







锁的实现原理(Mutex和RWMutex)
sync.Mutex(互斥锁)
为什么需要锁
在高并发或多goroutine同时执行时,可能会写入同一块内存
var count int
var mu sync.Mutex
func func1(){
for i :=0;i < 1000; i++{
go func(){
count =count+1
}()
}
time.Sleep(time.Second)
fmt.Println(count)
}
输出的值预期是1000,实际是966等,多次运行结果不一致
当多个goroutine同时修改数值时,后面执行的goroutine对count的修改覆盖
- Mutex.lock()用来获取锁
- Mutex.Unlock()用于释放锁
在 Lock 和 Unlock 方法之间的代码段称为资源的临界区,这一区间的代码是严格被锁保护的,是线程安全的,任何一个时间点最多只能有一个goroutine在执行。
var count int
var mu sync.Mutex
func func1(){
for i :=0;i < 10000; i++{
go func(){
mutex.Lock()
count =count+1
mutex,Unlock
}()
}
time.Sleep(time.Second)
fmt.Println(count)
}输出结果为10000
Mutex结构体
源码包src/sync/mutex.go:Mutex定义了互斥锁的数据结构:
type Mutex struct{
state int32
sema uint32
}
- Mutex.state表示互斥锁,比如是否被锁定
- Mutex.sema表示信号量,协程阻塞等待该信号量,解锁的协程释放信号量从而唤醒等待信号量的协程
我们看到Mutex.state是32位的整型变量,内部实现时把该变量分成四份,用于记录Mutex的四种状态。
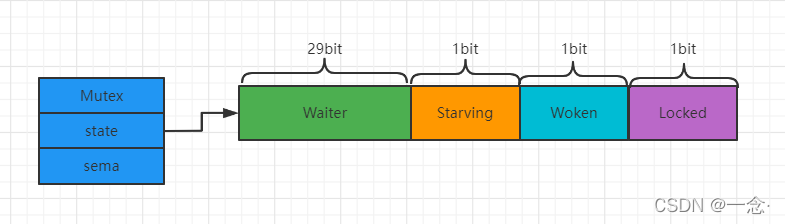
- Locked: 表示该Mutex是否已被锁定,0:没有锁定 1:已被锁定。
