







前言
vllm是一个开源的大模型推理加速框架,通过PagedAttention高效管理attention中缓存的张量,实现了比huggingface transformers高14-24倍的吞吐量。核心优化点即:提升内存(显存)的利用效率 => GPU内存碎片化=慢(操作系统的分页思想)
Github:https://github.com/vllm-project/vllm
由于vllm需要在linux环境上才行,而博主不想再去下载vmware了,故采用wsl+docker的方式部署。
环境的部署
安装wsl和ubuntu
命令:
wsl --install --no-distribution
因为开启代理后,该终端不受影响,所以需要单独给该终端设置代理。
$env:http_proxy="http://127.0.0.1:7897"
$env:https_proxy="http://127.0.0.1:7897"
wsl --list --online
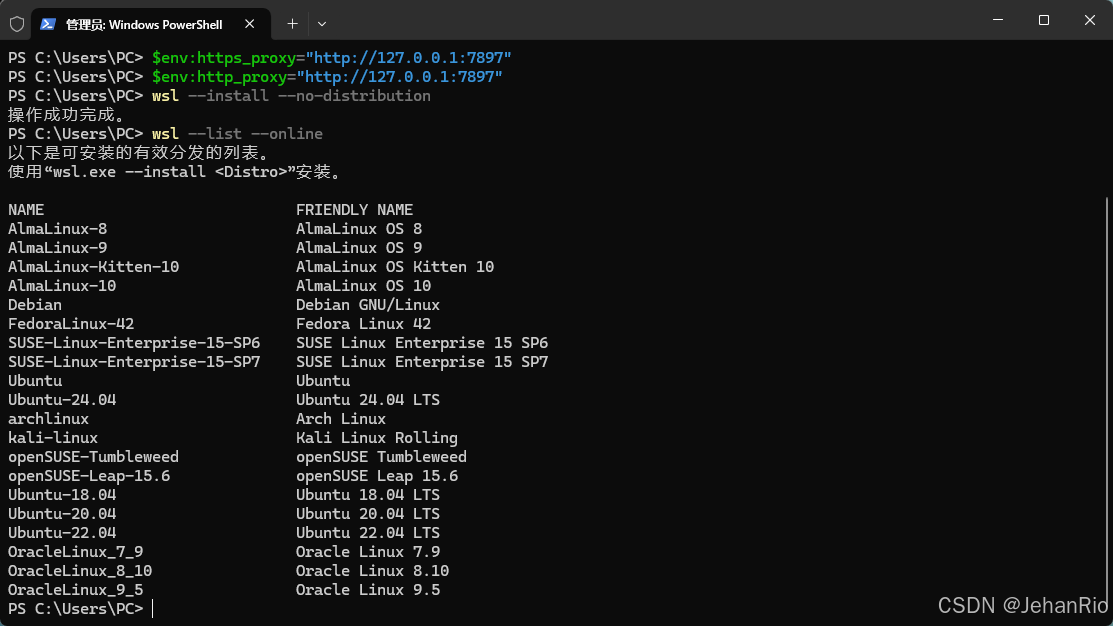
注意,本篇是用docker进行部署,所以按理说下载好wsl,再去下载docker就行了,但博主直接把ubuntu也一起安装了。如果不想安装ubuntu的,直接跳过这一步。
然后安装Ubuntu
wsl --install -d Ubuntu-24.04
