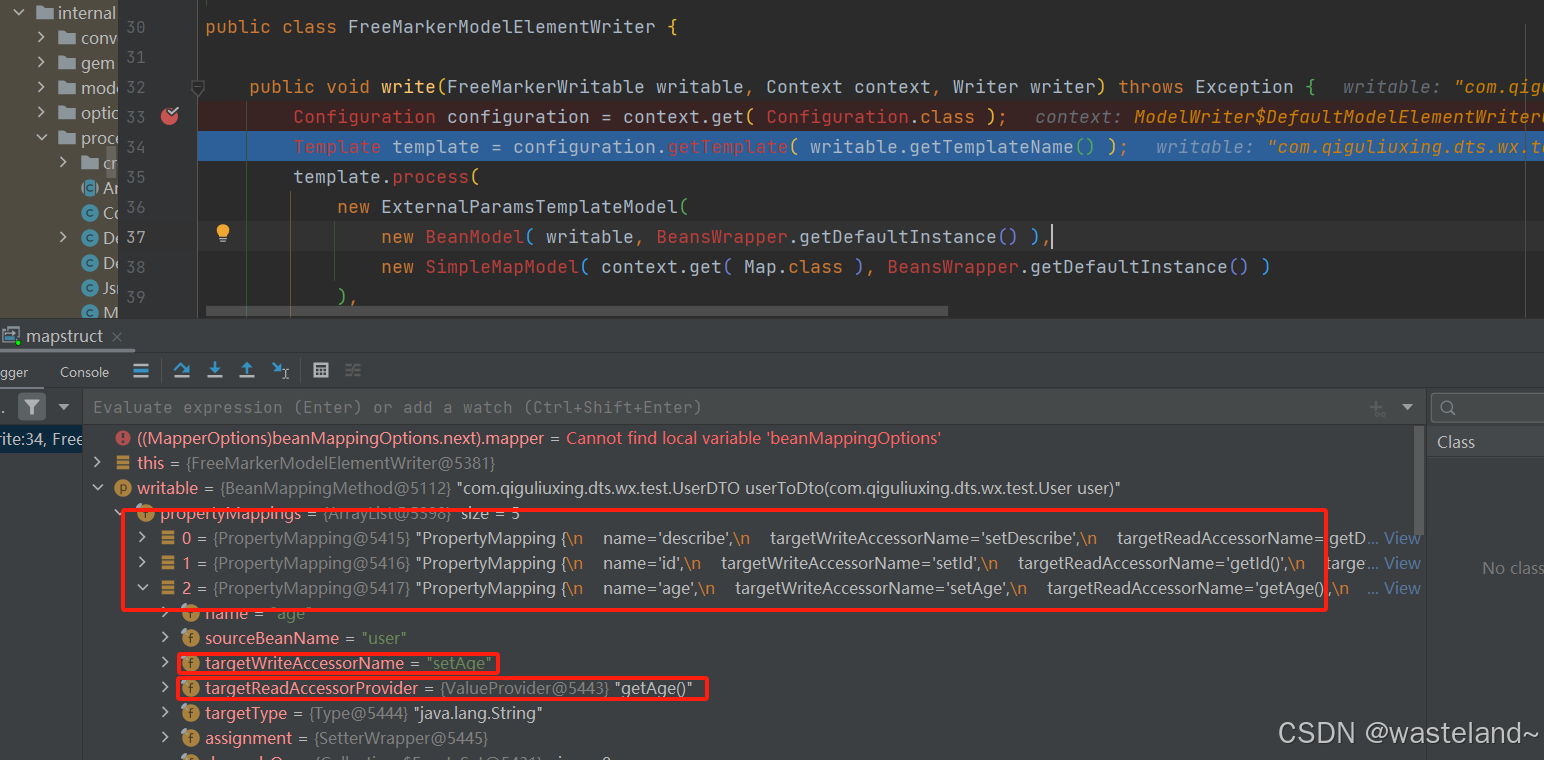
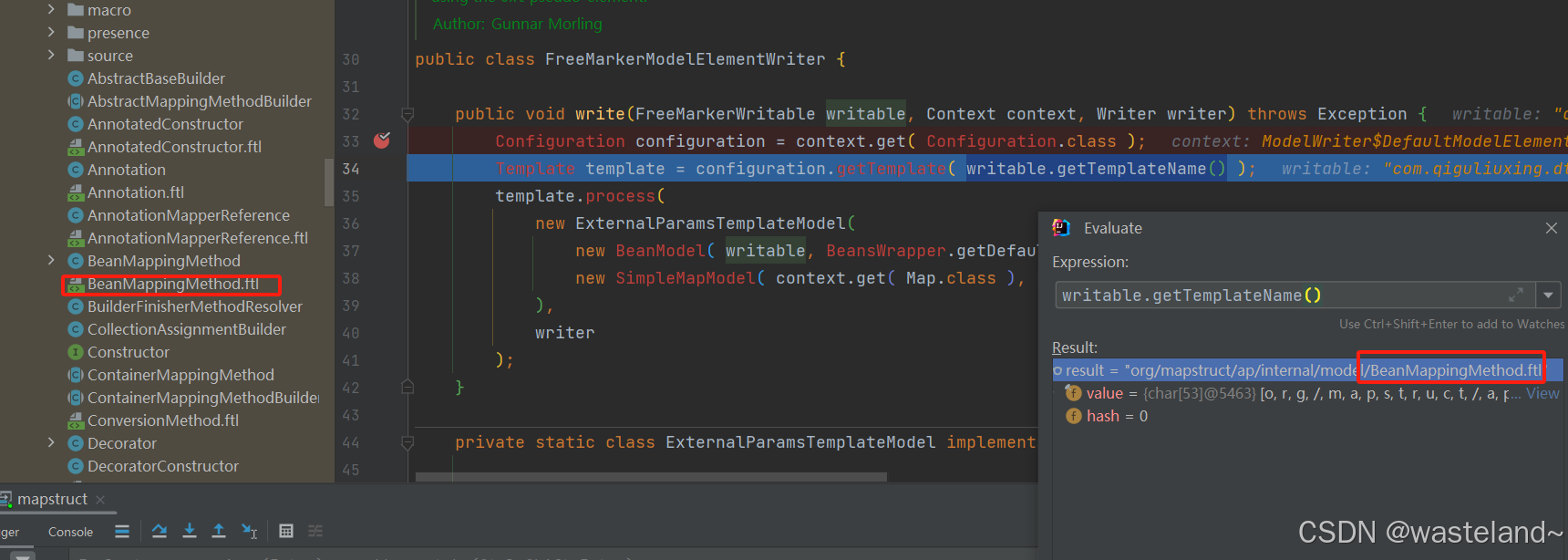
后缀为ftl的文件即为FreeMarker模板文件。这里生成setter方法所依赖的模板就是BeanMappingMethod.ftl文件,如下图所示:
上面就暂且只介绍几个Processor类的源码,其他Processor类大家可以自行Debug到处理源码底层研究,各个Processor类的简单作用说明如下表:
| 类 | 说明 |
|---|---|
| MethodRetrievalProcessor | 解析元素的方法等基本信息,priority=1 |
| MapperCreationProcessor | 初始化MapperReference,解析出Mapper,priority=1000 |
| AnnotationBasedComponentModelProcessor | 处理ComponentModel相关逻辑,priority=1100 |
| CdiComponentProcessor | process解析加入javax.inject.Inject注解,priority=1100 |
| Jsr330ComponentProcessor | process解析加入javax.inject.Inject注解,priority=1100 |
| SpringComponentProcessor | process解析加入Spring注解,如@Component,priority=1100 |
| MapperRenderingProcessor | 创建接口的具体实现类,priority=9999 |