- Woken: 表示是否有协程已被唤醒,0:没有协程唤醒 1:已有协程唤醒,正在加锁过程中。
- Starving:表示该Mutex是否处于饥饿状态,0:没有饥饿 1:饥饿状态,说明有协程阻塞了超过1ms。
- Waiter: 表示阻塞等待锁的协程个数,协程解锁时根据此值来判断是否需要释放信号量。
协程之间抢锁实际上是抢给Locked赋值的权利,能给Locked域置1,就说明抢锁成功。抢不到的话就阻塞等待Mutex.sema信号量,一旦持有锁的协程解锁,等待的协程会依次被唤醒。
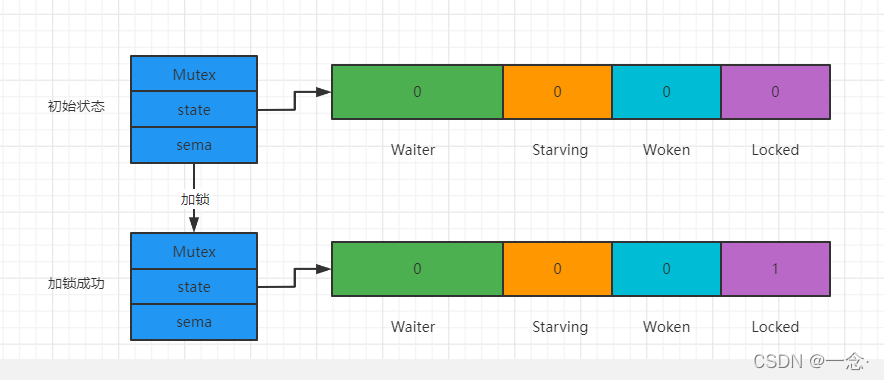
简单加锁
加锁被阻塞
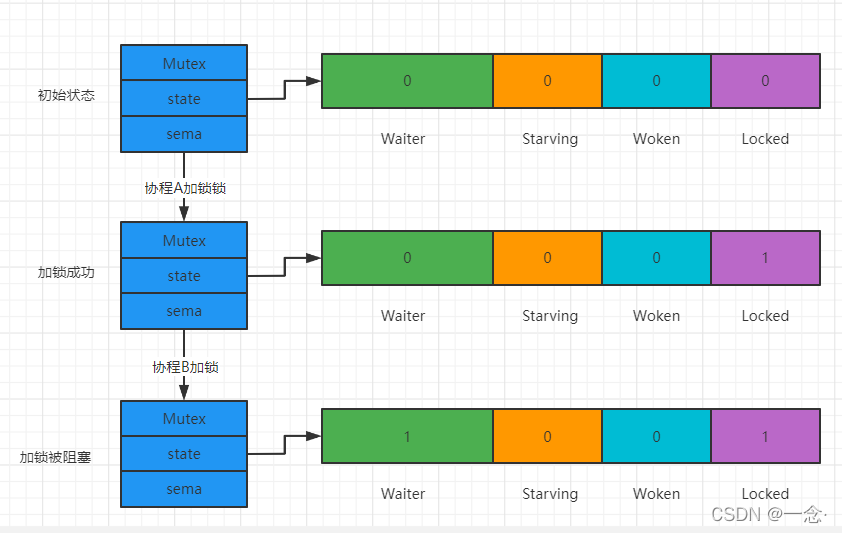
从上图可以看到,当协程B对一个已被占用的锁进行再次加锁时,Waiter计数器加1,此时协程B将被阻塞,直到Lockde值变为0后才会被唤醒
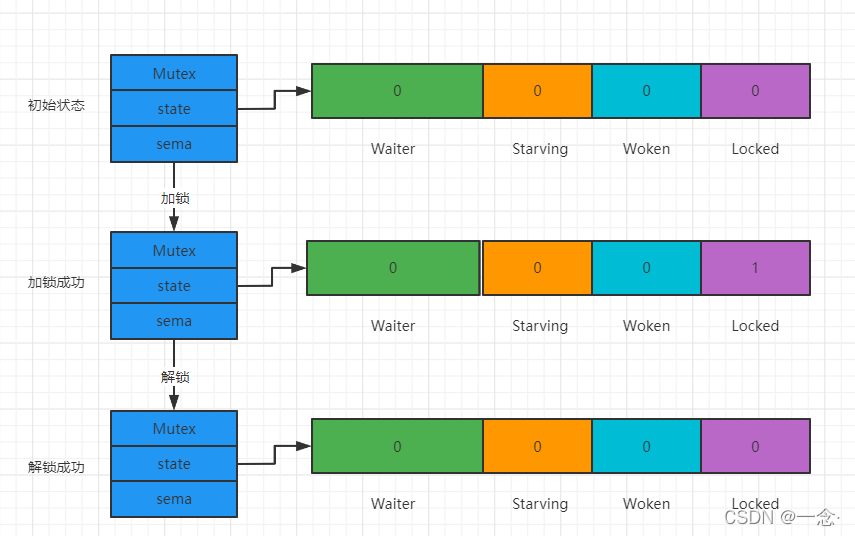
由于没有其他协程阻塞等待加锁,所以此时解锁时只需要把Locked位置为0即可,不需要释放信号量。
解锁并唤醒协程
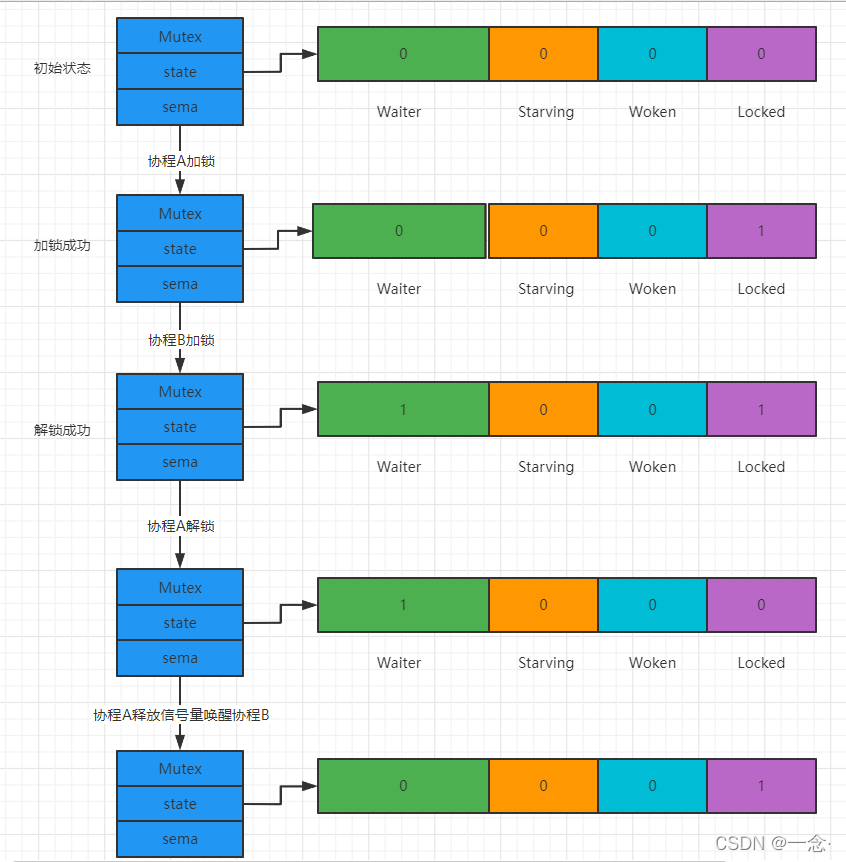
协程A解锁过程分为两个步骤,一是把Locked位置0,二是查看到Waiter>0,所以释放一个信号量,唤醒一个阻塞的协程,被唤醒的协程B把Locked位置1,于是协程B获得锁。
自选过程
加锁时,如果当前Locked位为1,说明该锁当前由其他协程持有,尝试加锁的协程并不是马上转入阻塞,而是会持续的探测Locked位是否变为0,这个过程即为自旋过程。
自旋时间很短,但如果在自旋过程中发现锁已被释放,那么协程可以立即获取锁。此时即便有协程被唤醒也无法获取锁,只能再次阻塞。
自旋的好处是,当加锁失败时不必立即转入阻塞,有一定机会获取到锁,这样可以避免协程的切换。
自选条件
- 自旋次数要足够小,通常为4,即自旋最多4次
- CPU核数要大于1,否则自旋没有意义,因为此时不可能有其他协程释放锁