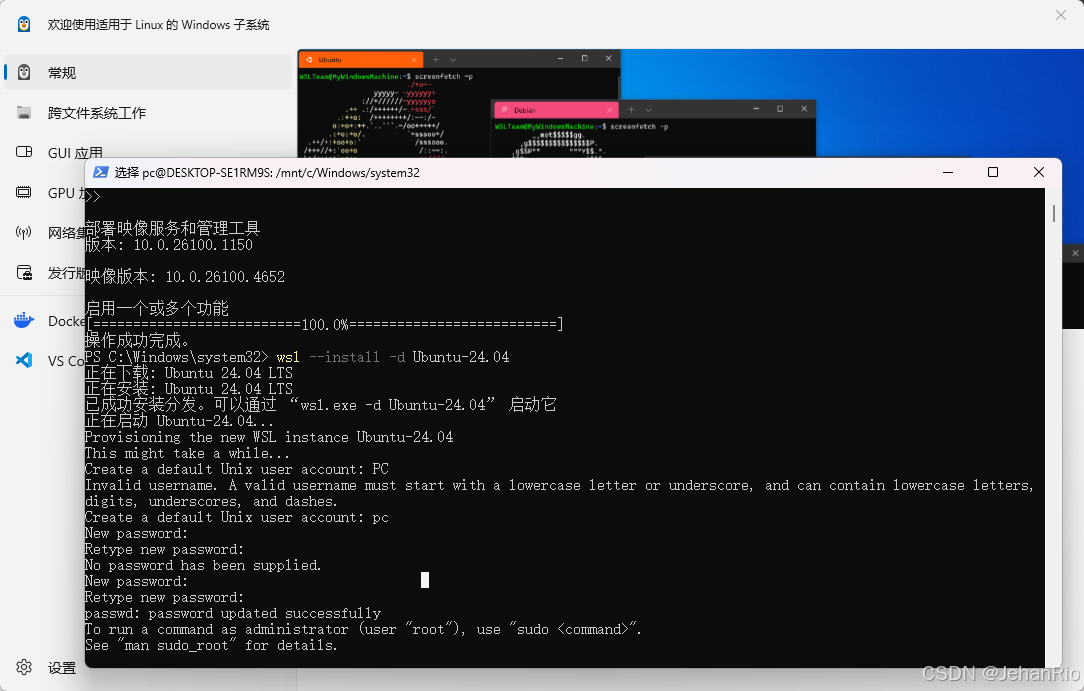
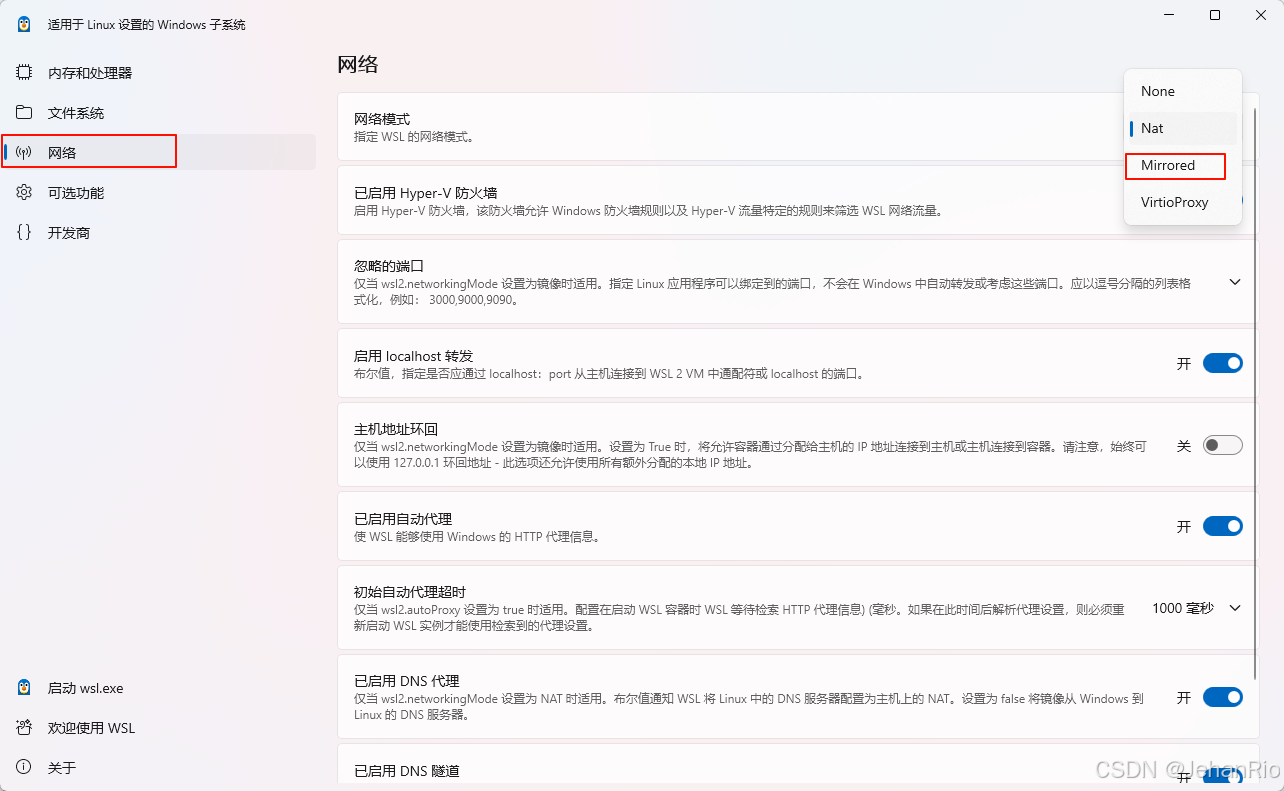
搜索WSL Setting,更改网络配置,改为Mirrored,这样WSL就会镜像继承windows的代理。
更改ubuntu安装位置
考虑到后续会无限膨胀,我打算把ubuntu迁移到别的盘。
1. 关闭系统
STATE为Stopped即说明已关闭。
wsl --shutdown
wsl -l -v
2. 创建目录
在合适的磁盘上创建一个目录
3. 导出镜像
在PowerShell中输入下列命令,将Ubuntu导出到指定目录,并等待操作完成。
wsl --export Ubuntu-24.04 D:\ubuntu24\Ubuntu2404.tar
4. 注销原系统
在wsl中注销原有的Ubuntu系统,powershell中输入wsl --unregister Ubuntu-24.04。完成后输入wsl -l -v查看,提示适用于 Linux 的 Windows 子系统没有已安装的分发。即为卸载成功。
5. 导入镜像
在powershell中输入wsl --import Ubuntu-24.04 D:\ubuntu24 D:\ubuntu24\Ubuntu2404.tar,将之前导出的镜像导入到新的Ubuntu系统。在powershell中输入wsl -l -v查看,出现Ubuntu-24.04的NAME即为导入成功。