| MapperServiceProcessor | 处理SPI和META-INF/services/下的相关逻辑,priority=10000 |
除了上述总结之外,Debug代码时经常能看见一个元素Element,Element是一个接口,表示一个程序元素,它可以是包、类、方法或者一个变量。Element已知的子接口有很多,它们都被常用在MapStruct源码中,这里做如下总结:
| 名称 | 说明 |
|---|---|
| PackageElement | 表示一个包程序元素,提供对有关包及其成员的信息的访问 |
| ExecutableElement | 表示某个类或接口的方法、构造方法或初始化程序(静态或实例),包括注释类型元素 |
| TypeElement | 表示一个类或接口程序元素,提供对有关类型及其成员的信息的访问。注意,枚举类型是一种类,而注解类型是一种接口 |
| VariableElement | 表示一个字段、enum 常量、方法或构造方法参数、局部变量或异常参数 |
注意:
- 这里还想提醒一下的是:如果你要重新Debug,最好是先进行clean操作,去除掉Maven中历史编译文件,避免产生一些不必要的错误。
三、总结
本篇文章先普及了一下JSR和JSR269规范的基本概念,以此来引出了MapStruct的作用时机和作用原理,并且简短介绍了java动态编译的过程,然后在介绍了一下如何使用IDEA在编译时开启调试功能,最后调试都源码中结合源码进行了核心类代码的分析。经此,MapStruct相关知识已经基本介绍结束,如果有遗漏或有错误,欢迎评论后续进行修正与补充,而关于MapStruct同样的剖析思路其实也可用于lombok/kotlin等语法糖的原理探究。



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