- 协程调度机制中的Process数量要大于1,比如使用GOMAXPROCS()将处理器设置为1就不能启用自旋
- 协程调度机制中的可运行队列必须为空,否则会延迟协程调度
优势
自旋的优势就是更加充分的利用cpu,尽量避免协程切换。
问题
如果自旋过程中获得锁,那么之前被阻塞的协程将无法获得锁,如果加锁的协程特别多,每次都通过自旋获得锁,那么之前被阻塞的进程将很难获得锁,从而进入饥饿状态。
为了避免协程长时间无法获取锁,自1.8版本以来增加了一个状态,即Mutex的Starving状态。这个状态下不会自旋,一旦有协程释放锁,那么一定会唤醒一个协程并成功加锁。
锁的两种方式:正常模式,饥饿模式
之所以引入了饥饿模式,是为了保证goroutine获取互斥锁的公平性。所谓公平性,其实就是多个goroutine在获取锁时,goroutine获取锁的顺序,和请求锁的顺序一致,则为公平。
正常模式
-
该模式下,协程如果加锁不成功不会立即转入阻塞排队,而是判断是否满足自旋的条件,如果满足则会启动自旋过程,尝试抢锁。
-
所有阻塞在等待队列中的goroutine会按顺序进行锁获取,当唤醒一个等待队列中的goroutine时,此goroutine并不会直接获取到锁,而是会和新请求锁的goroutine竞争。 通常新请求锁的goroutine更容易获取锁,这是因为新请求锁的goroutine正在占用cpu片执行,大概率可以直接执行到获取到锁的逻辑。
饥饿模式
-
新请求锁的goroutine不会进行锁获取,而是加入到队列尾部阻塞等待获取锁。
-
处于饥饿模式下,不会启动自旋过程,也即一旦有协程释放了锁,那么一定会唤醒协程,被唤醒的协程将会成功获取锁,同时也会把等待计数减1。
饥饿模式的触发条件
- 当一个goroutine等待锁的时间超过1ms时,互斥锁会切换到饥饿模式
饥饿模式的取消条件
-
当获取到锁的这个goroutine是等待锁队列中的最后一个goroutine,互斥锁会切换到正常模式
-
当获取到锁的这个goroutine的等待时间在1ms之内,互斥锁会切换到正常模式
sync.rwmutex
类型定义
type RWMutex struct {