6. 删除文件
删除导出的镜像文件Ubuntu2404.tar。
7. 启动Ubuntu子系统
在开始菜单中搜索Ubuntu并运行,出现终端界面即为成功。
docker的安装
docker的安装直接去官网安装即可,比较简单不做赘述。
https://www.docker.com/products/docker-desktop/
到此,我们所需要的基本环境就ok了,接下来就是vllm的部署了。
vllm的部署
打开terminal,拉取vllm的镜像。
docker pull vllm/vllm-openai:latest
有一说一,这个下载是真的慢。。。我换了好几个镜像源。。。而且还占我C盘空间。。。
附上镜像源链接:
"registry-mirrors": [
"https://docker.1ms.run",
"https://docker.1panel.live/"
]
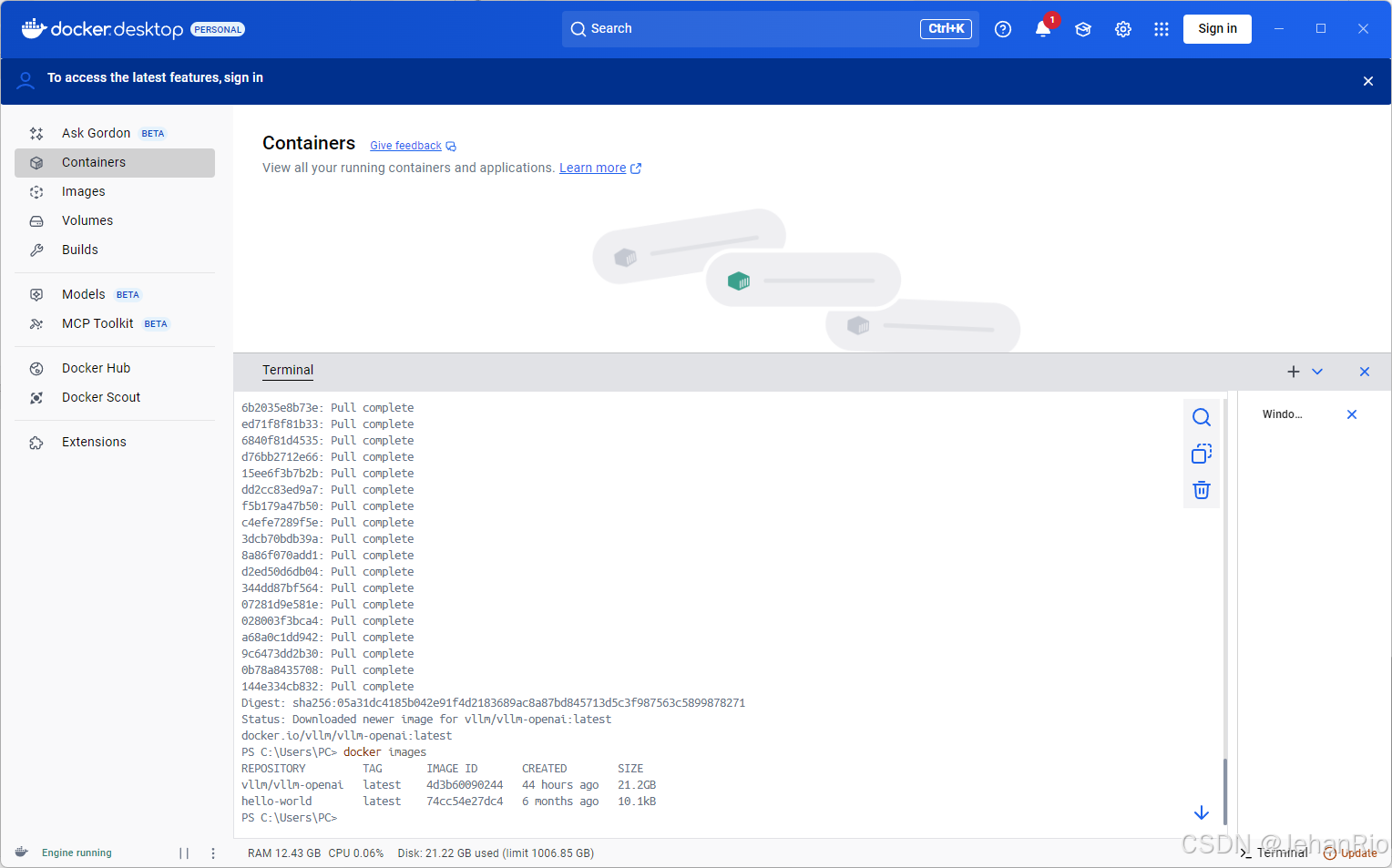
今天先到这里吧,花了一晚上拉取下来,明天进行部署。
接下来就是执行docker的命令了
docker run --gpus all
-p 8000:8000
--rm
