







关于字符串常量池网上有争论,一个认为jdk7后的字符串常量池能存储引用+实例,另一个认为只能存储引用,感觉是范围定义不同。
观点一:jdk7之后,字符串常量池从方法区移动到了堆空间中,其不仅能保存字符串实例,还能保存引用。
String s1=new String("abc")+new String("def");
s1.intern();首先字符串常量池中不存在字符串对象 “abc”,那么它首先会在字符串常量池中创建字符串对象 "abc"(由ldc触发创建),然后在堆内存中再创建其中一个字符串对象。
"def"同理。然后通过StringBuilder的append方法进行拼接,在堆上创建了对象s1=“abcdef”,但是此时常量池中并不存在“abcdef”。
执行s1.intern(),常量池中不存在,但是堆上存在实例,就之间把s1的引用放入常量池中。
观点二:字符串常量池通过StringTable实例实现,存储的是字符串在堆中实例的引用。其物理存储结构本身就是堆中的一个哈希表结构(StringTable),存储键值对(字符串哈希值 -> 堆中实例的引用)。字符串实例实际存储在堆的普通内存区域,通过池中的引用关联。
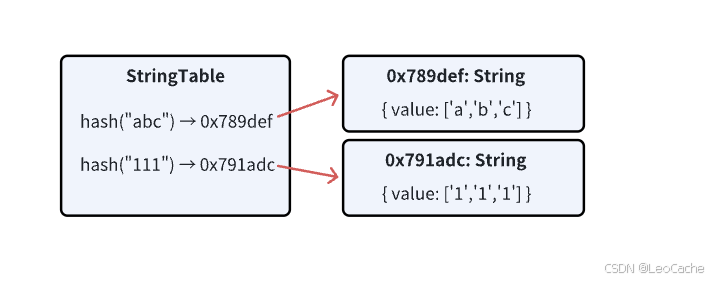
所以这个观点认为实例全部在堆上额外单独空间,而不是在字符串常量池中。
两个观点分析问题不会产生区别,其实核心还是字符串常量池的定义的范围问题。
public static void main(String[] args) {
String s = new String("a");
s.intern();
String s2 = "a";
System.out.println(s == s2); //false
}
String s = new String("a")
-
字符串字面量"a"加载:当类加载时,字符串字面量"a"会首先被放入字符串常量池。
-
堆内存新对象:
new关键字会在堆内存中创建一个全新的String对象,内容为"a"。此时s指向堆内存中的这个新对象。
s.intern()
-
常量池检查:
intern()方法会检查常量池中是否存在内容为"a"的字符串。 -
常量池已有实例:由于类加载时"a"已被放入常量池,此时直接返回常量池的引用(但这里没有接收返回值)。
-
关键点:
s的引用并未改变,仍然指向堆内存中的对象。
String s2 = "a"
-
字面量直接引用:JVM会在常量池中查找"a",找到后直接返回常量池中的引用。因此
s2指向常量池中的"a"。
s == s2比较
-
堆对象 vs 常量池对象:
s指向堆内存中的新对象,s2指向常量池中的对象,二者内存地址不同,结果为false。
public static void main(String[] args) {
String s = new String("a");
s=s.intern();
String s2 = "a";
System.out.println(s == s2); //false
}
这个和上面唯一区别是s=s.intern(),相当于s变成了常量池中的引用
public static void main(String[] args) {
String s = new String("a") + new String("b");
s.intern();
String s2 = "ab";
System.out.println(s == s2); //true
}String s = new String("a") + new String("b")
-
字符串拼接:底层通过
StringBuilder动态生成"ab",最终在堆内存中创建新的String对象(内容为"ab") -
常量池状态:此时字符串常量池中只有"a"和"b",没有"ab"
s.intern()
-
常量池检查:发现常量池中没有"ab"
-
常量池更新:将堆内存中
s对象的引用直接存入常量池(JDK7+特性) -
关键点:常量池中的"ab"与堆内存中的
s对象是同一个引用
String s2 = "ab"
-
字面量解析:JVM发现常量池已存在"ab"的引用,直接返回该引用
-
结果:
s2获得的是堆内存中s对象的引用
s == s2比较
-
相同引用:此时
s和s2都指向堆内存中的同一个对象,结果为true
参考:
https://www.zhihu.com/question/55994121/answer/147296098
https://tech.meituan.com/2014/03/06/in-depth-understanding-string-intern.html



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