w Mutex //用于控制多个写锁,获得写锁首先要获取该锁,如果有一个写锁在进行,那么再到来的写锁将会阻塞于此
writerSem uint32 //写阻塞等待的信号量,最后一个读者释放锁时会释放信号量
readerSem uint32 //读阻塞的协程等待的信号量,持有写锁的协程释放锁后会释放信号量
readerCount int32 //记录读者个数
readerWait int32 //记录写阻塞时读者个数
}
接口定义
- RLock():读锁定
- RUnlock():解除读锁定
- Lock():写锁定,与Mutex完全一致
- UnLock():解除写锁定,与Mutex完全一致
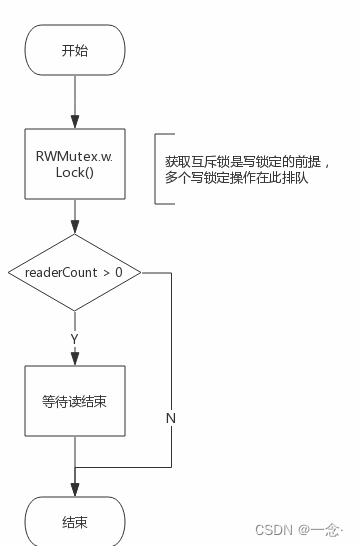
Lock()实现原理
写锁定操作需要做两件事:
- 获取互斥锁
- 阻塞等待的所有读操作结束
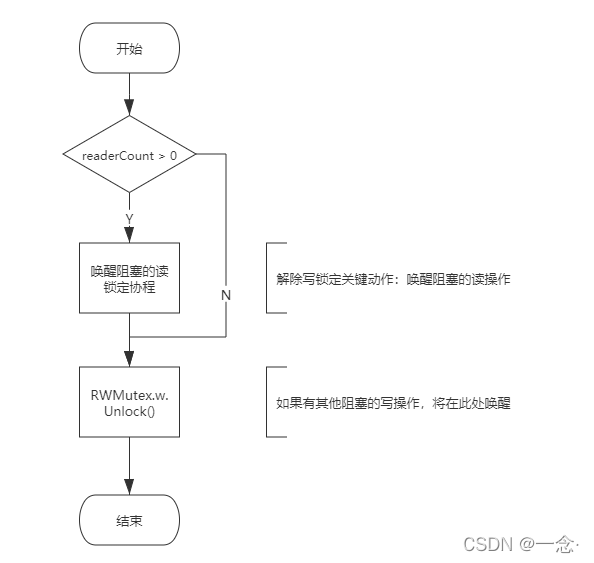
Unlock()实现原理
解除写锁定的要做的两件事:
- 唤醒因读锁定而阻塞的协程
- 解除互斥锁
RLock()实现原理
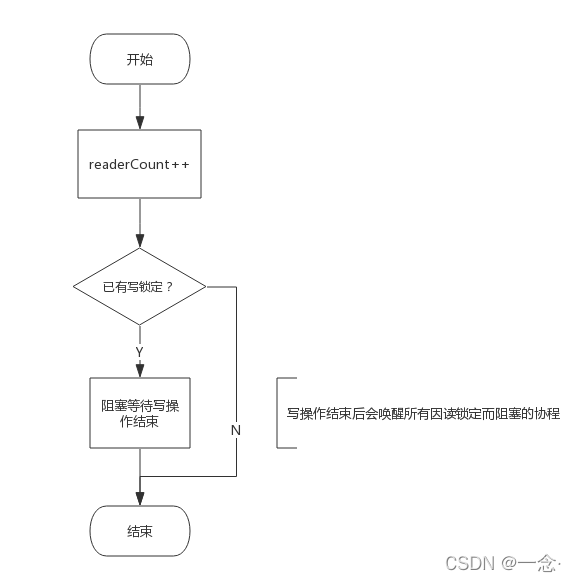
读锁定需要做两件事:
- 增加读操作计数,即readerCount++
- 阻塞等待写操作结束(如果有的话)
所以func (rw *RWMutex) RLock()接口实现流程如下图所示:
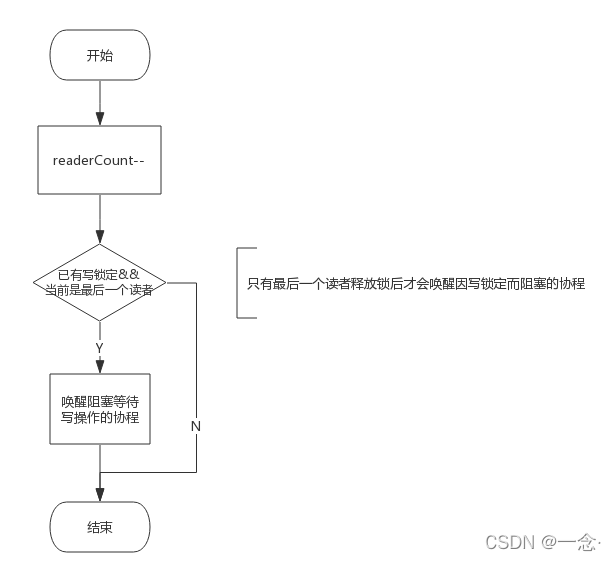
RUnlock()实现逻辑
解除读锁定需要做两件事
- 减少读操作计数,即readcount–
- 唤醒等待写操作的协程(如果有的话)
所以func (rw *RWMutex) RUnlock()接口实现流程如下图所示:
写操作如何阻塞写操作
读写锁包含一个互斥锁(Mutex),写锁定必须要先获取该互斥锁,如果互斥锁已被协程A获取(或者协程A在阻塞等待读结束),意味着协程A获取了互斥锁,那么协程B只能阻塞等待该互斥锁。所以,写操作依赖互斥锁阻止其他的写操作。
写操作如何阻塞读操作