-v "E:\AIInfra\models\Qwen\Qwen3-0.6B:/models"
vllm/vllm-openai:latest
--model /models
--host 0.0.0.0
--port 8000
--tensor-parallel-size 1
如何确认启动成功了呢,有几个方法:
- 访问链接:http://localhost:8000/docs,会有API文档
- python调用接口访问:
import requests
response = requests.post(
"http://localhost:8000/v1/completions",
json={
"model": "/models",
"prompt": "你好,你是谁?",
"max_tokens": 50
}
)
print(response.json())
另外,可以搜索日志,查看是否是用的gpu资源,比如:
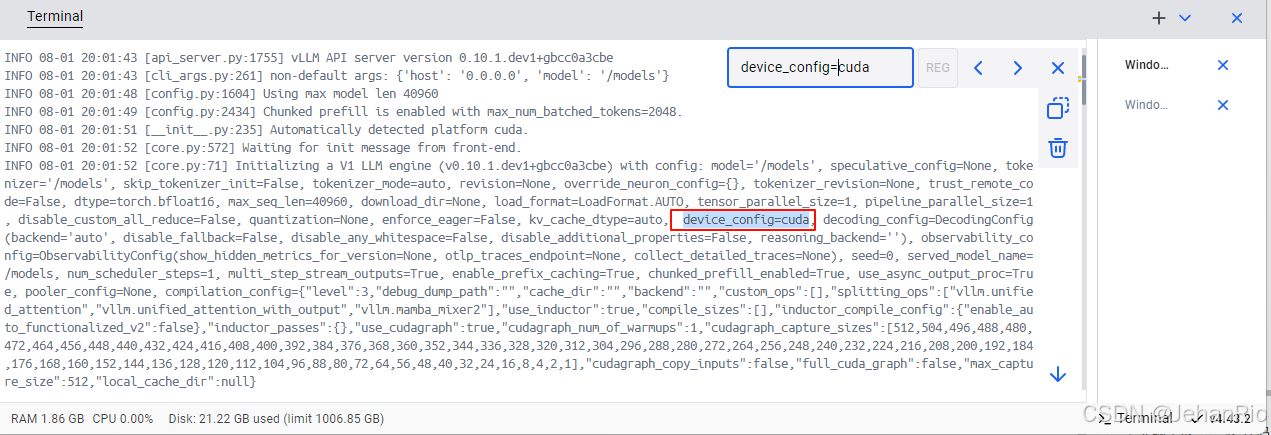
也可以在任务管理器里面,查看GPU的使用情况。
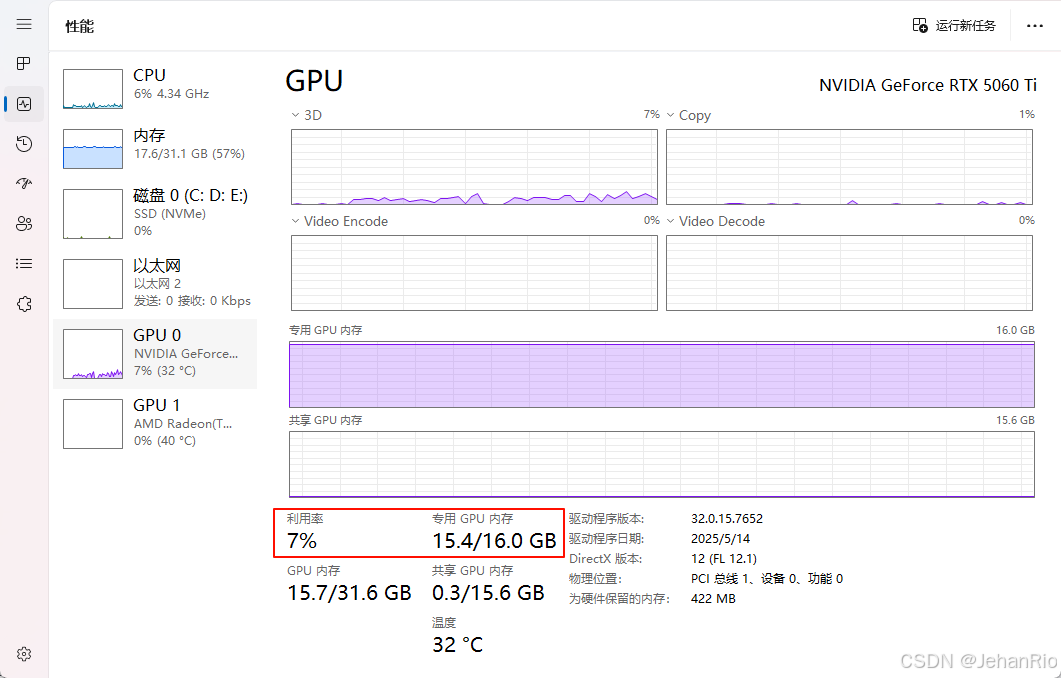
为什么GPU内存爆了
从上面图中可以看到,我的GPU内存都要爆了,这是为什么呢?通过日志观察,发现了一个参数:--gpu-memory-utilization。
首先你要知道:
✅ 1. CUDA Graphs(CUDA 图)是什么?
vLLM 为了提升推理速度,会使用 CUDA Graphs 技术来“预编译”模型的执行流程,减少 GPU 调度开销,从而提高吞吐量。
但代价是:
⚠️ 它会额外占用 1~3 GiB 的显存,用于缓存不同 sequence length 的执行图。
✅ 2. gpu_memory_utilization 是什么?
这是 vLLM 用来控制 显存利用率 的参数(默认通常是 0.9 或 0.95),表示 vLLM 最多可以使用多少比例的 GPU 显存。
如果显存是 16GB,gpu_memory_utilization=0.95 → 可用 15.2GB
vLLM 会尽可能“占满”这个额度,包括:
- 模型权重
- KV Cache
- CUDA Graph 缓存
- 工作缓冲区
👉 所以即使模型小,vLLM 也会“撑满”允许使用的显存,这是正常行为。
总结
到这里,vllm的部署就结束了。这里只用了一个最小的模型,部署起来,后续我会继续学习vllm,有更多实战,以及源码讲解。没想到居然花了我三天晚上的时间才搞定,感觉主要还是下载模型的速度太慢了。筛选了好多个镜像源都很慢。

















 82
82

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