我们知道RWMutex.readerCount是个整型值,用于表示读者数量,不考虑写操作的情况下,每次读锁定将该值+1,每次解除读锁定将该值-1,所以readerCount取值为[0, N],N为读者个数,实际上最大可支持2^30个并发读者。
当写锁定进行时,会先将readerCount减去230,从而readerCount变成了负值,此时再有读锁定到来时检测到readerCount为负值,便知道有写操作在进行,只好阻塞等待。而真实的读操作个数并不会丢失,只需要将readerCount加上230即可获得。
所以,写操作将readerCount变成负值来阻止读操作的。
读操作如何阻止写操作的
读锁定会先将RWMutext.readerCount加1,此时写操作到来时发现读者数量不为0,会阻塞等待所有读操作结束。
所以,读操作通过readerCount来将来阻止写操作的。
为什么写锁定不会被饿死
写操作到来时,会把RWMutex.readerCount值拷贝到RWMutex.readerWait中,用于标记排在写操作前面的读者个数。
前面的读操作结束后,除了会递减RWMutex.readerCount,还会递减RWMutex.readerWait值,当RWMutex.readerWait值变为0时唤醒写操作。
所以,写操作就相当于把一段连续的读操作划分成两部分,前面的读操作结束后唤醒写操作,写操作结束后唤醒后面的读操作。
饿死
写操作到来时,会把RWMutex.readerCount值拷贝到RWMutex.readerWait中,用于标记排在写操作前面的读者个数。
前面的读操作结束后,除了会递减RWMutex.readerCount,还会递减RWMutex.readerWait值,当RWMutex.readerWait值变为0时唤醒写操作。
所以,写操作就相当于把一段连续的读操作划分成两部分,前面的读操作结束后唤醒写操作,写操作结束后唤醒后面的读操作。

















 403
403

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









